Требуется реализовать классификатор, использующий алгоритм
One Rule.
Формат входных данных
Первая строка входных данных содержит два целых числа N и K —
количество примеров в обучающей выборке и количество признаков соответственно.
Вторая строка содержит K слов, разделённых пробелом — названия признаков объектов.
Следующие N строк содержат обучающую выборку,
каждая строка содержит по K + 1 слов, первые K слов описывают значения признаков,
слово номер K + 1 содержит метку класса — 0 или 1.
Следующая строка содержит одно целое число M — количество примеров в тестовой выборке.
Далее идёт тестовая выборка, содержащая M строк по K слов.
Гарантируется, что каждое значение каждого признака встречается
в обучающей выборке хотя бы один раз.
Формат выходных данных
Выходные данные должны содержать M чисел —
результаты классификации алгоритма One Rule
после обучения на первых N примерах.
В случае если несколько признаков дают одинаковый результат на обучающей выборке, то следует выбрать тот, который встречается раньше.
Если по какому-то значению можно с одинаковой вероятностью предсказать как 0 так и 1, то следует предсказывать 1.
Ограничения
1 ≤ N, M, K ≤ 100
Суммарная длина строк не превосходит 105
Примеры тестов
№
Стандартный вход
Стандартный выход
1
10 4
Outlook Temperature Humidity Windy
overcast hot high FALSE 1
sunny mild high FALSE 0
overcast mild high TRUE 1
rainy mild normal FALSE 1
overcast hot normal FALSE 1
rainy mild high FALSE 1
rainy cool normal FALSE 1
rainy mild high TRUE 0
sunny hot high FALSE 0
sunny hot high TRUE 0
4
rainy cool normal TRUE
sunny cool normal FALSE
overcast cool normal TRUE
sunny mild normal TRUE
Имеется фиксированная неизвестная функция f(x), она одинаковая для всех тестов.
Даны значения функции f(x), f(x + 1), f(x + 2), …, f(x + N − 1).
Требуется определить значение функции f в точке x + N.
Для понимания структуры функции следует воспользоваться двумя тестами:
первый из них приведён в примере.
Второй тест можно скачать ЗДЕСЬ.
Формат входных данных
Первая строка входного файла содержит одно целое число N.
Вторая строка входного файла содержит N вещественных чисел —
значения функции f в точках x, x + 1, x + 2, …, x + N − 1.
Формат выходных данных
Выходной файл должен содержать одно число — f(x + N)
с точностью не менее двух знаков после запятой.
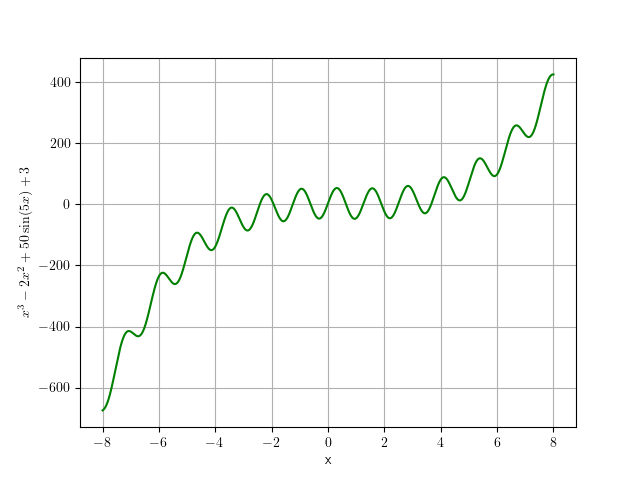
Функция принимает на вход объект pyplot и массив координат на оси абсцисс x.
Функция должна нарисовать график x3 − 2x2 + 50sin(5x) + 3 в указанных точках.
График должен быть нарисован зелёным цветом 'green' и содержать координатную сетку. Оси должны быть подписаны, выражение для оси ординат должно быть выражением на языке LaTeX, таким же, как в тексте задачи, в inline режиме отображения математических выражений $...$.
Формат выходного файла
Код решения должен содержать только реализацию функции.
Код НЕ должен самостоятельно сохранять изображение в файл или выводить изображение на экран.
В конструктор принимаются два аргумента —
оракул, с помощью которого можно получить градиент оптимизируемой функции,
а также точку, с которой необходимо начать градиентный спуск.
Метод optimize принимает максимальное число итераций для критерия остановки,
L2-норму градиента, которую можно считать оптимальной,
а также learning rate. Метод возвращает оптимальную точку.
Оракул имеет следующий интерфейс:
class Oracle:
def get_func(self, x): pass
def get_grad(self, x): pass
x имеет тип np.array вещественных чисел.
Формат выходных данных
Код должен содержать только класс и его реализацию. Он не должен
ничего выводить на экран.
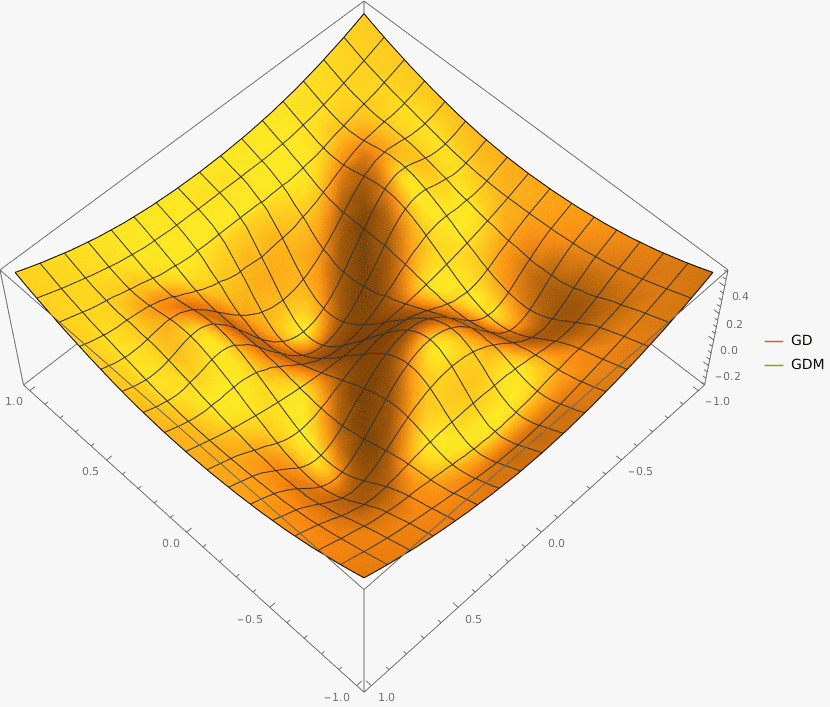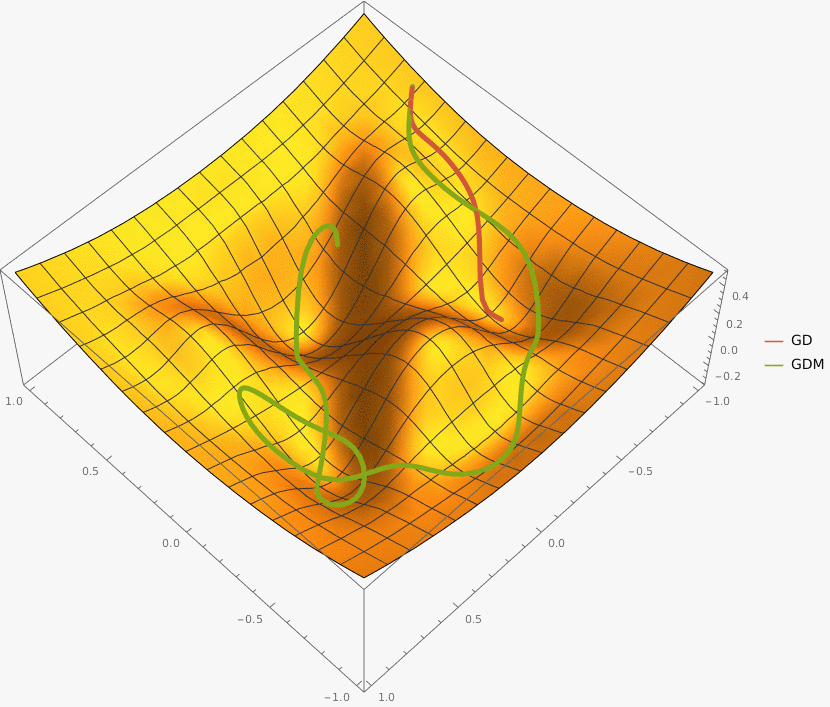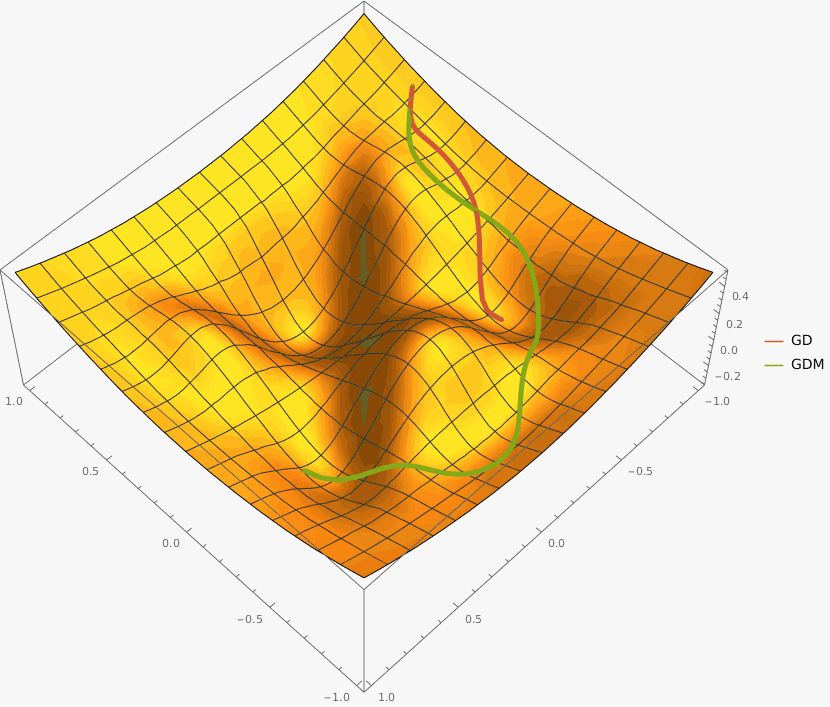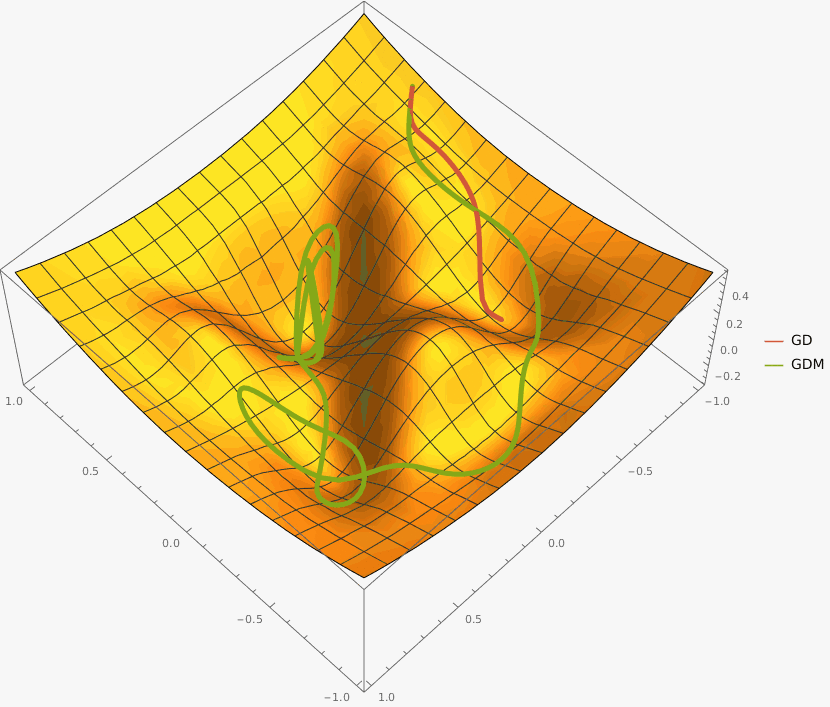
Требуется реализовать на языке Python класс GDM, который описывает алгоритм градиентного спуска с моментом и имеет следующий интерфейс:
import numpy as np
class GDM:
'''Represents a Gradient Descent with Momentum optimizer
Fields:
eta: learning rate
alpha: exponential decay factor
'''
eta: float
alpha: float
def __init__(self, *, alpha: float = 0.9, eta: float = 0.1):
'''Initalizes `eta` and `alpha` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
alpha — скорость затухания момента,
eta — learning rate.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию:
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
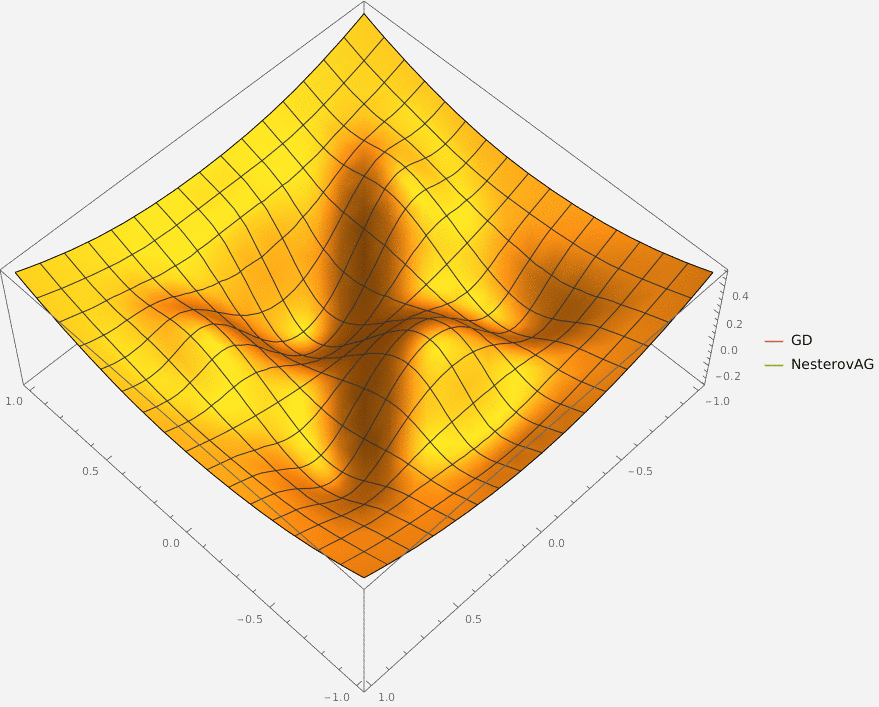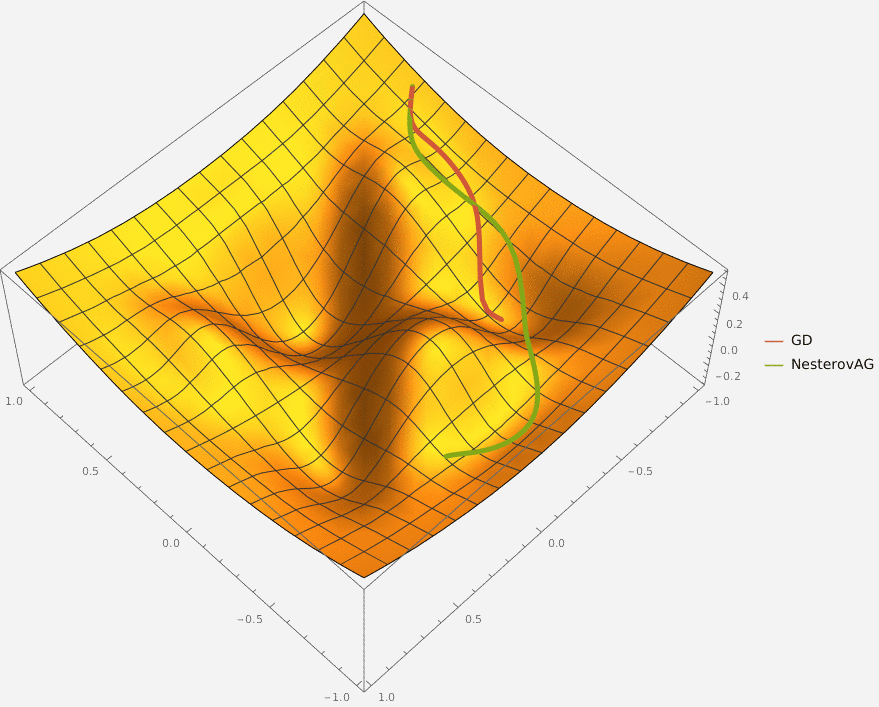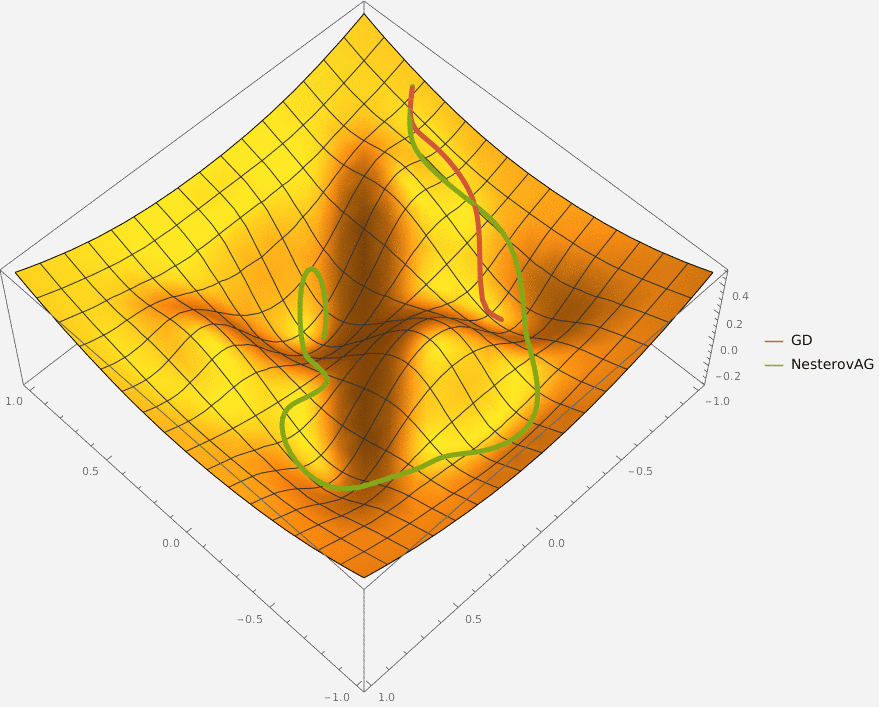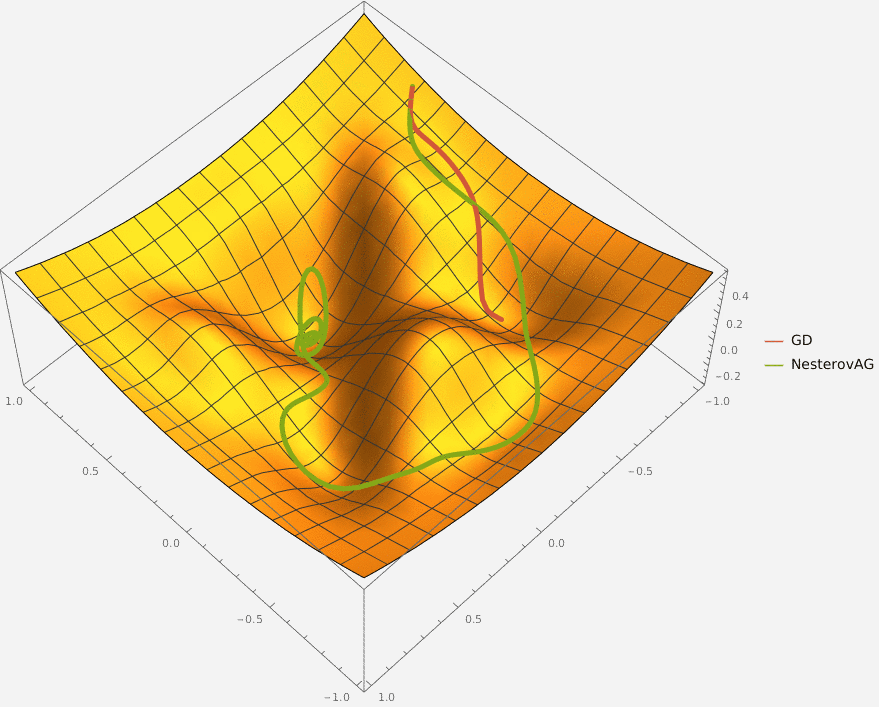
Требуется реализовать на языке Python класс NesterovAG, который описывает алгоритм ускоренного градиента Нестерова и имеет следующий интерфейс
import numpy as np
class NesterovAG:
'''Represents a Nesterov Accelerated Gradient optimizer
Fields:
eta: learning rate
alpha: exponential decay factor
'''
eta: float
alpha: float
def __init__(self, *, alpha: float = 0.9, eta: float = 0.1):
'''Initalizes `eta` and `aplha` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the current gradient is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
alpha — скорость затухания момента,
eta — learning rate.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
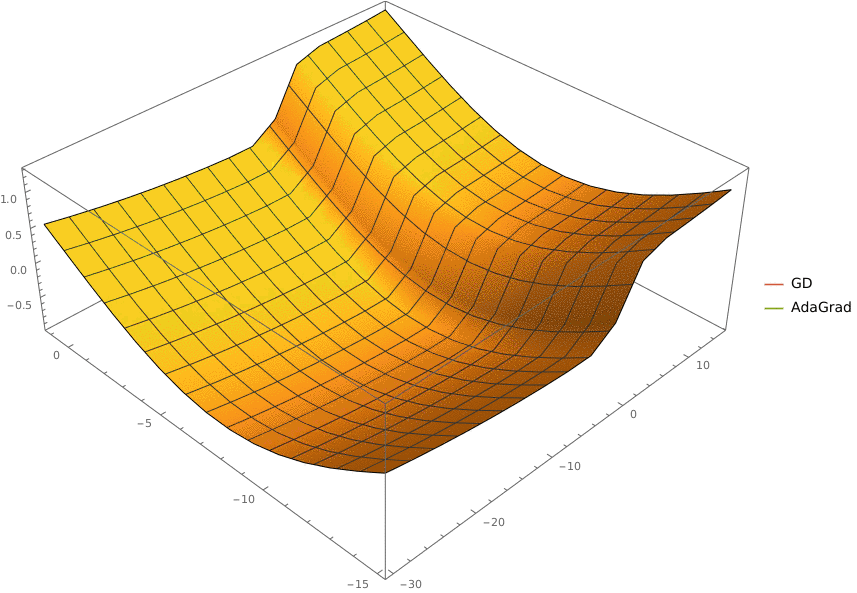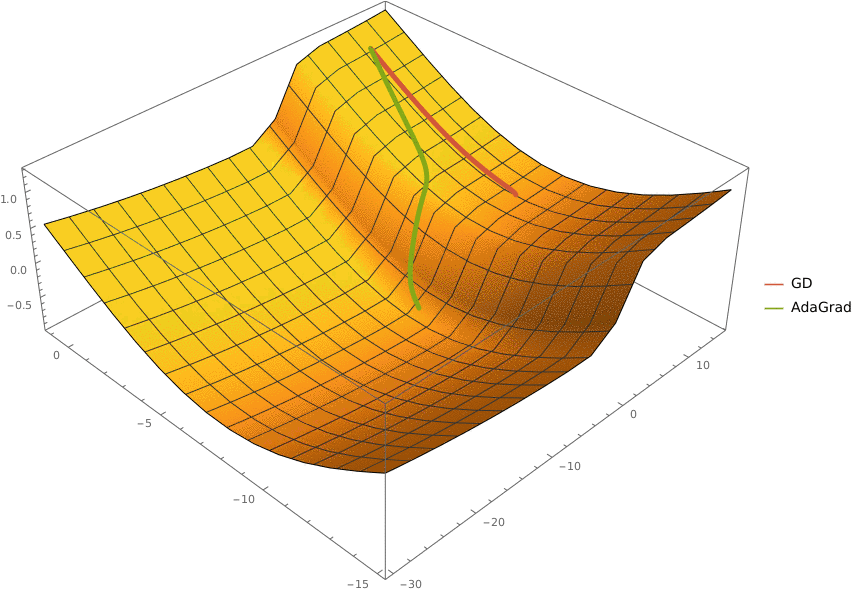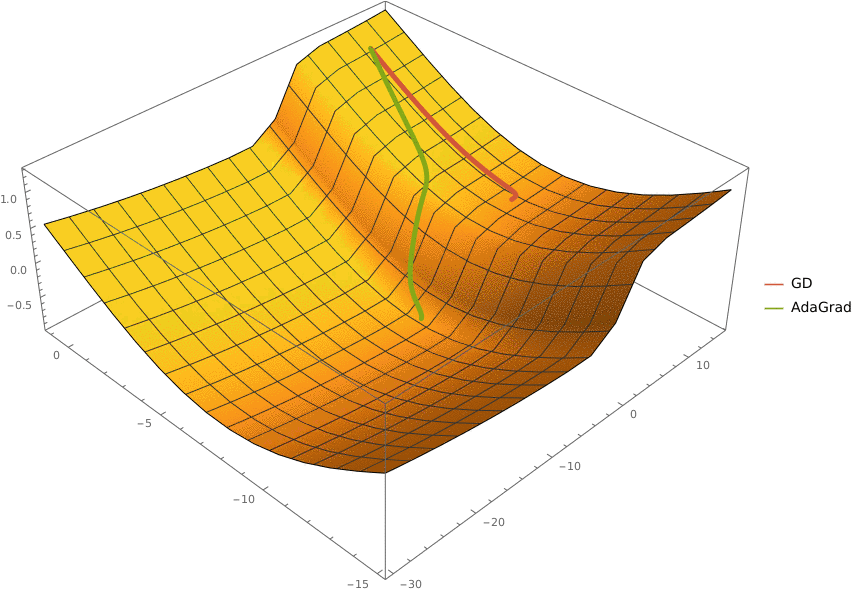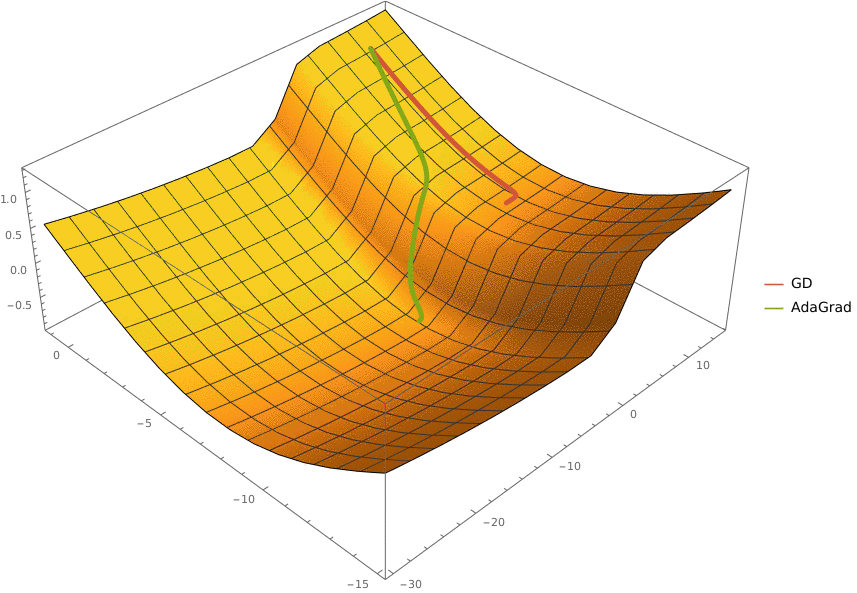
Требуется реализовать на языке Python класс AdaGrad, который описывает алгоритм адаптивного градиентного спуска и имеет следующий интерфейс
import numpy as np
class AdaGrad:
'''Represents an AdaGrad optimizer
Fields:
eta: learning rate
epsilon: smoothing term
'''
eta: float
epsilon: float
def __init__(self, *, eta: float = 0.1, epsilon: float = 1e-8):
'''Initalizes `eta` and `epsilon` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс RMSProp, который описывает одноименный алгоритм и имеет следующий интерфейс
import numpy as np
class RMSProp:
'''Represents an RMSProp optimizer
Fields:
eta: learning rate
gamma: exponential decay factor
epsilon: smoothing term
'''
eta: float
gamma: float
epsilon: float
def __init__(self, *, eta: float = 0.1, gamma: float = 0.9, epsilon: float = 1e-8):
'''Initalizes `eta`, `gamma` and `epsilon` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
gamma — коэффициент затухания,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс Adam, который описывает одноименный алгоритм и имеет следующий интерфейс
import numpy as np
class Adam:
'''Represents an Adam optimizer
Fields:
eta: learning rate
beta1: first moment decay rate
beta2: second moment decay rate
epsilon: smoothing term
'''
eta: float
beta1: float
beta2: float
epsilon: float
def __init__(self, *, eta: float = 0.1, beta1: float = 0.9, beta2: float = 0.999, epsilon: float = 1e-8):
'''Initalizes `eta`, `beta1` and `beta2` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
beta1 — коэффициент затухания первого момента,
beta2 — коэффициент затухания второго момента,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать следующие функции на языке Python.
def linear_func(theta, x) # function value
def linear_func_all(theta, X) # 1-d np.array of function values of all rows of the matrix X
def mean_squared_error(theta, X, y) # MSE value of current regression
def grad_mean_squared_error(theta, X, y) # 1-d array of gradient by theta
theta — одномерный np.array
x — одномерный np.array
X — двумерный np.array. Каждая строка соответствует по размерности вектору theta
y — реальные значения предсказываемой величины
Матрица X имеет размер M × N. M строк и N столбцов.
Используется линейная функция вида: hθ(x) = θ1x1 + θ2x2 + ... + θnxN
Mean squared error (MSE) как функция от θ: J(θ) = 1MM∑i = 1(yi − hθ(x(i)))2. Где x(i) — i-я строка матрицы X
Пусть имеется задача регрессии f(x) = a⋅ x + b ≈ y. Требуется найти коэффициенты регрессии a, такие, что |{ai | ai∈ a, ai = 0}| = k, 0 < k ⩽ |a| = m. При этом должно выполняться условие R2 = 1 − n∑i = 1(yi − f(Xi))2n∑i = 1(yi − y)2⩾ s. При решении задачи предполагается использование алгоритма Lasso.
Формат входных данных
Данные для обучения содержатся в файле. Качество модели будет рассчитано на скрытом наборе данных
Первая строка входных данных содержит натуральное число N — количество тестов. В следующих N блоках содержится описание тестов. Первая строка блока содержит целые числа n — количество примеров обучающей выборки, m — размерность пространства, k — необходимое количество нулевых коэффициентов, и вещественное число s — минимальное значение метрики R2. Следующие n строк содержат по m + 1 вещественному числу — координаты точки пространства и значение целевой переменной y.
Формат выходных данных
Решение должно представлять собой текстовый файл содержащий N строк — коэффициенты a и b линейной регрессии разделённые символом пробел.
Функция single_point_crossover(a, b, point) выполняет одноточечный кроссовер, значения справа от точки кроссовера меняются местами.
Функция two_point_crossover(a, b, first, second) выполняет двухточечный кроссовер, значения между точек кроссовера меняются местами.
Функция k_point_crossover(a, b, points) выполняет k-точечный кроссовер, значения между каждой чётной парой точек меняются местами.
Функции должны иметь следующий интерфейс
import numpy as np
def single_point_crossover(a: np.ndarray, b: np.ndarray, point: int) -> tuple[np.ndarray, np.ndarray]:
"""Performs single point crossover of `a` and `b` using `point` as crossover point.
Chromosomes to the right of the `point` are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
point: crossover point
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError()
def two_point_crossover(a: np.ndarray, b: np.ndarray, first: int, second: int) -> tuple[np.ndarray, np.ndarray]:
"""Performs two point crossover of `a` and `b` using `first` and `second` as crossover points.
Chromosomes between `first` and `second` are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
first: first crossover point
second: second crossover point
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError()
def k_point_crossover(a: np.ndarray, b: np.ndarray, points: np.ndarray) -> tuple[np.ndarray, np.ndarray]:
"""Performs k point crossover of `a` and `b` using `points` as crossover points.
Chromosomes between each even pair of points are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
points: one-dimensional array, crossover points
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError()
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию функций.
import numpy as np
def sus(fitness: np.ndarray, n: int, start: float) -> list:
"""Selects exactly `n` indices of `fitness` using Stochastic universal sampling alpgorithm.
Args:
fitness: one-dimensional array, fitness values of the population, sorted in descending order
n: number of individuals to keep
start: minimal cumulative fitness value
Return:
Indices of the new population"""
raise NotImplementedError()
Параметрами функции являются:
fitness — одномерный массив значений функции приспособленности, отсортированный по убыванию,
n — количество особей, которых нужно оставить,
start — минимальное кумулятивное значение функции приспособленности.
Функция возвращает список индексов выбранных особей
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию функции.
Требуется написать на языке Python класс PoissonRegression, реализующий обобщённую линейную модель, использующую логарифмическую функцию связи
f(x, θ) = exp(n∑i = 1θixi + θ0) ,
где n — количество признаков.
Модель оптимизирует следующую функцию потерь
l(X, y, θ) = 1mm∑i = 1(yilogyif(Xi, θ) − yi + f(Xi, θ)) + α2n∑i = 1θ2i ,
где m — количество примеров, α — параметр регуляризации.
Для оценки качества модели используется метрика D2
D2 = 1 − D(y, ŷ)D(y, y) ,
где y — среднее значение вектора y,
D(y, ŷ) = 2mm∑i = 1(yilogyiŷi − yi + ŷi) .
Класс должен иметь следующий интерфейс
from __future__ import annotations
import numpy as np
class PoissonRegression:
r"""Implements a generalized linear model with log link function[1]
f(x, \theta) = \exp(\sum\limits_{i=1}^n\theta_ix_i + \theta_0)
The model optimizes the following loss
l(X, y, \theta) = \frac{1}{m}\sum\limits_{i=1}^n(y_i\log\frac{y_i}{f(X_i, \theta)} - y_i + f(X_i, \theta)) + \frac{\alpha}{2}\sum\limits_{i=1}^n\theta_i^2
where n, m are numbers of features and samples respectively, $\alpha$ -- regularization strength.
Parameters:
use_bias: bool, default = True
Whether the model uses bias term.
alpha: float, default = 1
L2 regularization strength.
References:
[1]: https://en.wikipedia.org/wiki/Generalized_linear_model#Link_function
"""
def __init__(self, use_bias: bool = True, alpha: float = 1):
"""Initializes `use_bias` and `alpha` fields."""
pass
def predict(self, X: np.ndarray) -> np.ndarray:
"""Computes model value on feature matrix `X`.
Arguments:
X: 2d array of float, feature matrix.
Returns:
1d array of float, predicted values.
"""
pass
def loss(self, X: np.ndarray, y: np.ndarray) -> float:
"""Computes loss value on feature matrix `X` with target values `y`.
Arguments:
X: 2d array of float, feature matrix.
y: 1d array of int, target values.
Returns:
loss value
"""
pass
def score(self, X: np.ndarray, y: np.ndarray) -> float:
r"""Computes D^2 score on feature matrix `X` with target values `y`.
The score is defined as
D^2 = 1 - \frac{D(y, \hat{y})}{D(y, \overline{y})}
where D(y, \hat{y}) = 2(y\log\frac{y}{\hat{y}} - y + \hat{y}).
Arguments:
X: 2d array of float, feature matrix.
y: 1d array of int, target values.
Returns:
score value
"""
pass
def fit(self, X: np.ndarray, y: np.ndarray, *,
eta: float = 1e-3, beta1: float = 0.9, beta2: float = 0.999,
epsilon: float = 1e-8, tol: float = 1e-3, max_iter: int = 1000) -> PoissonRegression:
"""Optimizes model loss w.r.t model coefficitents using Adam[1] optimization algorithm.
Initially model coefficients are initialized with zeros.
Arguments:
X: 2d array of float, feature matrix.
y: 1d array of int, target values.
eta: learning rate.
beta1: first moment decay rate.
beta2: second moment decay rate.
tol: threshold for L2-norm of gradient.
max_iter: maximal number of iterations.
Returns:
self
References:
[1]: https://ruder.io/optimizing-gradient-descent/index.html#adam
"""
pass
@property
def coeffs(self) -> np.ndarray:
"""Returns 1d array of float, coefficients used by the model excluding bias term."""
pass
@property
def bias(self) -> float:
"""Returns bias term used by the model. If `use_bias = False` returns 0."""
pass
Для оптимизации должен быть использован алгоритм
Adam. Оптимизация начинается с нулевой начальной точки θ = {0}ni = 0.
При решении задачи запрещено использовать любые модули, кроме numpy и scipy.special.
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию класса.
Группа разработчиков работает над проектом. Весь проект разбит на задачи, для каждой задачи указывается ее категория сложности (1, 2, 3 или 4), а также оценочное время выполнения задачи в часах. Проект считается выполненным, если выполнены все задачи. Для каждого разработчика и для каждой категории сложности задачи указывается коэффициент, с которым, как ожидается, будет соотноситься реальное время выполнения задачи данным разработчиком к оценочному времени. Считается, что все разработчики начинают работать с проектом в одно и тоже время и выделяют для работы одинаковое время. Необходимо реализовать программу, распределяющую задачи по разработчикам, с целью минимизировать время выполнения проекта (получить готовый проект за минимальный промежуток времени). Поиск решения необходимо реализовать с помощью генетического алгоритма.
Отправка решения и тестирование
Данная задача будет проверяться на ОДНОМ входном файле.
Этот файл можно скачать ЗДЕСЬ.
В качестве решения принимается текстовый файл, содержащий ответ к задаче
в требуемом формате (при его отправке следует выбрать в тестирующей системе среду разработки "Answer text").
Решение набирает количество баллов, вычисляемое по следующей формуле: Score = 106Tmax. Tmax — наибольшее среди всех разработчиков время, затраченное на выполнение выданных соответствующему разработчику задач.
Формат входного файла
Первая строка входного файла содержит целое число N количество задач.
Вторая строка — N целых чисел от 1 до 4 категорий сложности задач.
Третья строка — N вещественных положительных чисел оценочного времени для задач.
Четвертая строка – целое число M, количество разработчиков .
Следующие M строк содержат по 4 вещественных положительных числа — коэффициенты каждого разработчика.
Формат выходного файла
Первая и единственная строка выходного файла содержит N целых чисел wi — номер разработчика, назначенного на i - ю задачу.
Ограничения
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
3
1 1 4
5.2 3.4 4
2
1 1 2 5
0.7 1 1.2 1.5
1 2 2
Задача 6B. Распределение задач. Загрузка решения
≡
Требуется загрузить решение задачи Распределение задач. Баллы за задачу устанавливаются после ручной проверки отправленного решения.
В качестве решения принимается файл с исходным кодом, которым был получен ответ к задаче. В систему требуется отправить ссылку на файл, размещённый в открытом доступе (Google Colab, Github, Google Drive и др.), указав среду разработки "Answer text". После отправки решение необходимо сдать преподавателю лично до начала зачётной недели.
Распределение баллов
Максимальное количество баллов за задачу — 5.
По одному баллу выставляется за преодоление каждого из порогов 0.155, 0.16, 0.165.
Два балла за качество, эффективность решения и использованных методов.
Требуется реализовать функцию
leave-one-out score на языке Python.
Результат функции должен быть целочисленным, то есть его НЕ следует нормировать на размер выборки.
def loo_score(predict, X, y, k) # integer loo score for predict function
predict — функция predict(X, y, x, k) , обучающая некоторый алгоритм на выборке X, y с параметром k и дающая предсказание на примере x
X — двумерный np.array — обучающая выборка
y — реальные значения классов в обучающей выборке
k — количество соседей, которые нужно рассматривать
Пусть на некотором наборе точек X = {xi}ni = 1, xi∈Rm задана функция f: Rm↦N. Требуется написать программу, вычисляющую значение border ratioα(x) = ∥x̂ − y∥2∥ x − y∥2, ∀ x∈ X, где y = argminy∈ X, f(x)≠ f(y)∥ x − y∥2, x̂ = argminx̂∈ X, f(x) = f(x̂)∥x̂ − y∥2.
Формат входных данных
Первая строка входного файла содержит натуральные числа n, m — количество точек и размерность пространства соответственно. В следующих n строках содержится m вещественных чисел и одно натуральное число — координаты точки и значение функции в этой точке.
Формат выходных данных
Выходной файл должен содержать n вещественных чисел — значения border ratio каждой точки с точностью не менее трёх знаков после запятой.
Укажите вопрос, который будете отвечать на экзамене.
1. Введение • Основные термины и задачи машинного обучения. • Признаки, их виды и свойства. Переход между категориальными и численными признаками. • Функция потерь. Оптимизация. • Ошибки первого и второго рода. Метрики качества: accuracy, precision, recall, F1-score. • Случайный поиск. Перебор по сетке. • Проблемы работы с данными высокой размерности.
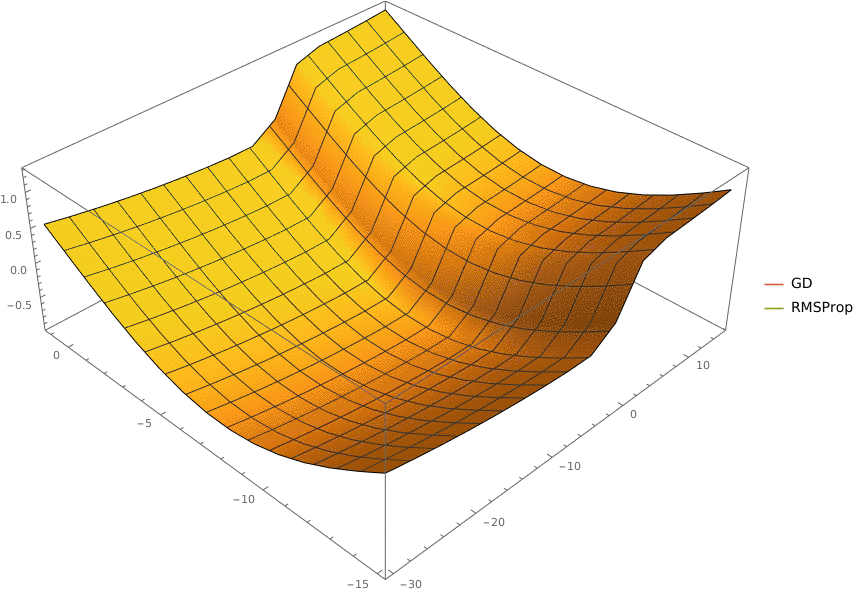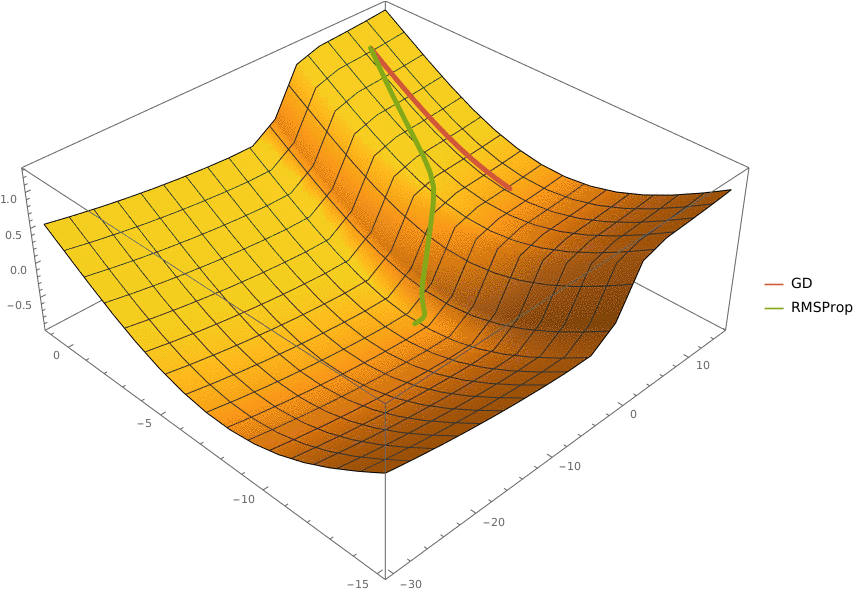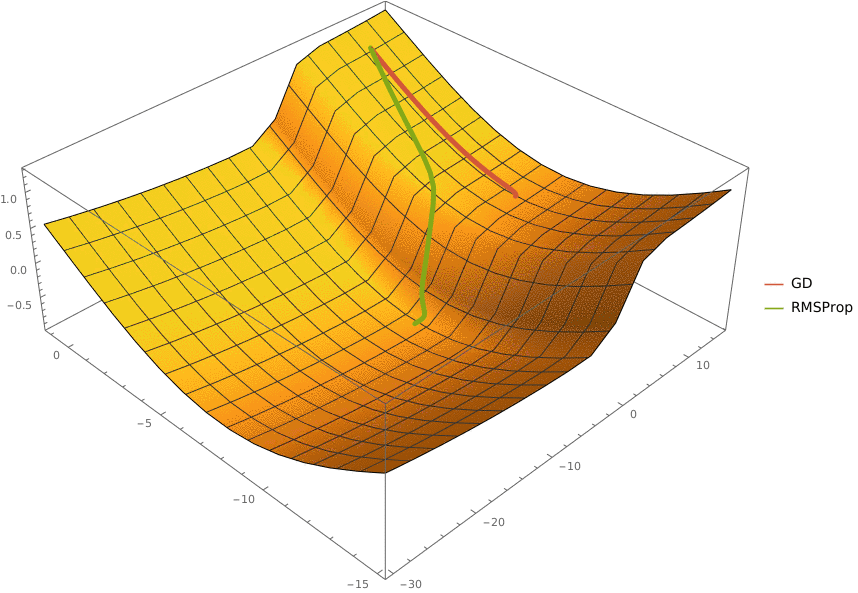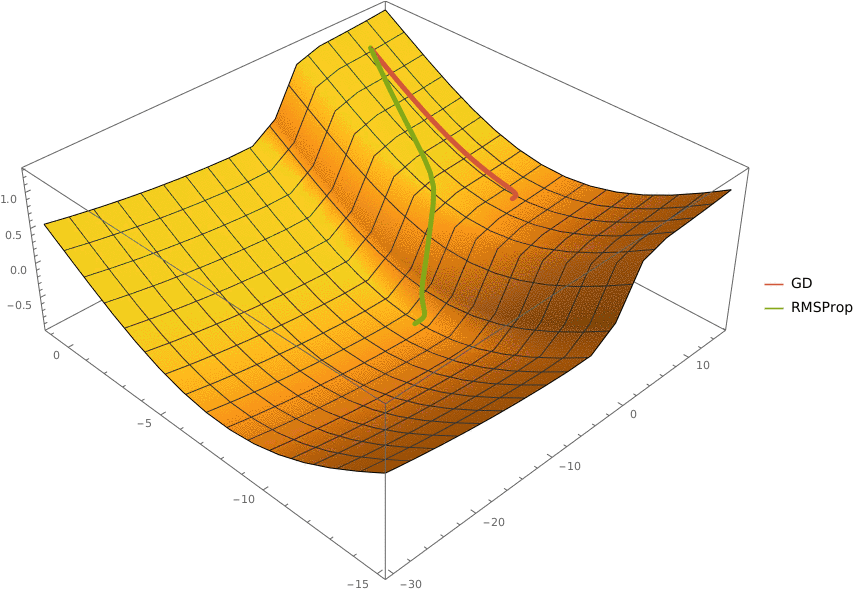
2. Градиентный спуск (gradient descent) • Производная, частные производные, градиент. Методы оценки градиента. • Градиентный спуск, проблема выбора шага. • Стохастический градиентный спуск. • Использование момента. Метод Нестерова. • Метод отжига. • Adagrad, Adadelta, RMSProp, Adam. • AMSGrad, AdamW, YellowFin, AggMo, Quasi-Hyperbolic Momentum, Demon.
3. Линейная регрессия (linear regression) • Постановка задачи линейной регрессии. Вероятностная интерпретация. • Метод наименьших квадратов. Алгебраическое и оптимизационное решения. • Ковариация, корреляция. • Коэффициент деретминации (критерий R2). • Анализ остатков. Гомоскедастичность. Квартет Анскомба. • Решение для неквадратных и плохо обусловненных матриц. • Регуляризация LASSO, Ridge, Elastic. • Обобщённые аддитивные модели (generalized additive models). • Partial Least Squares
4. Логистическая регрессия (logistic regression) • Сигмоид. • Метод наибольшего правдоподобия. • Логистическая регрессия для меток − 1, 1. • Обобщённые линейные модели (generalized linear models) • Пробит-регрессия (probit regression)
5. Глобальная оптимизация. Генетический алгоритм (genetic algorithm) • Многопараметрическая оптимизация. • Доминация и оптимальность по Парето. • Функция качества (fitness). Аппроксимация качества. • Общая идея генетического алгоритма. • Представление генома. • Методы селекции: пропорционально качеству, универсальная выборка (stochastic universal sampling), с наследием (reward-based), турнир. Стратегия элитизма. • Методы кроссовера. Двух и много-точечный, равномерный (по подмножествам), для перестановок. • Мутация. Влияние на скорость обучения. • Управление популяцией. Сегрегация, старение, распараллеливание. • Генетическое программирование.
6. Деревья решений (decision trees) • Понятие энтропии, определение информации по Шеннону. • Понятие дерева решений. • Метрики: примеси Джини (Gini impurity), добавленная информация (information gain). • Алгоритмы ID3, CART. • Борьба с оверфиттингом: bagging, выборки признаков (random subspace method). • Ансамбли, случайный лес (Random Forest). • Деревья регрессии. Метрика вариации. • Непрерывные признаки. Использование главных компонент вместо признаков. • Сокращение дерева (pruning). • Другие алгоритмы вывода правил: 1-rule, RIPPER, bayesian rule lists • Комбинация с линейной регрессией (RuleFit).
7. Метрики и метрическая кластеризация (metrics) • Понятие и свойства метрики. Ослабление требования к неравенству треугольника. • Метрики L1, L2, Хемминга, Левенштейна, косинусное расстояние. • Потеря точности нормы в высоких размерностях. • Нормализация координат. Предварительная трансформация пространства признаков. • Метрика Махаланобиса. • Понятие центроида и представителя класса. • Центроидные алгоритмы: k-means, k-medoid. Алгоритм Ллойда.
8. Метод ближайших соседей (k-NN) • Базовый алгоритм классификации методом 1-NN и k-NN. Преимущества и недостатки. • Кросс-валидация методом "без одного" (leave one out). • Определение границ, показатель пограничности (border ratio). • Сжатие по данным. Понятия выброса, прототипа, усвоенной точки. Алгоритм Харта (Hart). • Регрессия методом k-NN. • Взвешенные соседи. • Связь с градиентным спуском. Стохастическая формулировка, softmax. • Метод соседних компонент (neighbour component analysis) • Связь с выпуклой оптимизацией. Метод большого запаса (Large margin NN) • Оптимизация классификатора, k-d деревья, Hierarchical Navigable Small World • Хеши чувствительные к локальности, хеши сохраняющие локальность
Ссылка на подготовленные материалы (Github, Google Drive и др.). Шпаргалка для ответа на выбранный вопрос.