Входной файл содержит текст, состоящий из произвольных ASCII-символов.
Внутри текста могут встречаться комментарии. Комментарий начинается сочетанием символов /*
и заканчивается сочетанием символов */.
Комментарии могут быть вложенными на произвольную глубину.
Требуется удалить из исходного файла все комментарии, и вывести получившийся текст.
Формат входного файла
Входной файл содержит не более 1000 строк длиной не более 256 символов каждая.
Формат выходного файла
Выходной файл должен результирующий текст. Все символы, не входящие в комментарии,
в том числе переводы строки, должны остаться неизменными.
Джон, хотя и пишет на языке С, дает файлам расширение CPP,
чтобы использовать в своих программах комментарии в С++-стиле (от // до конца строки).
Обычный С-комментарий, который начинается с символов "/*" и заканчивается символами "*/",
Джон также иногда использует, обычно для многострочных комментариев.
Для участия в конкурсе программ необходимо,
чтобы программа соответствовала стандартам языка ANSI С,
и Джону нужно заменить все C++-комментарии на стандартные.
Для этого в C++-комментарии можно заменить "//" на "/*" и добавить "*/" в конце строки.
Иногда в C++-комментарии может встретиться последовательность символов "*/",
в этом случае нужно вставить пробел между двумя этими символами: "* /".
К счастью внутри строковых констант в программе Джона не встречаются последовательностей "//", "/*" и "*/".
Напишите программу, которая преобразует в программе Джона C++-комментарии в C-комментарии.
Формат входного файла
Во входном файле содержится программа Джона.
Формат выходного файла
В выходной файл вывести программу из входного файла, изменив стиль комментариев.
Ограничения
Файл состоит из не более 100 строк длиной не более 100 символов.
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
#include <stdio.h>
/* Пример программы
*/
int main()
{ printf( //Печать
"Hello, world");
return 0; //*/*
}
#include <stdio.h>
/* Пример программы
*/
int main()
{ printf( /*Печать*/
"Hello, world");
return 0; /** /**/
}
Центральная предметно-методическая комиссия по информатике
Ограничение времени:
2 сек
Входной файл:
format.in
Ограничение памяти:
256 Мб
Выходной файл:
format.out
Условие
Многие системы форматирования текста, например TEX или Wiki, используют для разбиения текста на абзацы пустые строки.
Текст представляет собой последовательность слов, разделенных пробелами, символами перевода строк и следующими
знаками препинания: «,», «.», «?», «!», «-», «:» и «'»
(ASCII коды 44, 46, 63, 33, 45, 58, 39). Каждое слово в тексте состоит из заглавных и прописных букв
латинского алфавита и цифр. Текст может состоять из нескольких абзацев. В этом случае соседние абзацы разделяются
одной или несколькими пустыми строками. Перед первым абзацем и после последнего абзаца также могут идти одна или
несколько пустых строк.
Дальнейшее использование исходного текста предполагает его форматирование, которое осуществляется следующим образом.
Каждый абзац должен быть разбит на строки, каждая из которых имеет длину не больше W. Первая строка каждого абзаца
должна начинаться с отступа, состоящего из B пробелов. Слова внутри одной строки должны быть разделены ровно одним
пробелом. Если после слова идет один или несколько знаков препинания, они должны следовать сразу после слова без
дополнительных пробелов. Если очередное слово вместе со следующими за ним знаками препинания помещается на текущую
строку, оно размещается на текущей строке. В противном случае, с этого слова начинается новая строка. В
отформатированном тексте абзацы не должны разделяться пустыми строками. В конце строк не должно быть пробелов.
Требуется написать программу, которая по заданным числам W и B и заданному тексту выводит текст,
отформатированный описанным выше образом.
Система оценивания
Правильные решения для тестов, в которых заданный текст состоит из одного абзаца и входной файл не содержит пустых строк,
будут оцениваться из 30 баллов.
Правильные решения для тестов, в которых соседние слова разделены ровно одним пробелом и все знаки препинания следуют
сразу за словами и не отделены от них пробелами или символами перевода строк, будут оцениваться из 30 баллов.
Формат входного файла
Первая строка входного файла содержит два целых числа: W и B
Затем следует одна или более строк, содержащих заданный текст.
Формат выходного файла
Выходной файл должен содержать заданный текст, отформатированный в соответствии с приведенными в условии задачи правилами.
Ограничения
5 ≤ W ≤ 100
1 ≤ B ≤ 8
B < W
Длина слова в тексте вместе со следующими за ними знаками препинания не превышает W,
а длина первого слова любого абзаца вместе со следующими за ним знаками препинания не превышает (W − B).
Размер входного файла не превышает 100 Кбайт. Длина каждой строки во входном файле не превышает 250.
Примеры тестов
№
Входной файл (format.in)
Выходной файл (format.out)
1
20 4
Yesterday,
All my troubles seemed so far away,
Now it looks as though they're here to stay,
Oh, I believe in yesterday.
Suddenly,
I'm not half the man I used to be,
There's a shadow hanging over me,
Oh, yesterday came suddenly...
Yesterday, All
my troubles seemed
so far away, Now it
looks as though
they' re here to
stay, Oh, I believe
in yesterday.
Suddenly, I' m
not half the man I
used to be, There' s
a shadow hanging
over me, Oh,
yesterday came
suddenly...
Дана строка, состоящая из латинских букв и пробелов, содержащая по крайней мере одну букву. Словом называется последовательность из букв, не содержащая пробелов. Требуется подсчитать число слов в строке.
Формат входного файла
Входной файл содержит строку.
Формат выходного файла
В выходном файле должно содержаться единственное число - количество слов.
Гистограмма (или столбчатая диаграмма) — это способ графического изображения набора чисел,
при котором каждое число изображается прямоугольным столбцом с высотой, пропорциональной
значению числа.
По данным целым числам a1, a2, …, aN
требуется построить гистограмму. Гистограмма должна состоять из N столбцов,
i-й столбец должен изображаться прямоугольником высотой ai и шириной в 3 символа.
Столбцы должны быть:
заполнены символом '#' (ASCII 35),
ограничены сверху и снизу символами '-' (ASCII 45),
ограничены слева и справа символами '|' (ASCII 124),
ограничены по углам символами '+' (ASCII 43).
Промежуток между столбцами, а также поля слева, справа и сверху гистограммы должны составлять один символ.
В основании (нижней строке) гистограммы промежутки и поля должны изображаться символом '-' (ASCII 45),
все остальные промежутки и поля — символом '.' (ASCII 46).
Формат входного файла
Входной файл содержит число N, за которым следуют числа a1, a2, …, aN.
Формат выходного файла
Выходной файл должен содержать max(ai) + 3 строк длиной 6N + 1
символов каждая — изображение гистограммы.
Аполлинарий Матвеевич — старый, седой библиотекарь. Сегодня он в очень хорошем
настроении, потому что библиотеке подарили компьютер.
Помощники Аполлинария Матвеевича составили базу данных книг библиотеки.
Все книги, хранящиеся в библиотеке, разбиты по областям знаний, и
в каждой книге затронут ряд тем. При этом и каждая тема, и каждая
книга могут принадлежать только одной области знаний.
В базе данных хранится список областей знаний и содержится
информация о книгах, относящихся к каждой области знаний.
Кроме того, для каждой книги составлен список тем, затронутых в ней.
Однажды в библиотеку зашёл читатель. Он дал Аполлинарию Матвеевичу список тем и
попросил его подобрать книги по этим темам. Аполлинарий Матвеевич обрадовался:
у него есть база данных! Но стоп: как найти в базе данных нужную информацию?
Для этого нужна программа.
Помогите Аполлинарию Матвеевичу. Напишите программу, позволяющую определить, к каким
областям относятся заданные темы и в каких книгах можно найти информацию по этим
темам.
Формат входного файла
Первая строка входного файла содержит целое число N — количество областей знаний.
Далее для каждой области знаний входной файл содержит название области знаний,
за которым следует количество книг, относящихся к данной области знаний.
Далее для каждой книги входной файл содержит название книги, за которым
следует количество тем, затронутых в данной книге.
Далее следует список тем.
Далее входной файл содержит целое число M — количество тем в списке, подготовленном
читателем. Далее следует список тем.
Формат выходного файла
Для каждой темы требуется вывести строку "Topic: название темы".
Далее должна следовать строка "Subject: название области знаний".
Далее должна следовать строка "Books:" (без пробелов).
Далее должен следовать список книг в том порядке, в котором они
перечислены во входном файле.
Ограничения
1 ≤ N ≤ 50
1 ≤ M ≤ 10
Количество книг, относящихся к определённой области знаний, от 1 до 100.
Количество тем, затронутых в определённой книге, от 1 до 10.
Все названия во входном файле имеют длину от 1 до 50 символов и состоят из
маленьких латинских букв.
Входные данные таковы, что каждая тема из списка, подготовленного читателем,
затронута хотя бы в одной книге.
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
2
mathematics
2
algebra
3
lines
equations
coordinates
geometry
3
triangles
coordinates
lines
physics
2
mechanics
3
force
velocity
mass
gravitation
2
force
mass
5
force
triangles
velocity
coordinates
mass
Петя часто ходит в Океанариум — особенно ему там нравится один большой аквариум,
в котором плавают разнообразные маленькие рыбки.
Пете очень интересно, сколько всего рыбок в аквариуме, но часть из них всё время скрывается
за камнями и водорослями.
Поэтому каждый раз, когда Петя подходил к аквариуму, он выписывал на листок названия
всех рыбок, которые были ему видны.
Всего у Пети скопилось N таких листков. Требуется написать программу,
которая по Петиным записям определит минимально возможное количество
рыбок в аквариуме.
Например, если в первый раз Петя увидел трёх гуппи и одного вуалехвоста,
а во второй раз — четырёх вуалехвостов, то всего в аквариуме не менее 7 рыбок.
Рекомендуется рассмотреть частичные решения
N = 1,
каждый листок содержит ровно одно название рыбки.
Формат входного файла
Первая строка входного файла содержит число N.
Далее следует последовательность из N описаний листков.
В первой строке каждого описания содержится число рыбок Ki, в последующих
Ki строках — названия рыбок.
Формат выходного файла
Выходной файл должен содержать единственное число — минимальное количество рыбок.
Ограничения
1 ≤ N, Ki ≤ 50, длина названий не превосходит 255 символов.
I wish we had some way to handle it sanely, but I don't think a sane
solution to case-insensitivity exists.
Linus Torvalds
На компьютере под управлением операционной системы Linux
имеется каталог, содержащий N файлов.
Пользователю требуется скопировать эти
файлы на компьютер, работающий под управлением ОС Windows. К сожалению,
файловая система Windows имеет странное свойство. Несмотря на то, что
она сохраняет большие и малые буквы в именах файлов, имена,
отличающиеся только регистром букв, считаются одинаковыми.
Например, файлы с именами ChangeLog, CHANGELOG и changelog при копировании
на файловую систему Windows попадут в один и тот же файл.
Чтобы избежать потери данных, предлагается при копировании
переименовывать файлы по следующим правилам:
Файлы копируются в порядке перечисления в исходном каталоге.
Имена файлов считаются одинаковыми, если они совпадают с точностью до регистра.
Если при копировании очередного файла выяснилось, что
файл с таким именем уже был скопирован, то к имени текущего файла
добавляется суффикс "1".
Если имя, полученное после присоединения суффикса, также уже встречалось,
то перебираются суффиксы "2", "3", ..., "10", "11", ...
до тех пор, пока не найдётся суффикс, дающий уникальное имя.
Формат входного файла
Входной файл содержит количество имён N, за которым следует N строк с именами.
Имена состоят из латинских букв и цифр и имеют длину от 1 до M символов.
Формат выходного файла
Выходной файл должен содержать N строк с модифицированными именами файлов.
Вам предлагается отформатировать таблицу, данную во входном файле.
Формат входного файла
Первая строка входного файла содержит несколько букв l,c,r.
Их количество равно количеству столбцов в таблице. Каждая буква задает
расположение текста в соответствующем столбце (
l значит, что текст сдвинут до упора влево,
с — что текст расположен по середине,
r — что текст сдвинут вправо).
Далее следуют не менее двух и не более 100
строк данных, каждая из которых задает соответствующую строку таблицы.
Каждая строка содержит несколько записей, разделенных амперсантом ('&')
Количество записей в каждой строке равно количеству столбцов. Каждая
запись должна располагаться в соответствующем столбце.
Первая строка данных задает заголовок таблицы, а остальные — тело таблицы.
Знак '&' не содержится в ячейках таблицы.
Формат выходного файла
В выходной файл выведите таблицу в соответствии с форматом,
приведенным в примере.
Примечания:
самая длинная запись должна быть отделена от правого и левого
краев ячейки ровно одним пробелом.
если запись не может быть расположена точно посередине, то
все дополнительные пробелы появляются справа от нее.
Ограничения
длина любой строки входного файла не превышает 250 символов
When young programmer Vasya was even younger, he found a book on organic chemistry.
He did not understand a thing, but liked the pictures of structural chemical formulae
in the book and started to draw many similar ones.
Years later, while clearing his room, Vasya found his old drawings and wondered
which of them were correct. Since there were many of them, he decided to write
a program for that task.
The structural formula of a chemical compound is a graphical representation
of the molecular structure showing how the atoms are arranged.
Atoms are denoted by letters, and chemical bonds between them — by line segments.
Formula is represented in input file as a two-dimensional array of characters.
Each character may be:
'.' (ASCII 46) — empty space,
'C' — carbon atom,
'H' — hydrogen atom,
'O' — oxygen atom,
'|' (ASCII 124),
'/' (ASCII 47),
'\' (ASCII 92),
'-' (ASCII 45) — chemical bonds.
Bonds in correct formula are drawn as straight vertical,
horizontal or diagonal lines without intersections.
Atoms represented by adjacent letters are not considered bonded.
Correct formula must contain at least one atom and must be connected
(there must be a path from each atom to each other passing through bonds).
Additionally, Vasya wants to check that the number of bonds for each atom
is equal to the valency number of the corresponding chemical element.
For simplicity, he decided that number would be always equal to 4 for carbon,
2 for oxygen and 1 for hydrogen.
Input file format
First line of input file contains integers NM.
Following N lines contain M characters each — formula representation.
Output file format
Output file must contain a single string: GOOD,
if the drawing represents correct formula,
VALENCY if the formula is correct in everything except valencies,
and BAD otherwise.

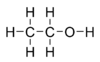 The structural formula of a chemical compound is a graphical representation
of the molecular structure showing how the atoms are arranged.
Atoms are denoted by letters, and chemical bonds between them — by line segments.
The structural formula of a chemical compound is a graphical representation
of the molecular structure showing how the atoms are arranged.
Atoms are denoted by letters, and chemical bonds between them — by line segments.