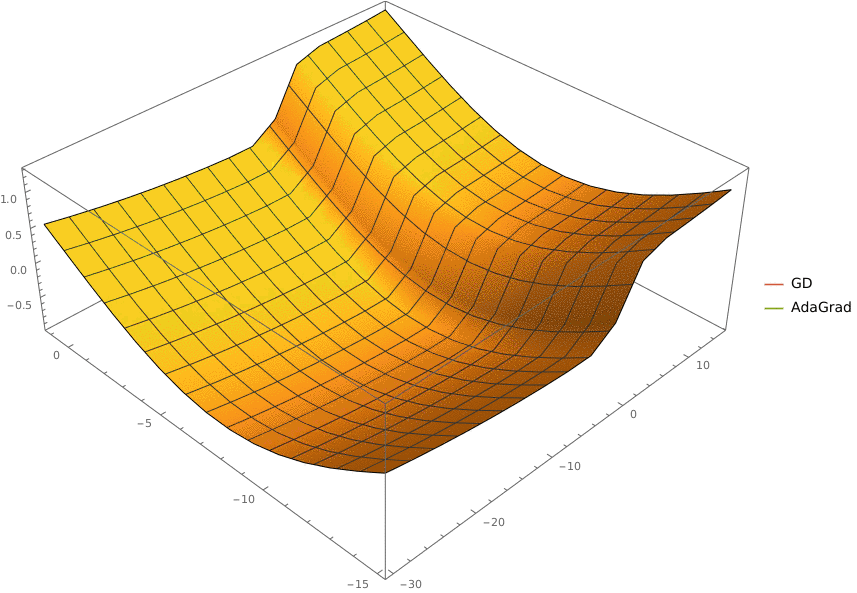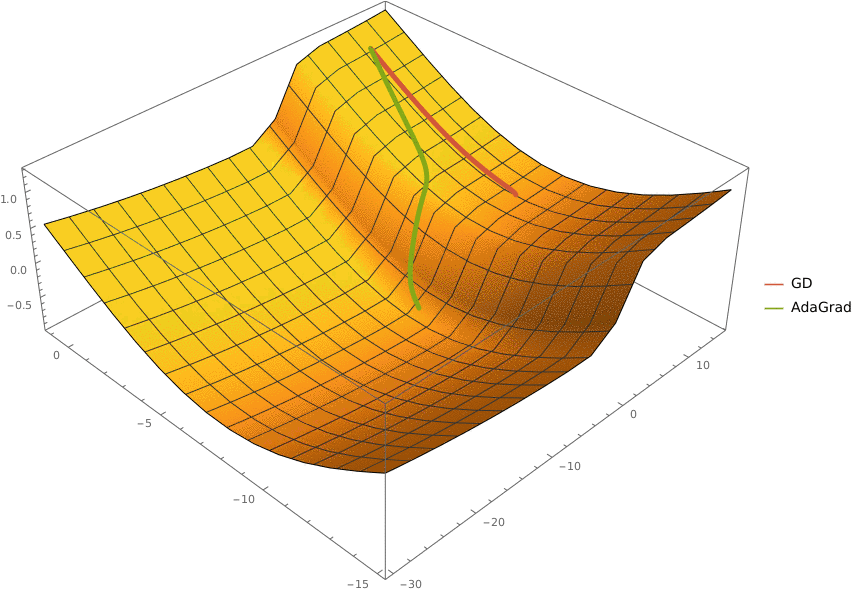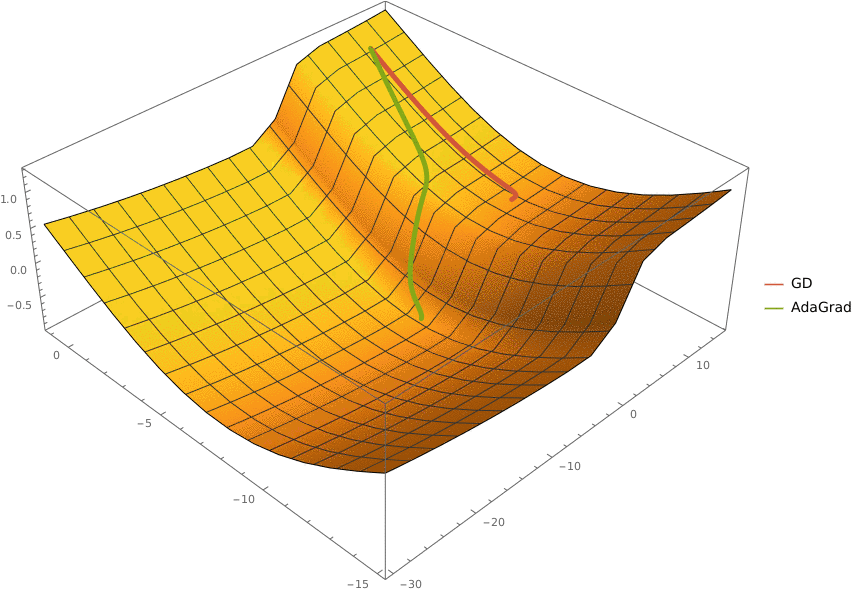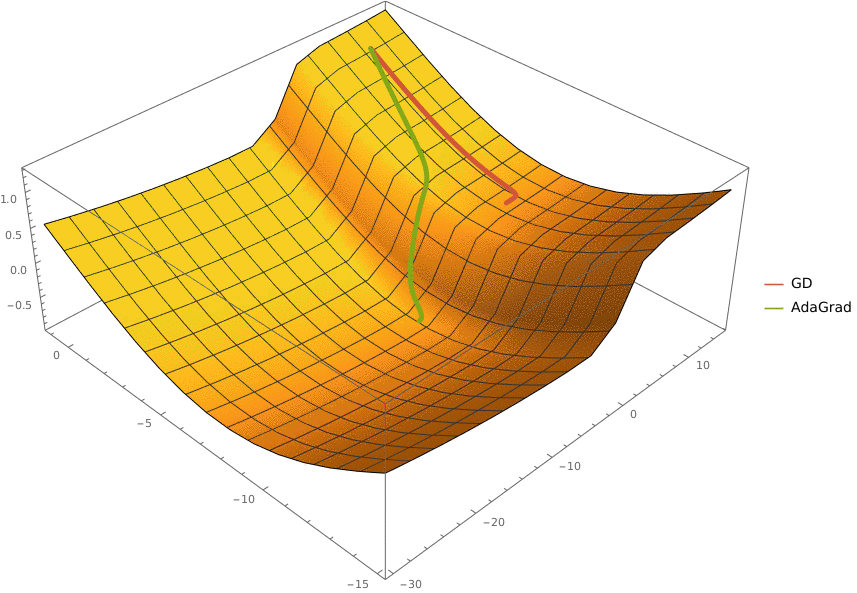
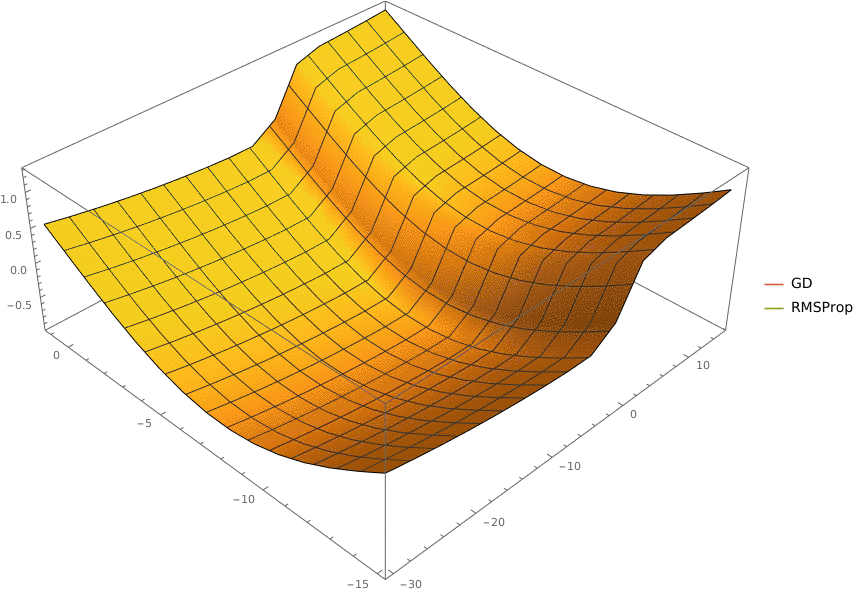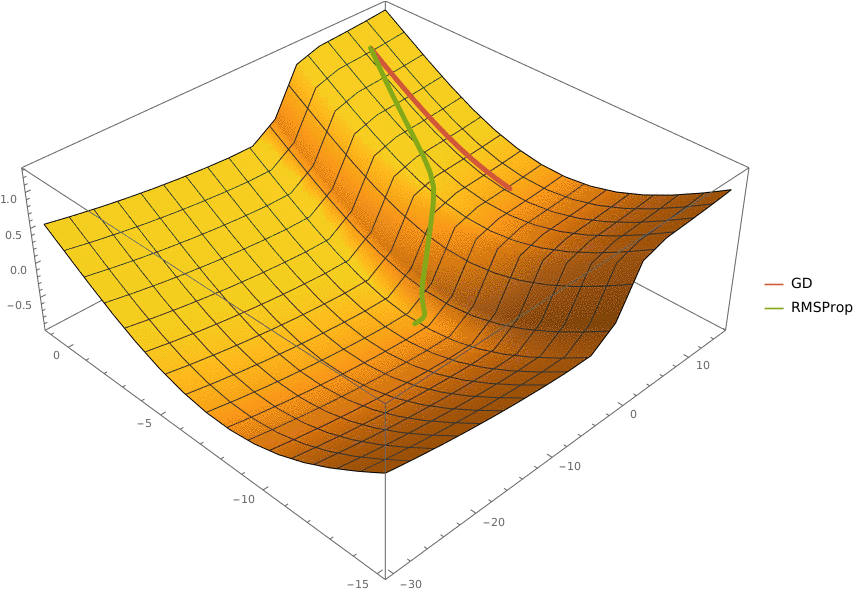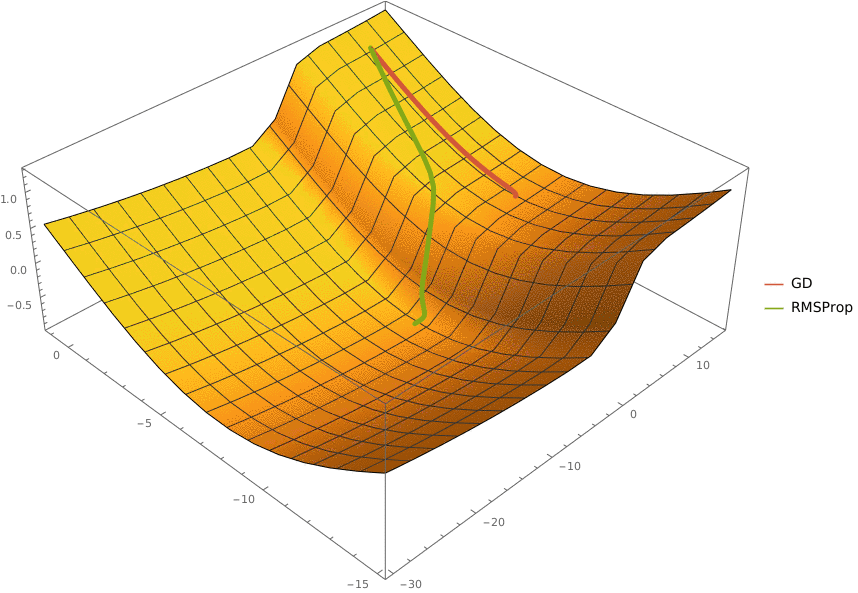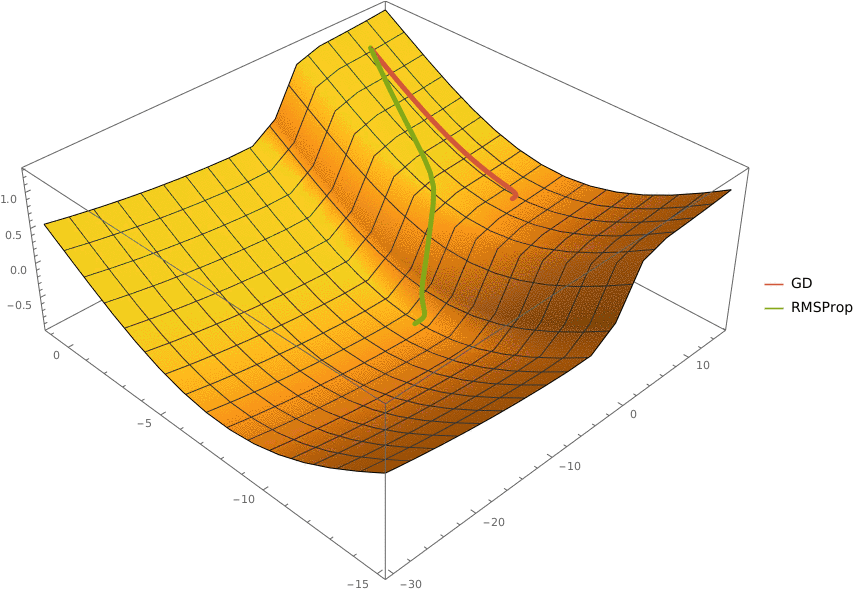
Требуется реализовать классификатор, использующий алгоритм
One Rule.
Формат входных данных
Первая строка входных данных содержит два целых числа N и K —
количество примеров в обучающей выборке и количество признаков соответственно.
Вторая строка содержит K слов, разделённых пробелом — названия признаков объектов.
Следующие N строк содержат обучающую выборку,
каждая строка содержит по K + 1 слов, первые K слов описывают значения признаков,
слово номер K + 1 содержит метку класса — 0 или 1.
Следующая строка содержит одно целое число M — количество примеров в тестовой выборке.
Далее идёт тестовая выборка, содержащая M строк по K слов.
Гарантируется, что каждое значение каждого признака встречается
в обучающей выборке хотя бы один раз.
Формат выходных данных
Выходные данные должны содержать M чисел —
результаты классификации алгоритма One Rule
после обучения на первых N примерах.
В случае если несколько признаков дают одинаковый результат на обучающей выборке, то следует выбрать тот, который встречается раньше.
Если по какому-то значению можно с одинаковой вероятностью предсказать как 0 так и 1, то следует предсказывать 1.
Ограничения
1 ≤ N, M, K ≤ 100
Суммарная длина строк не превосходит 105
Примеры тестов
№
Стандартный вход
Стандартный выход
1
10 4
Outlook Temperature Humidity Windy
overcast hot high FALSE 1
sunny mild high FALSE 0
overcast mild high TRUE 1
rainy mild normal FALSE 1
overcast hot normal FALSE 1
rainy mild high FALSE 1
rainy cool normal FALSE 1
rainy mild high TRUE 0
sunny hot high FALSE 0
sunny hot high TRUE 0
4
rainy cool normal TRUE
sunny cool normal FALSE
overcast cool normal TRUE
sunny mild normal TRUE
Имеется фиксированная неизвестная функция f(x), она одинаковая для всех тестов.
Даны значения функции f(x), f(x + 1), f(x + 2), …, f(x + N − 1).
Требуется определить значение функции f в точке x + N.
Для понимания структуры функции следует воспользоваться двумя тестами:
первый из них приведён в примере.
Второй тест можно скачать ЗДЕСЬ.
Формат входных данных
Первая строка входного файла содержит одно целое число N.
Вторая строка входного файла содержит N вещественных чисел —
значения функции f в точках x, x + 1, x + 2, …, x + N − 1.
Формат выходных данных
Выходной файл должен содержать одно число — f(x + N)
с точностью не менее двух знаков после запятой.
Требуется на языке Python реализовать функцию
get_businessmen(df: pd.DataFrame)
Функция принимает на вход объект DataFrame библиотеки
Pandas и возвращает DataFrame пользователей,
совершивших 20 и более международных звонков.
В объекте DataFrame присутствуют следующие поля:
ID — идентификатор пользователя, целое уникальное число
Total day minutes — сумма минут дневных звонков, вещественное число
Total day calls — количество дневных звонков, целое число
Total night minutes — сумма минут ночных звонков, вещественное число
Total night calls — количество ночных звонков, целое число
Total intl minutes — сумма минут международных звонков, вещественное число
Total intl calls — количество международных звонков, целое число
Customer service calls — количество обращений в техническую поддержку, целое число
Функция имеет следующий интерфейс
import pandas as pd
def get_businessmen(df: pd.DataFrame) -> pd.DataFrame:
"""
Возвращает DataFrame, оставляя в нём только пользователей из df,
совершивших 20 и более международных звонков
Параметры:
df: исходный DataFrame
Возвращаемое значение:
отфильтрованный DataFrame
"""
pass
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию функции.
Примеры тестов
№
Входной файл (data.csv)
Стандартный выход
1
# Пример вызывающего кода
import pandas as pd
df = pd.read_csv('data.csv')
businessmen = get_businessmen(df)
Требуется на языке Python реализовать функцию get_busiest_states(data: pd.DataFrame)Функция принимает на вход объект DataFrame и возвращает Series, отсортированный по убыванию, в котором штаты являются индексами, а значения — количеством международных звонков в данном штате.
Функция имеет следующий интерфейс
import pandas as pd
def get_busiest_states(data: pd.DataFrame) -> pd.Series:
"""
Вычисляет Series, в котором индексы - наименования штатов, а значение - количество совершённых международных звонов.
Параметры:
data: DataFrame с данными
Возвращаемое значение:
Series отсортированный по убыванию значений.
"""
pass
Требуется на языке Python реализовать функцию join_dataframes(users_df: pd.DataFrame, states_df: pd.DataFrame) Функция принимает на вход два объекта DataFrame и возвращает объединённый DataFrame пользователей и штатов.
import pandas as pd
def join_dataframes(data: pd.DataFrame, states: pd.DataFrame) -> pd.DataFrame:
"""
Возвращает объединённый DataFrame
Параметры:
data: DataFrame с пользователями
states: DataFrame с штатами
Возвращаемое значение:
объединённый DataFrame, содержащий поля 'Total day calls', 'Total night calls', 'State' в данном порядке
"""
pass
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию функции.
Примеры тестов
№
Входной файл (data.csv)
Стандартный выход
1
import pandas as pd
states = pd.read_csv('states.csv', index_col='ID')
data = pd.read_csv('data.csv', index_col='ID')
joined_df = join_dataframes(data, states)
Total day calls Total night calls State
ID
1 110 91 OK
2 123 103 OK
3 114 104 OK
4 71 89 OK
5 113 121 OK
6 98 118 KS
7 88 118 OH
8 79 96 NJ
9 70 12 OK
10 61 311 AL
Требуется на языке Python реализовать функцию fillna_date. Функция должна иметь следующий интерфейс:
import pandas as pd
def fillna_date(data: pd.DataFrame, function: str = 'mean') -> pd.DataFrame:
'''Fills NaN values in every column in `data` with values obtained by applying aggregate `function` over a month.
If every value within a month is NaN the fill value is obtained over a year.
If every value within a year is NaN the fill value is obtained over the whole column.
Arguments:
data: a pandas DataFrame, with datetime index
function: aggregate function to be used for obtaining fill value.
Possible values are: "mean", "median", "max", "min"
Returns:
a new pandas DataFrame with NaN values replaced
'''
pass
Датафреймdata содержит несколько вещественнозначных колонок, индексируемых объектами типа datetime. Функция fillna_date заменяет значения NaN в каждом столбце датафреймаdata на значение, полученное путём применения функции агрегации function внутри соответствующего месяца. Если все значения в этом месяцы равны NaN, новое значение получается из соответствующего года. Если же и все значения в году равны NaN, значение получается из всего столбца. Гарантируется, что в каждом столбце хотя бы одно значение не равно NaN.
Допустимыми значениями параметра function являются строки: "mean", "median", "max", "min".
При решении задачи запрещено применять операторы циклов и условий языка Python для обработки датафрейма.
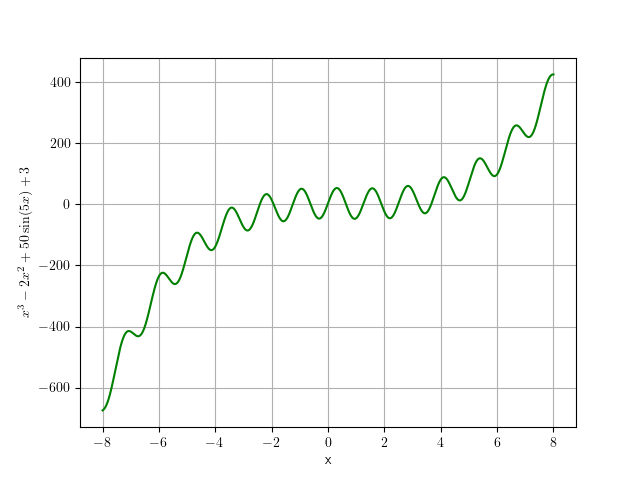
Функция принимает на вход объект pyplot и массив координат на оси абсцисс x.
Функция должна нарисовать график x3 − 2x2 + 50sin(5x) + 3 в указанных точках.
График должен быть нарисован зелёным цветом 'green' и содержать координатную сетку. Оси должны быть подписаны, выражение для оси ординат должно быть выражением на языке LaTeX, таким же, как в тексте задачи, в inline режиме отображения математических выражений $...$.
Формат выходного файла
Код решения должен содержать только реализацию функции.
Код НЕ должен самостоятельно сохранять изображение в файл или выводить изображение на экран.
Требуется реализовать на языке Python функцию, отображающую оценку плотности распределения столбца данных. Функция должна иметь следующий интерфейс
import pandas as pd
from typing import Union
def draw_pdf(data: pd.DataFrame, column: str, bins: Union[int, str] = 10) -> None:
"""
Отображает оценку плотности распределения столбца данных
Параметры:
data: таблица данных.
column: название столбца для отображения.
bins: спецификация интервалов разбиения, аналогично matplotlib.pyplot.hist.
"""
pass
Стиль оформления графика (цвета, границы, толщину линий, подписи и т.п.) должен соответствовать представленному ниже. Границы значений оси абсцисс должны быть равны минимальному и максимальному значению отображаемого столбца.
Формат выходного файла
Код решения должен содержать только реализацию функции и импортируемые модули.
Код НЕ должен самостоятельно создавать фигуры или сохранять изображение в файл.
Требуется реализовать на языке Python функцию, отображающую долю целевых значений при каждом уникальном значении категориального признака. Функция должна иметь следующий интерфейс
import pandas as pd
def draw_bars(data: pd.DataFrame, column: str, target_column: str) -> None:
"""
Отображает долю целевых значений `target_column` при каждом уникальном значении категориального признака `column` в виде слолбчатой диаграммы.
Параметры:
data: таблица данных.
column: название категориального признака.
target_column: название целевой переменной.
"""
pass
Стиль оформления графика (цвета, границы, подписи, ширина колонок и т.п.) должен соответствовать представленному ниже. Цвета столбцов должны быть получены из палитры tab10. Вклад долей менее 5% не должен быть подписан на графике.
Формат выходного файла
Код решения должен содержать только реализацию функции и импортируемые модули.
Код НЕ должен самостоятельно создавать фигуры или сохранять изображение в файл.
В конструктор принимаются два аргумента —
оракул, с помощью которого можно получить градиент оптимизируемой функции,
а также точку, с которой необходимо начать градиентный спуск.
Метод optimize принимает максимальное число итераций для критерия остановки,
L2-норму градиента, которую можно считать оптимальной,
а также learning rate. Метод возвращает оптимальную точку.
Оракул имеет следующий интерфейс:
class Oracle:
def get_func(self, x): pass
def get_grad(self, x): pass
x имеет тип np.array вещественных чисел.
Формат выходных данных
Код должен содержать только класс и его реализацию. Он не должен
ничего выводить на экран.
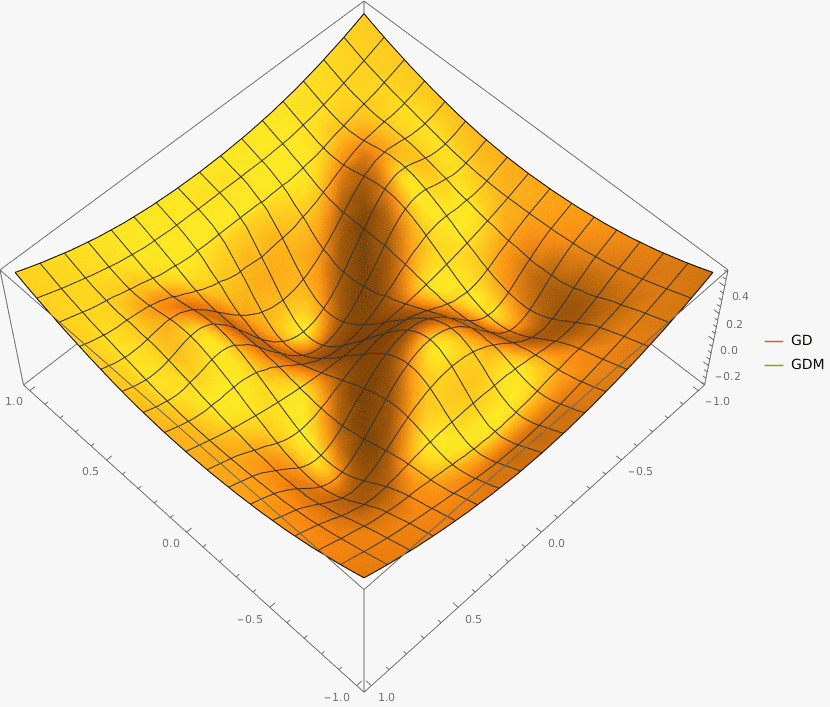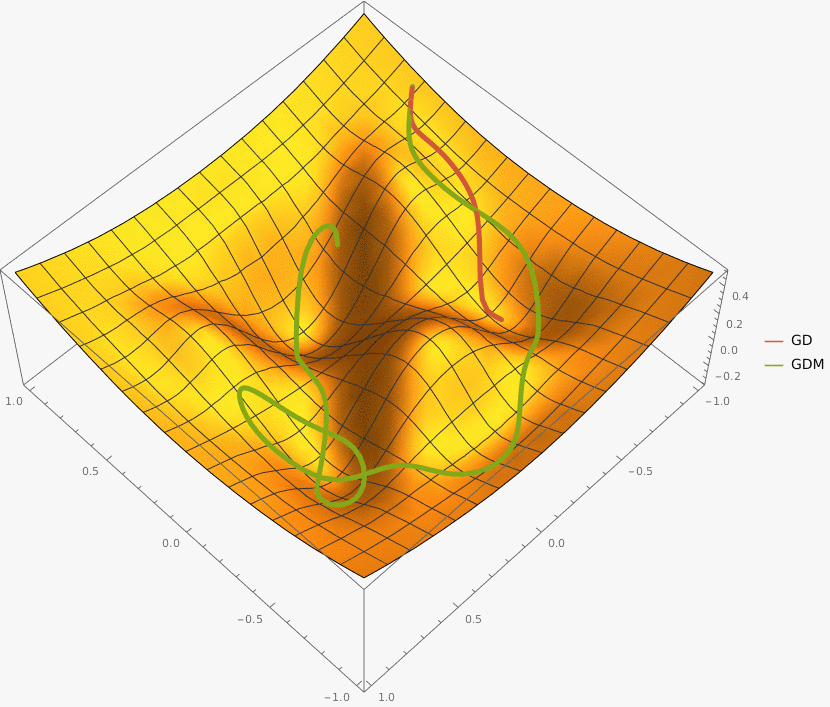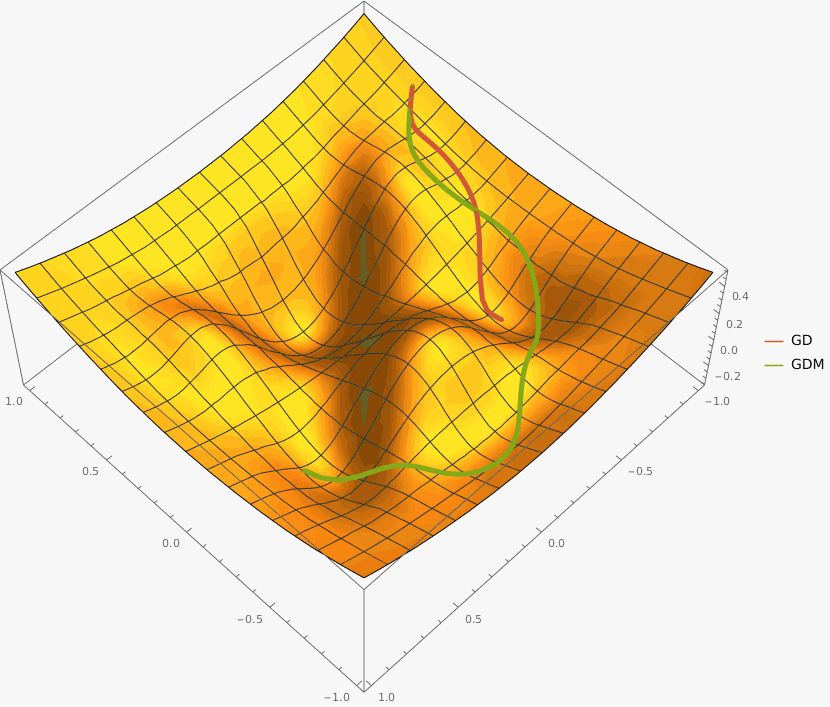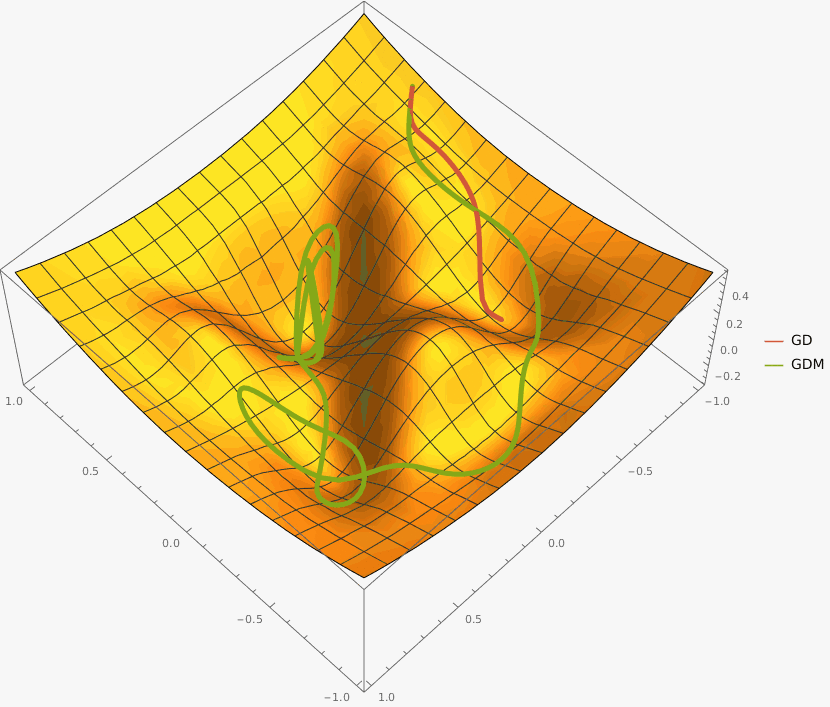
Требуется реализовать на языке Python класс GDM, который описывает алгоритм градиентного спуска с моментом и имеет следующий интерфейс:
import numpy as np
class GDM:
'''Represents a Gradient Descent with Momentum optimizer
Fields:
eta: learning rate
alpha: exponential decay factor
'''
eta: float
alpha: float
def __init__(self, *, alpha: float = 0.9, eta: float = 0.1):
'''Initalizes `eta` and `alpha` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
alpha — скорость затухания момента,
eta — learning rate.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию:
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
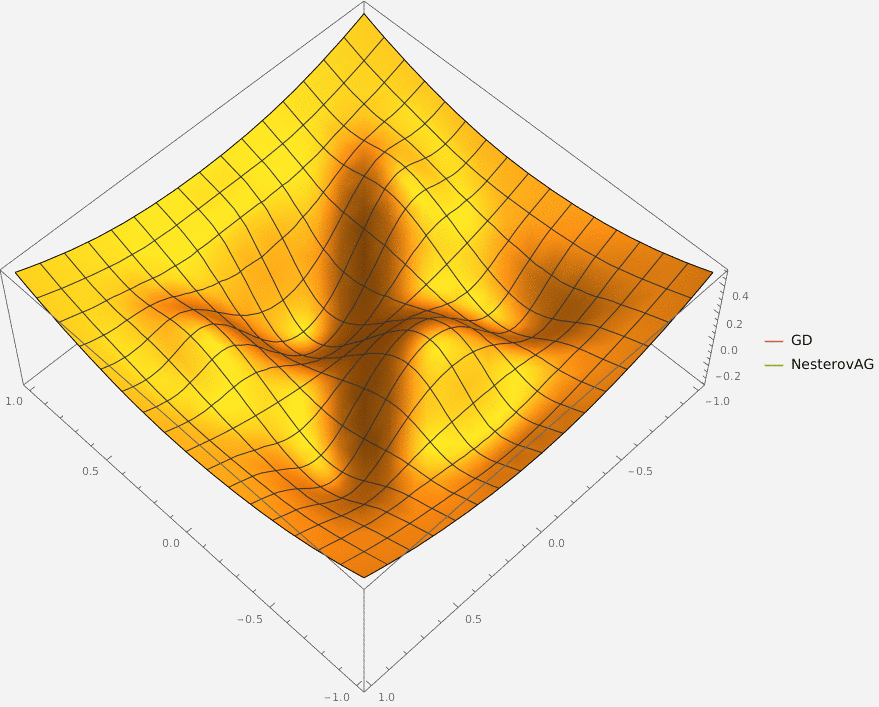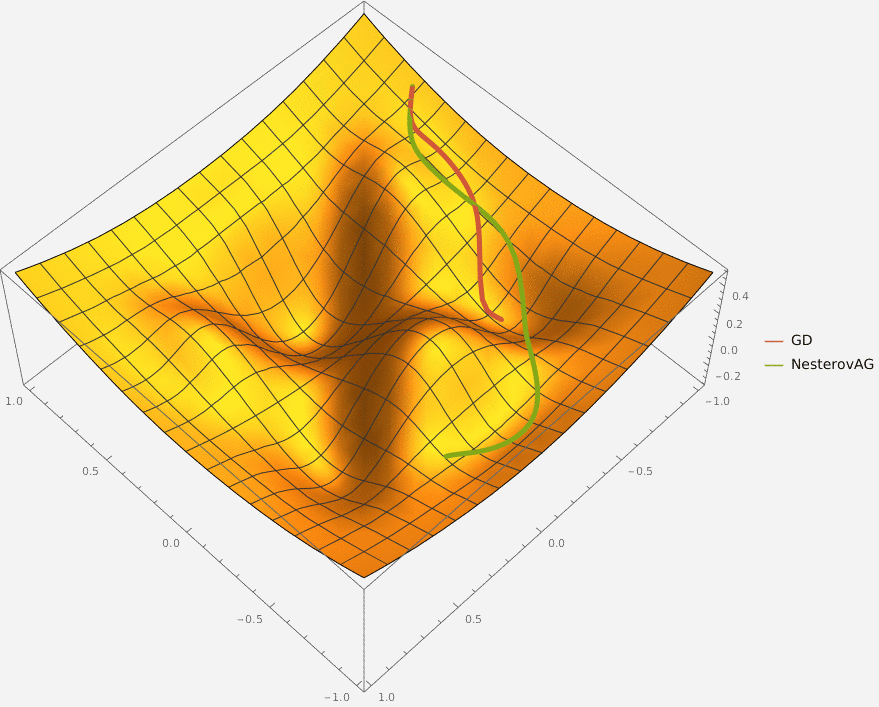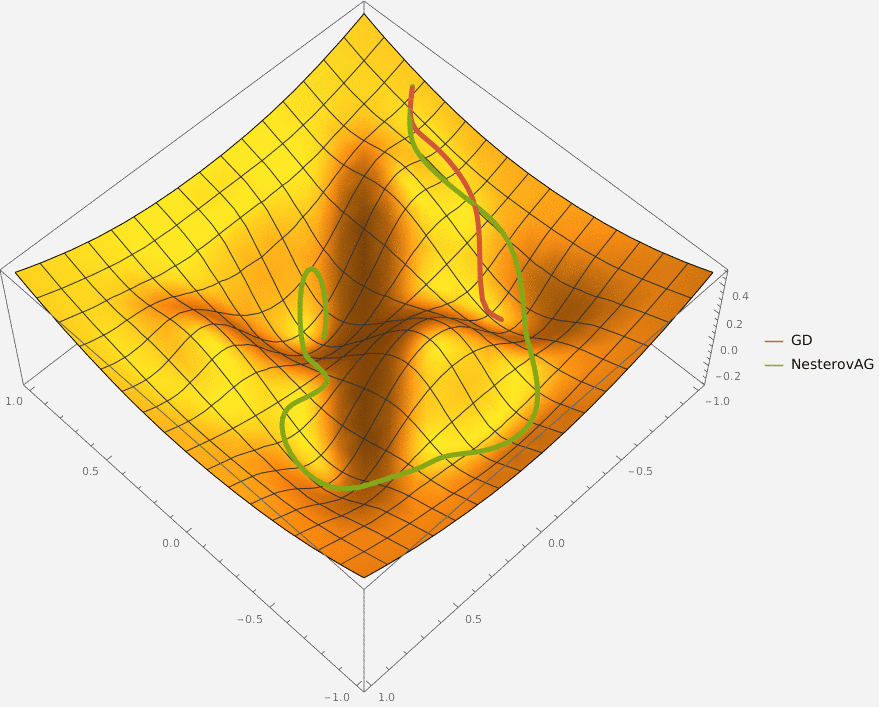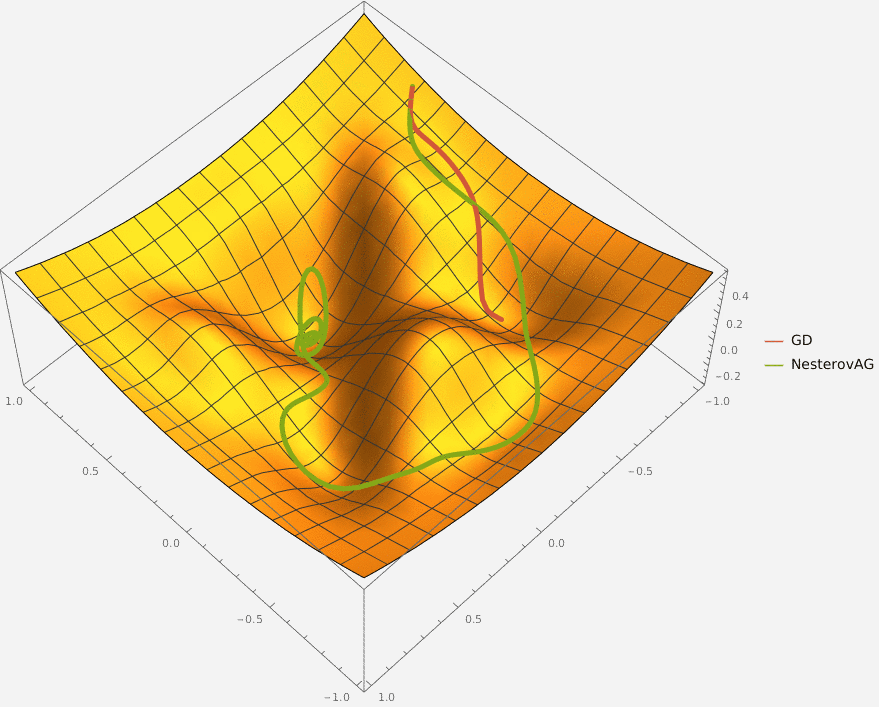
Требуется реализовать на языке Python класс NesterovAG, который описывает алгоритм ускоренного градиента Нестерова и имеет следующий интерфейс
import numpy as np
class NesterovAG:
'''Represents a Nesterov Accelerated Gradient optimizer
Fields:
eta: learning rate
alpha: exponential decay factor
'''
eta: float
alpha: float
def __init__(self, *, alpha: float = 0.9, eta: float = 0.1):
'''Initalizes `eta` and `aplha` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the current gradient is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
alpha — скорость затухания момента,
eta — learning rate.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс AdaGrad, который описывает алгоритм адаптивного градиентного спуска и имеет следующий интерфейс
import numpy as np
class AdaGrad:
'''Represents an AdaGrad optimizer
Fields:
eta: learning rate
epsilon: smoothing term
'''
eta: float
epsilon: float
def __init__(self, *, eta: float = 0.1, epsilon: float = 1e-8):
'''Initalizes `eta` and `epsilon` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс RMSProp, который описывает одноименный алгоритм и имеет следующий интерфейс
import numpy as np
class RMSProp:
'''Represents an RMSProp optimizer
Fields:
eta: learning rate
gamma: exponential decay factor
epsilon: smoothing term
'''
eta: float
gamma: float
epsilon: float
def __init__(self, *, eta: float = 0.1, gamma: float = 0.9, epsilon: float = 1e-8):
'''Initalizes `eta`, `gamma` and `epsilon` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
gamma — коэффициент затухания,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс Adam, который описывает одноименный алгоритм и имеет следующий интерфейс
import numpy as np
class Adam:
'''Represents an Adam optimizer
Fields:
eta: learning rate
beta1: first moment decay rate
beta2: second moment decay rate
epsilon: smoothing term
'''
eta: float
beta1: float
beta2: float
epsilon: float
def __init__(self, *, eta: float = 0.1, beta1: float = 0.9, beta2: float = 0.999, epsilon: float = 1e-8):
'''Initalizes `eta`, `beta1` and `beta2` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
beta1 — коэффициент затухания первого момента,
beta2 — коэффициент затухания второго момента,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать следующие функции на языке Python.
def linear_func(theta, x) # function value
def linear_func_all(theta, X) # 1-d np.array of function values of all rows of the matrix X
def mean_squared_error(theta, X, y) # MSE value of current regression
def grad_mean_squared_error(theta, X, y) # 1-d array of gradient by theta
theta — одномерный np.array
x — одномерный np.array
X — двумерный np.array. Каждая строка соответствует по размерности вектору theta
y — реальные значения предсказываемой величины
Матрица X имеет размер M × N. M строк и N столбцов.
Используется линейная функция вида: hθ(x) = θ1x1 + θ2x2 + ... + θnxN
Mean squared error (MSE) как функция от θ: J(θ) = 1MM∑i = 1(yi − hθ(x(i)))2. Где x(i) — i-я строка матрицы X
Пусть имеется задача регрессии f(x) = a⋅ x + b ≈ y. Требуется найти коэффициенты регрессии a, такие, что |{ai | ai∈ a, ai = 0}| = k, 0 < k ⩽ |a| = m. При этом должно выполняться условие R2 = 1 − n∑i = 1(yi − f(Xi))2n∑i = 1(yi − y)2⩾ s. При решении задачи предполагается использование алгоритма Lasso.
Формат входных данных
Данные для обучения содержатся в файле. Качество модели будет рассчитано на скрытом наборе данных
Первая строка входных данных содержит натуральное число N — количество тестов. В следующих N блоках содержится описание тестов. Первая строка блока содержит целые числа n — количество примеров обучающей выборки, m — размерность пространства, k — необходимое количество нулевых коэффициентов, и вещественное число s — минимальное значение метрики R2. Следующие n строк содержат по m + 1 вещественному числу — координаты точки пространства и значение целевой переменной y.
Формат выходных данных
Решение должно представлять собой текстовый файл содержащий N строк — коэффициенты a и b линейной регрессии разделённые символом пробел.
Билет состоит из 3 вопросов,
каждый из которых выбирается независимо и случайно из следующих списков:
Вопрос 1
Основные термины и задачи машинного обучения.Признаки, их виды и свойства. Переход между категориальными и численными признаками.Функция потерь. Оптимизация.Ошибки первого и второго рода. Метрики качества: accuracy, precision, recall, F1-score.Случайный поиск. Перебор по сетке.Проблемы работы с данными высокой размерности.
Вопрос 2
Производная, частные производные, градиент. Методы оценки градиента.Градиентный спуск, проблема выбора шага.Стохастический градиентный спуск.Использование момента. Метод Нестерова.Метод отжига.Adagrad, Adadelta.RMSProp, Adam.По выбору студента: один из: AMSGrad, AdamW, YellowFin, AggMo, Quasi-Hyperbolic Momentum, Demon.*
Вопрос 3
Постановка задачи линейной регрессии. Вероятностная интерпретация.Метод наименьших квадратов. Алгебраическое и оптимизационное решения.Ковариация, корреляция.Коэффициент деретминации (критерий R2).Анализ остатков. Гомоскедастичность. Квартет Анскомба.Решение для неквадратных и плохо обусловненных матриц.Регуляризация LASSO, Ridge, Elastic.По выбору студента, одно из: Обобщённые аддитивные модели (generalized additive models)*; Partial Least Squares*.
Экзамен проводится очно. В случае невозможности очного присутствия необходимо заранее
договориться с преподавателем о дистанционной сдаче.
После взятия билета студент готовится в ответу.
При подготовке можно использовать произвольные материалы и доступ в Интернет.
В результате подготовки к должен появиться написанный от руки
документ объёмом не более 2 страниц A4.
Во время ответа можно пользоваться только этим документом.
В документе должны быть указаны синтаксические конструкции, формулы, теоремы и прочий материал,
необходимый для ответа. Ответ состоит из устного доклада студента, длиной не более 2-3 минут
на каждый вопрос.
Полный текст доклада записывать НЕ нужно.
В докладе необходимо максимально кратко упомянуть все важные элементы доставшейся темы/вопроса.
После доклада преподаватель задаёт несколько уточняющих вопросов.
Оценка за каждый вопрос — от 0 до 5 баллов.
Студент, полностью правильно ответивший в рамках учебного плана данного курса, получает 4 балла за вопрос.
Оценка 5 баллов выставляется за выдающийся ответ, превосходящий требования учебного плана.