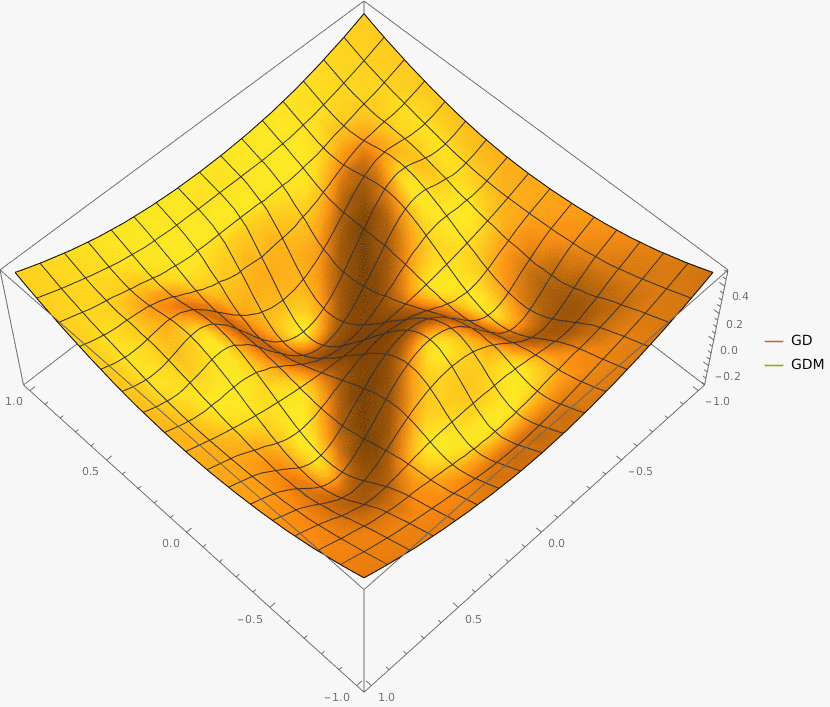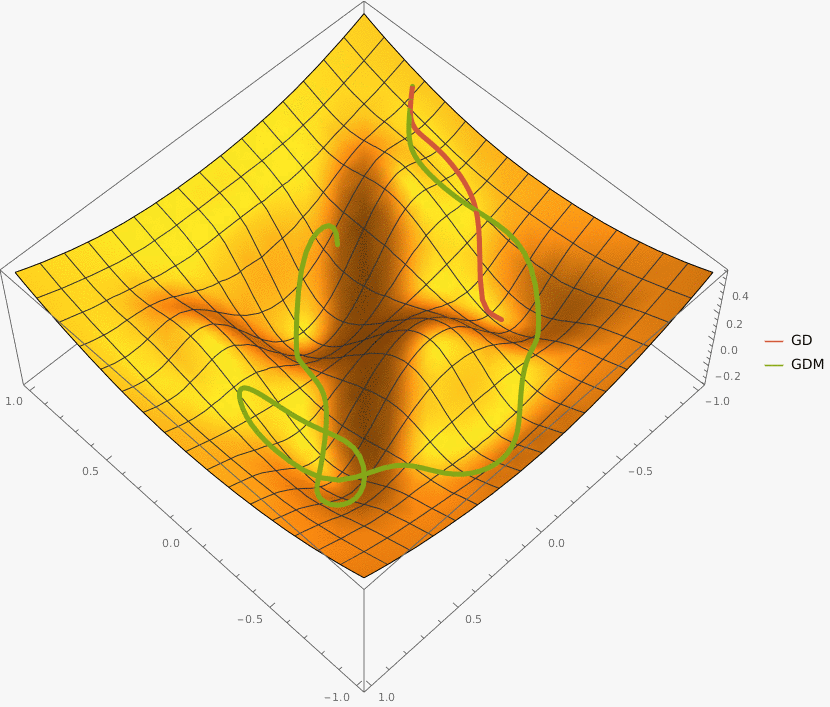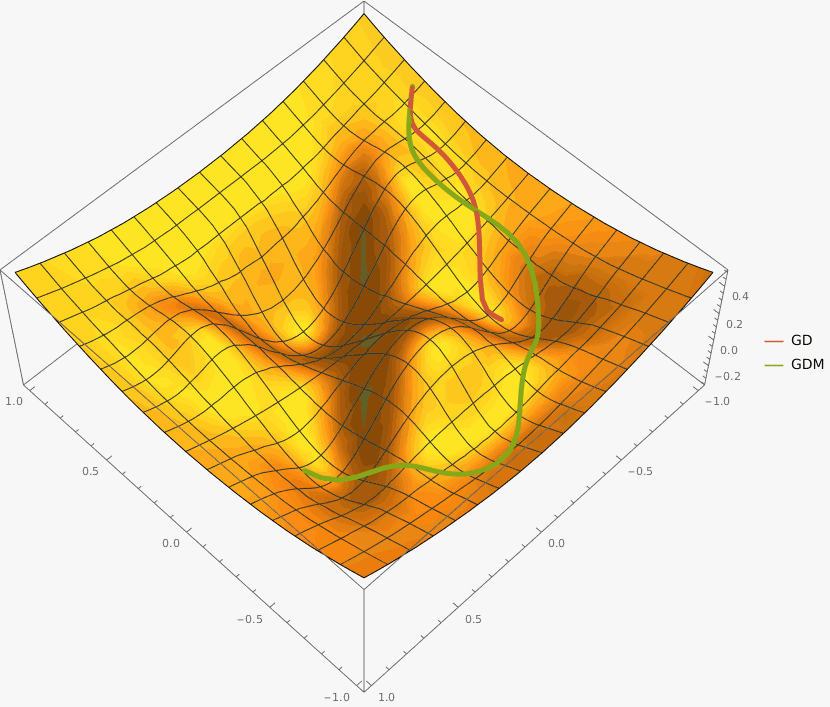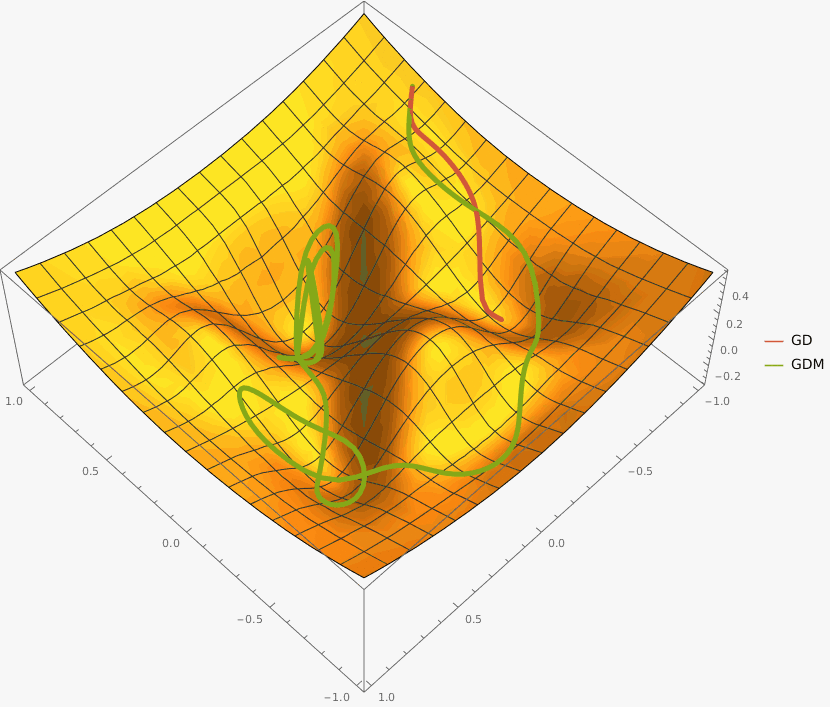
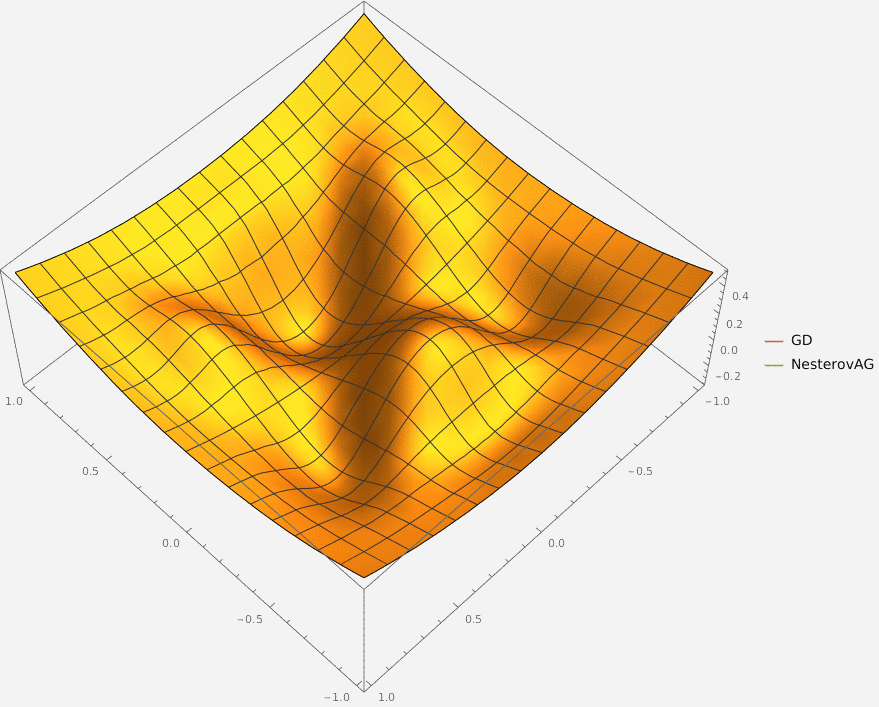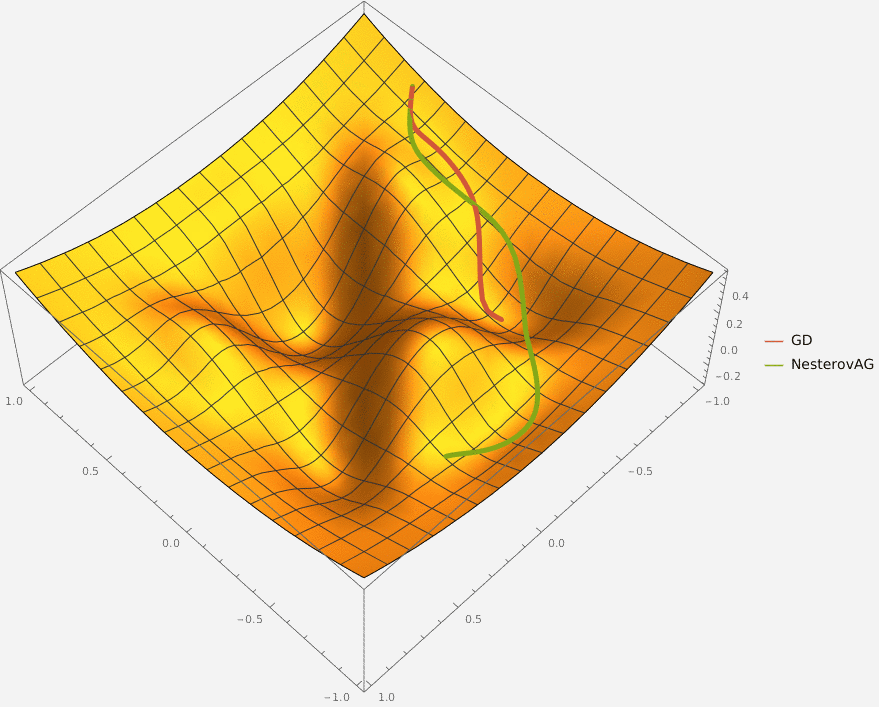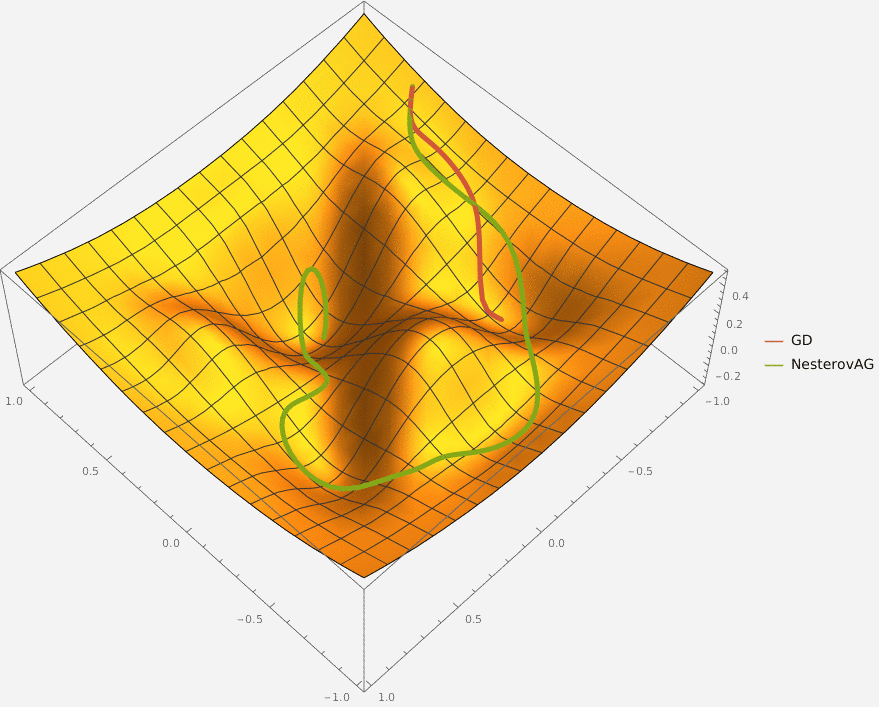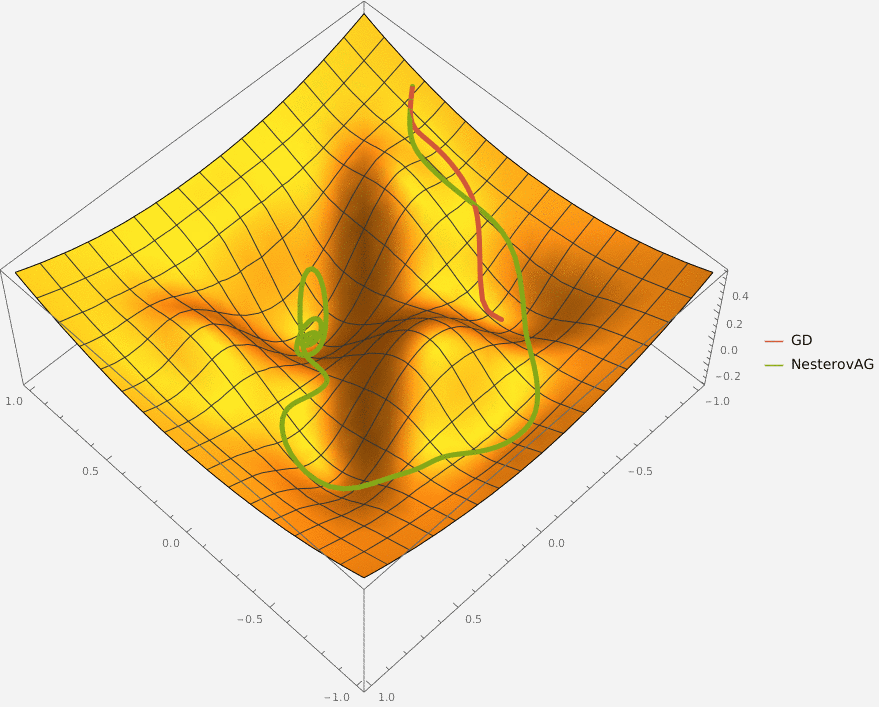
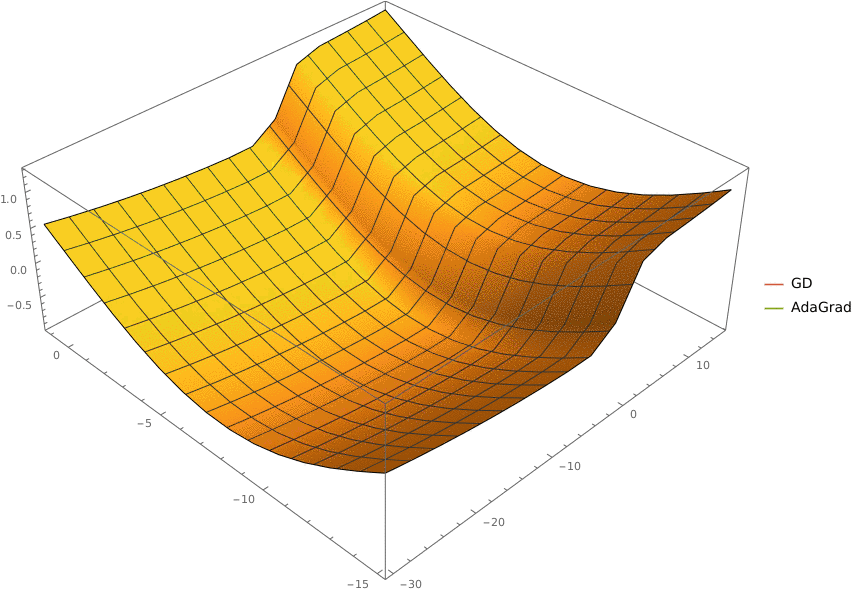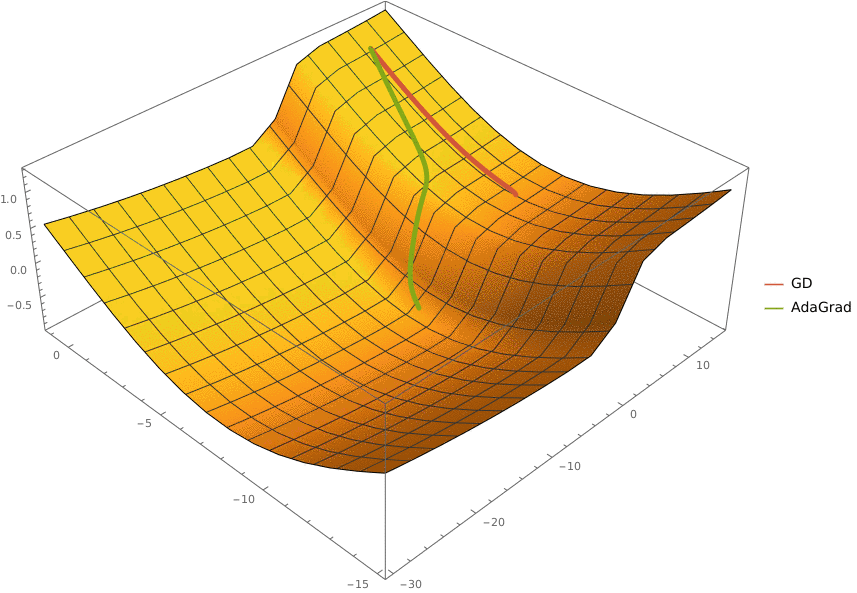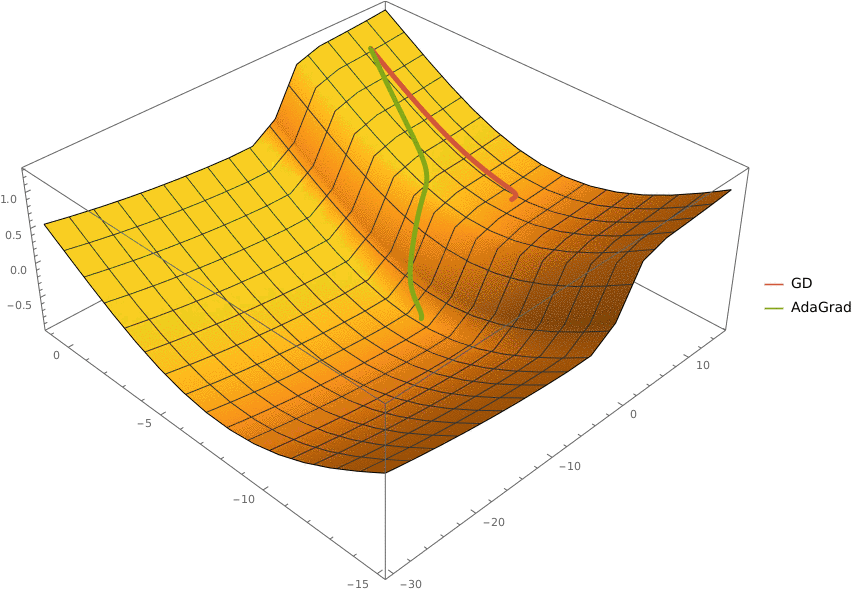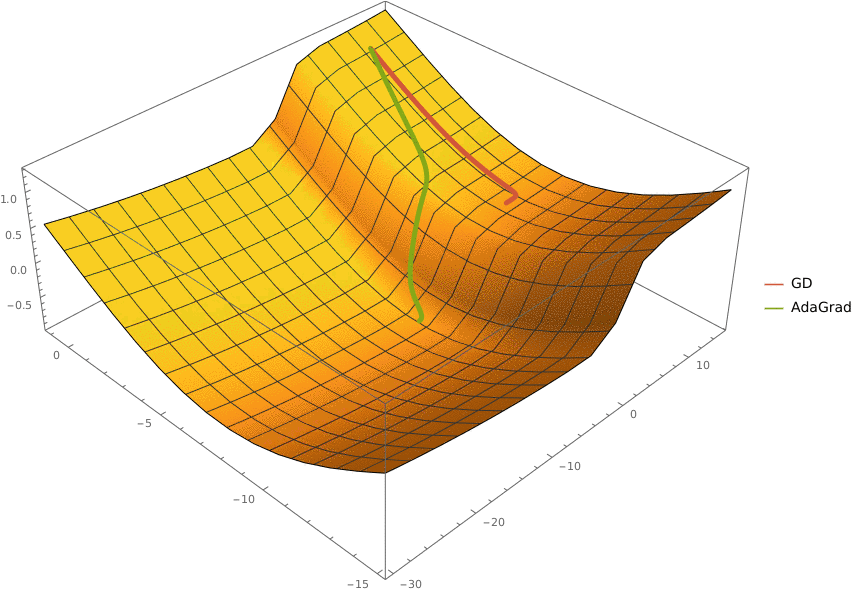
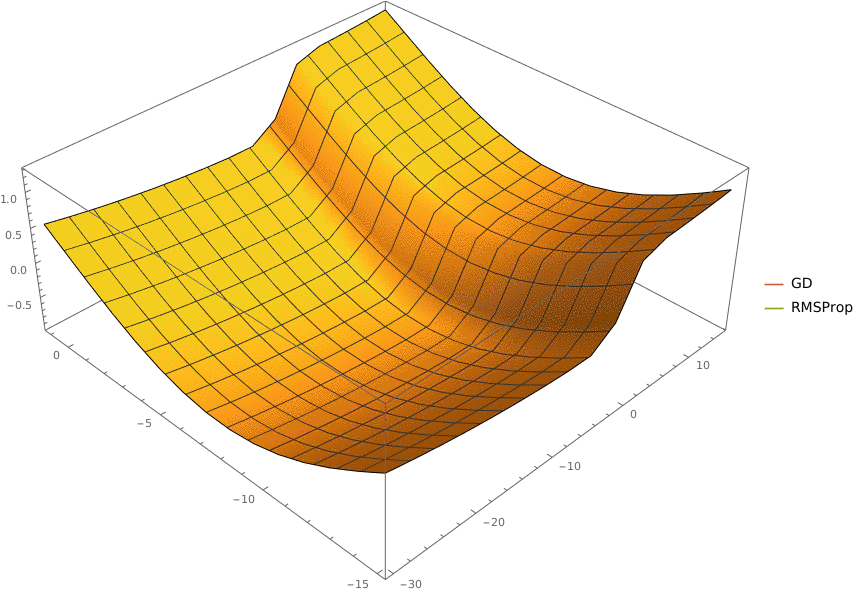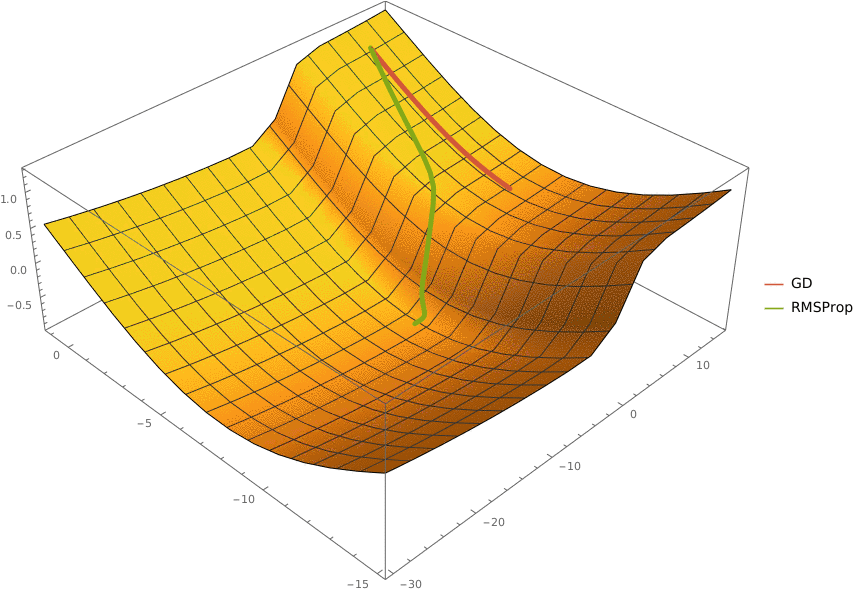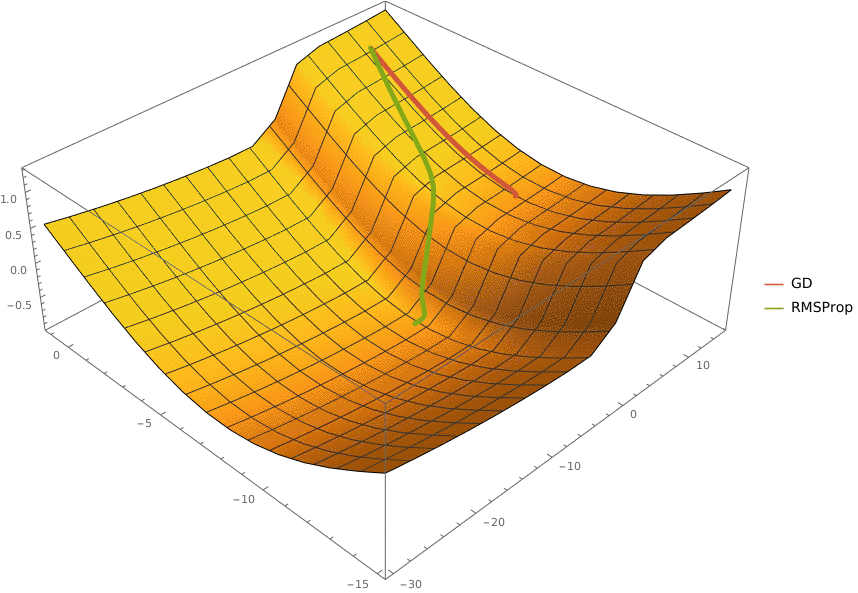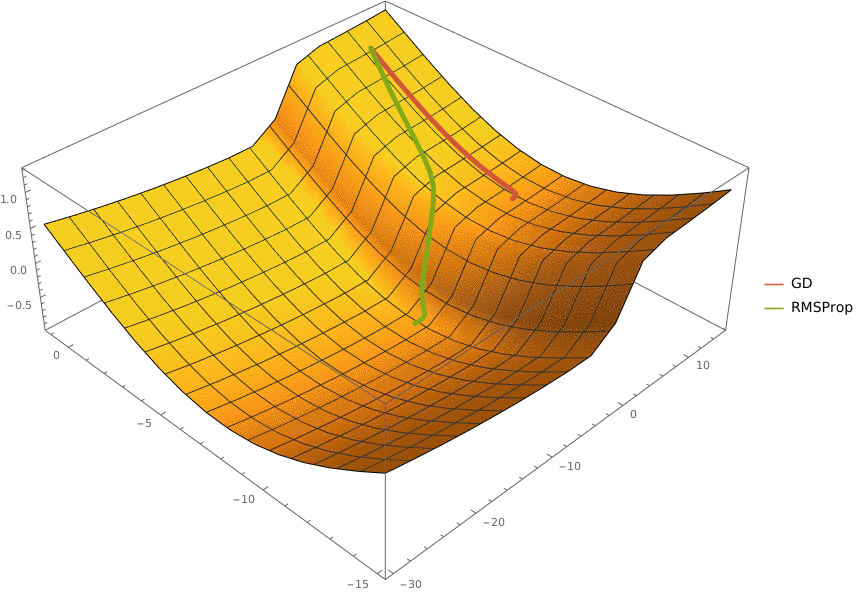
В конструктор принимаются два аргумента —
оракул, с помощью которого можно получить градиент оптимизируемой функции,
а также точку, с которой необходимо начать градиентный спуск.
Метод optimize принимает максимальное число итераций для критерия остановки,
L2-норму градиента, которую можно считать оптимальной,
а также learning rate. Метод возвращает оптимальную точку.
Оракул имеет следующий интерфейс:
class Oracle:
def get_func(self, x)
def get_grad(self, x)
x имеет тип np.array вещественных чисел.
Формат выходных данных
Код должен содержать только класс и его реализацию. Он не должен
ничего выводить на экран.
Требуется реализовать на языке Python класс GDM, который описывает алгоритм градиентного спуска с моментом и имеет следующий интерфейс
import numpy as np
class GDM:
'''Represents a Gradient Descent with Momentum optimizer
Fields:
eta: learning rate
alpha: exponential decay factor
'''
eta: float
alpha: float
def __init__(self, *, alpha: float = 0.9, eta: float = 0.1):
'''Initalizes `eta` and `aplha` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
alpha — скорость затухания момента,
eta — learning rate.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс NesterovAG, который описывает алгоритм ускоренного градиента Нестерова и имеет следующий интерфейс
import numpy as np
class NesterovAG:
'''Represents a Nesterov Accelerated Gradient optimizer
Fields:
eta: learning rate
alpha: exponential decay factor
'''
eta: float
alpha: float
def __init__(self, *, alpha: float = 0.9, eta: float = 0.1):
'''Initalizes `eta` and `aplha` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
alpha — скорость затухания момента,
eta — learning rate.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс AdaGrad, который описывает алгоритм адаптивного градиентного спуска и имеет следующий интерфейс
import numpy as np
class AdaGrad:
'''Represents an AdaGrad optimizer
Fields:
eta: learning rate
epsilon: smoothing term
'''
eta: float
epsilon: float
def __init__(self, *, eta: float = 0.1, epsilon: float = 1e-8):
'''Initalizes `eta` and `epsilon` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс RMSProp, который описывает одноименный алгоритм и имеет следующий интерфейс
import numpy as np
class RMSProp:
'''Represents an RMSProp optimizer
Fields:
eta: learning rate
gamma: exponential decay factor
epsilon: smoothing term
'''
eta: float
gamma: float
epsilon: float
def __init__(self, *, eta: float = 0.1, gamma: float = 0.9, epsilon: float = 1e-8):
'''Initalizes `eta`, `gamma` and `epsilon` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
gamma — коэффициент затухания,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс Adam, который описывает одноименный алгоритм и имеет следующий интерфейс
import numpy as np
class Adam:
'''Represents an Adam optimizer
Fields:
eta: learning rate
beta1: first moment decay rate
beta2: second moment decay rate
epsilon: smoothing term
'''
eta: float
beta1: float
beta2: float
epsilon: float
def __init__(self, *, eta: float = 0.1, beta1: float = 0.9, beta2: float = 0.999, epsilon: float = 1e-8):
'''Initalizes `eta`, `beta1` and `beta2` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
beta1 — коэффициент затухания первого момента,
beta2 — коэффициент затухания второго момента,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать следующие функции на языке Python.
def linear_func(theta, x) # function value
def linear_func_all(theta, X) # 1-d np.array of function values of all rows of the matrix X
def mean_squared_error(theta, X, y) # MSE value of current regression
def grad_mean_squared_error(theta, X, y) # 1-d array of gradient by theta
theta — одномерный np.array
x — одномерный np.array
X — двумерный np.array. Каждая строка соответствует по размерности вектору theta
y — реальные значения предсказываемой величины
Матрица X имеет размер M × N. M строк и N столбцов.
Используется линейная функция вида: hθ(x) = θ1x1 + θ2x2 + ... + θnxN
Mean squared error (MSE) как функция от θ: J(θ) = 1MM∑i = 1(yi − hθ(x(i)))2. Где x(i) — i-я строка матрицы X
Пусть имеется задача регрессии f(x) = a⋅ x + b ≈ y. Требуется найти коэффициенты регрессии a, такие, что |{ai | ai∈ a, ai = 0}| = k, 0 < k ⩽ |a| = m. При этом должно выполняться условие R2 = 1 − n∑i = 1(yi − f(Xi))2n∑i = 1(yi − y)2⩾ s. При решении задачи предполагается использование алгоритма Lasso.
Формат входных данных
Данные для обучения содержатся в файле. Качество модели будет рассчитано на скрытом наборе данных
Первая строка входных данных содержит натуральное число N — количество тестов. В следующих N блоках содержится описание тестов. Первая строка блока содержит целые числа n — количество примеров обучающей выборки, m — размерность пространства, k — необходимое количество нулевых коэффициентов, и вещественное число s — минимальное значение метрики R2. Следующие n строк содержат по m + 1 вещественному числу — координаты точки пространства и значение целевой переменной y.
Формат выходных данных
Решение должно представлять собой текстовый файл содержащий N строк — коэффициенты a и b линейной регрессии разделённые символом пробел.
Функция single_point_crossover(a, b, point) выполняет одноточечный кроссовер, значения справа от точки кроссовера меняются местами.
Функция two_point_crossover(a, b, first, second) выполняет двухточечный кроссовер, значения между точек кроссовера меняются местами.
Функция k_point_crossover(a, b, points) выполняет k-точечный кроссовер, значения между каждой чётной парой точек меняются местами.
Функции должны иметь следующий интерфейс
import numpy as np
from typing import Tuple
def single_point_crossover(a: np.ndarray, b: np.ndarray, point: int) -> Tuple[np.ndarray, np.ndarray]:
"""Performs single point crossover of `a` and `b` using `point` as crossover point.
Chromosomes to the right of the `point` are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
point: crossover point
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError()
def two_point_crossover(a: np.ndarray, b: np.ndarray, first: int, second: int) -> Tuple[np.ndarray, np.ndarray]:
"""Performs two point crossover of `a` and `b` using `first` and `second` as crossover points.
Chromosomes between `first` and `second` are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
first: first crossover point
second: second crossover point
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError()
def k_point_crossover(a: np.ndarray, b: np.ndarray, points: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
"""Performs k point crossover of `a` and `b` using `points` as crossover points.
Chromosomes between each even pair of points are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
points: one-dimensional array, crossover points
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError()
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию функций.
import numpy as np
def sus(fitness: np.ndarray, n: int, start: float) -> list:
"""Selects exactly `n` indices of `fitness` using Stochastic universal sampling alpgorithm.
Args:
fitness: one-dimensional array, fitness values of the population, sorted in descending order
n: number of individuals to keep
start: minimal cumulative fitness value
Return:
Indices of the new population"""
raise NotImplementedError()
Параметрами функции являются:
fitness — одномерный массив значений функции приспособленности, отсортированный по убыванию,
n — количество особей, которых нужно оставить,
start — минимальное кумулятивное значение функции приспособленности.
Функция возвращает список индексов выбранных особей
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию функции.
Требуется реализовать функцию
leave-one-out score на языке Python.
Результат функции должен быть целочисленным, то есть его НЕ следует нормировать на размер выборки.
def loo_score(predict, X, y, k) # integer loo score for predict function
predict — функция predict(X, y, x, k) , обучающая некоторый алгоритм на выборке X, y с параметром k и дающая предсказание на примере x
X — двумерный np.array — обучающая выборка
y — реальные значения классов в обучающей выборке
k — количество соседей, которые нужно рассматривать
Пусть на некотором наборе точек X = {xi}ni = 1, xi∈Rm задана функция f: Rm↦N. Требуется написать программу, вычисляющую значение border ratioα(x) = ∥x̂ − y∥2∥ x − y∥2, ∀ x∈ X, где y = argminy∈ X, f(x)≠ f(y)∥ x − y∥2, x̂ = argminx̂∈ X, f(x) = f(x̂)∥x̂ − y∥2.
Формат входных данных
Первая строка входного файла содержит натуральные числа n, m — количество точек и размерность пространства соответственно. В следующих n строках содержится m вещественных чисел и одно натуральное число — координаты точки и значение функции в этой точке.
Формат выходных данных
Выходной файл должен содержать n вещественных чисел — значения border ratio каждой точки с точностью не менее трёх знаков после запятой.
Пусть задан некоторый набор точек X = {xi}ni = 1, xi∈Rm.
Требуется выполнить кластеризацию точек на k кластеров,
используя наивный алгоритм
KMeans.
Формат входных данных
Первая строка входных данных содержит натуральные числа n, m, k, t —
количество точек, размерность пространства,
количество кластеров и максимальное количество итераций соответственно.
В каждой из следующих n строк содержится m вещественных чисел и
одно натуральное число — координаты точки и начальное значение кластера точки.
Значения кластеров нумеруются от 0 до k − 1.
Формат выходных данных
Выходной данные должны содержать n натуральных чисел — номер кластера каждой точки.
Группа разработчиков работает над проектом. Весь проект разбит на задачи, для каждой задачи указывается ее категория сложности (1, 2, 3 или 4), а также оценочное время выполнения задачи в часах. Проект считается выполненным, если выполнены все задачи. Для каждого разработчика и для каждой категории сложности задачи указывается коэффициент, с которым, как ожидается, будет соотноситься реальное время выполнения задачи данным разработчиком к оценочному времени. Считается, что все разработчики начинают работать с проектом в одно и тоже время и выделяют для работы одинаковое время. Необходимо реализовать программу, распределяющую задачи по разработчикам, с целью минимизировать время выполнения проекта (получить готовый проект за минимальный промежуток времени). Поиск решения необходимо реализовать с помощью генетического алгоритма.
Отправка решения и тестирование
Данная задача будет проверяться на ОДНОМ входном файле.
Этот файл можно скачать ЗДЕСЬ.
В качестве решения принимается текстовый файл, содержащий ответ к задаче
в требуемом формате (при его отправке следует выбрать в тестирующей системе среду разработки "Answer text").
Решение набирает количество баллов, вычисляемое по следующей формуле: Score = 106Tmax. Tmax — наибольшее среди всех разработчиков время, затраченное на выполнение выданных соответствующему разработчику задач.
Формат входного файла
Первая строка входного файла содержит целое число N количество задач.
Вторая строка — N целых чисел от 1 до 4 категорий сложности задач.
Третья строка — N вещественных положительных чисел оценочного времени для задач.
Четвертая строка – целое число M, количество разработчиков .
Следующие M строк содержат по 4 вещественных положительных числа — коэффициенты каждого разработчика.
Формат выходного файла
Первая и единственная строка выходного файла содержит N целых чисел wi — номер разработчика, назначенного на i - ю задачу.
1. Введение (intro)
* Основные термины и задачи машинного обучения.
* Признаки, их виды и свойства.
* Функция потерь. Оптимизация.
* Ошибки первого и второго рода. Метрики качества: accuracy, precision, recall, F1-score.
* Случайный поиск. Перебор по сетке.
* Проблемы работы с данными высокой размерности.
2. Градиентный спуск (gradient descent)
* Производная, частные производные, градиент. Методы оценки градиента.
* Градиентный спуск, проблема выбора шага.
* Стохастический градиентный спуск.
* Использование момента. Метод Нестерова.
* Метод отжига.
* Adagrad, Adadelta, RMSProp, Adam.
3. Линейная регрессия (linear regression)
* Постановка задачи линейной регрессии. Вероятностная интерпретация.
* Метод наименьших квадратов. Алгебраическое и оптимизационное решения.
* Ковариация, корреляция.
* Критерий R2.
* Анализ остатков. Гомоскедастичность. Квартет Анскомба.
* Решение для неквадратных и плохо обусловненных матриц.
* Регуляризация LASSO.
* Регуляризация Ridge, Elastic*.
* Обобщённые аддитивные модели (generalized additive models)*.
4. Логистическая регрессия (logistic regression)
* Сигмоид.
* Метод наибольшего правдоподобия.
* Логистическая регрессия для меток − 1, 1.
* Обобщённые линейные модели (generalized linear models)*.
5. Глобальная оптизация. Генетический алгоритм (genetic algorithm)
* Многопараметрическая оптимизация.
* Доминация и оптимальность по Парето.
* Функция качества (fitness). Аппроксимация качества.
* Общая идея генетического алгоритма.
* Представление генома.
* Методы селекции: пропорционально качеству, универсальная выборка (stochastic universal sampling), с наследием (reward-based), турнир. Стратегия элитизма.
* Методы кроссовера. Двух и много-точечный, равномерный (по подмножествам), для перестановок.
* Мутация. Влияние на скорость обучения.
* Управление популяцией. Сегрегация, старение, распараллеливание.
* Генетическое программирование*.
6. Деревья решений (decision trees)
* Понятие энтропии, определение информации по Шеннону.
* Понятие дерева решений.
* Метрики: примеси Джини (Gini impurity), добавленная информация (information gain).
* Алгоритмы ID3, CART.
* Борьба с оверфиттингом: bagging, выборки признаков (random subspace method).
* Ансамбли, случайный лес (Random Forest).
* Деревья регрессии. Метрика вариации.
* Непрерывные признаки. Использование главных компонент вместо признаков.
* Сокращение дерева (pruning).
* Другие алгоритмы вывода правил: 1-rule, RIPPER, bayesian rule lists*.
* Комбинация с линейной регрессией (RuleFit)*.
7. Композиция классификаторов. Бустинг (boosting)
* Понятие бустинга. Бустинг для бинарной классификации, регрессии.
* Градиентный бустинг.
* AdaBoost. Алгоритм Виолы-Джонса.
* Извлечение признаков. Признаки Хаара (Haar).
* Бустинг деревьев решений. XGBoost.
* CatBoost
* LPBoost, BrownBoost, ComBoost*.
8. Метрики и метрическая кластеризация (metrics)
* Понятие и свойства метрики. Ослабление требования к неравенству треугольника.
* Метрики L1, L2, Хемминга, Левенштейна, косинусное расстояние.
* Потеря точности нормы в высоких размерностях.
* Нормализация координат. Предварительная трансформация пространства признаков.
* Метрика Махаланобиса.
* Понятие центроида и представителя класса.
* Центроидные алгоритмы: k-means, k-medoid. Алгоритм Ллойда.
9. Метод ближайших соседей (k-NN)
* Базовый алгоритм классификации методом 1-NN и k-NN. Преимущества и недостатки.
* Кросс-валидация методом "без одного" (leave one out).
* Определение границ, показатель пограничности (border ratio).
* Сжатие по данным. Понятия выброса, прототипа, усвоенной точки. Алгоритм Харта (Hart).
* Регрессия методом k-NN.
* Взвешенные соседи.
* Связь с градиентным спуском. Стохастическая формулировка, softmax.
* Метод соседних компонент (neighbour component analysis)*.
* Связь с выпуклой оптимизацией. Метод большого запаса (Large margin NN)*.
* Оптимизация классификатора, k-d деревья, Hierarchical Navigable Small World*.
* Хеши чувствительные к локальности, хеши сохраняющие локальность*.
10. Кластеризация (clustering)
* Задача обучения без учителя, применения при эксплораторном анализе.
* Иерархическая кластеризация: методы снизу вверх и сверху вниз.
* Алгоритмы, основанные на связности: функция схожести, компоненты связности и остовные деревья, критерии связности.
* Алгоритм BIRCH*.
* Алгоритмы, основанные на плотности: DBSCAN, OPTICS.
* Алгоритмы, основанные на распределении: сумма гауссиан.
* Нечёткая кластеризация, алгоритм c-means.
* Поиск моды (Mean-Shift)*.
* Внутренние оценки качества: leave-one-out, силуэт, индекс Дэвиса-Болдина (Davies-Bouldin), индекс Данна (Dunn).
* Внешние оценки качества.
11. Снижение размерности (dimensionality reduction)
Постановка задачи, причины и цели снижения размерности.
Выбор и извлечение признаков.
Подходы к выбору признаков: filtering, wrapping, embedding.
Расстояние между распределениями. Расстояние Кульбака-Лейблера. Взаимная информация.
Алгоритмы выбора признаков: на основе корреляции (CFS), взаимной информации, Relief.
Метод главных компонент (PCA).
Многомерное шкалирование (multidimensional scaling). Isomap.
Стохастическое вложение соседей с t-распределением (t-SNE).
Нелинейные обобщения метода главных компонент. Kernel PCA.*
Неотрицательное матричное разложение (NMF).*
Анализ независимых компонент (ICA).*