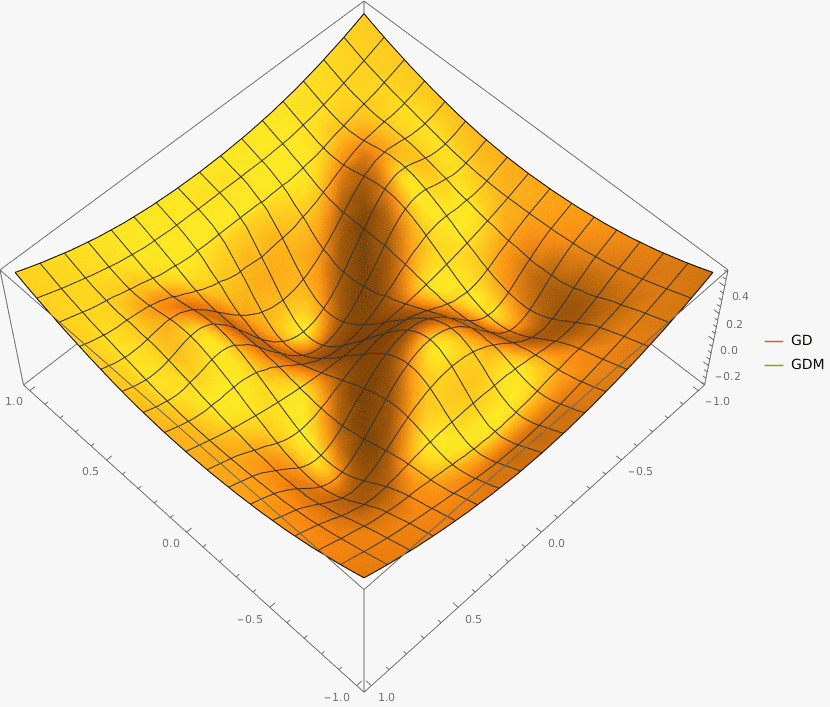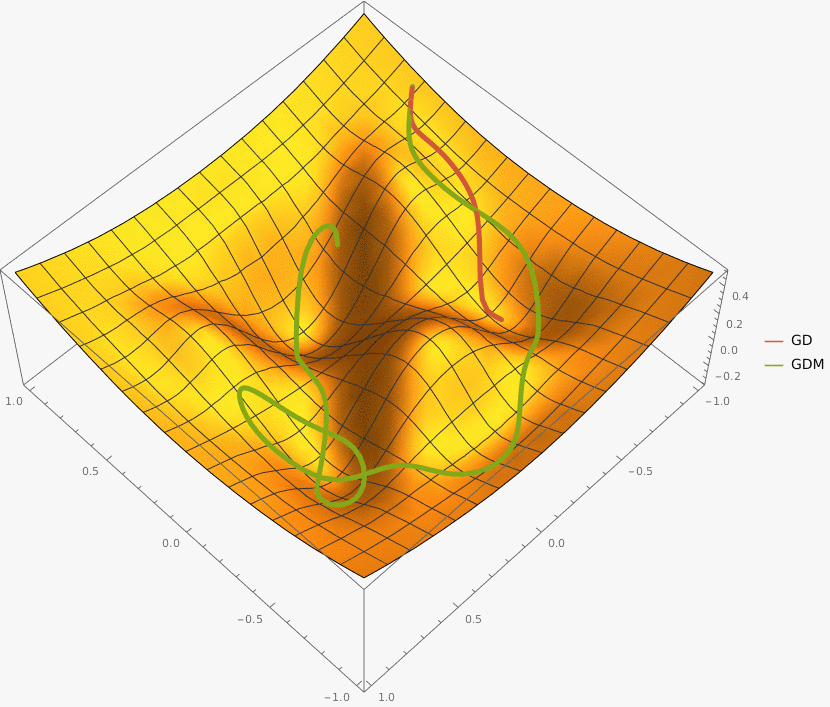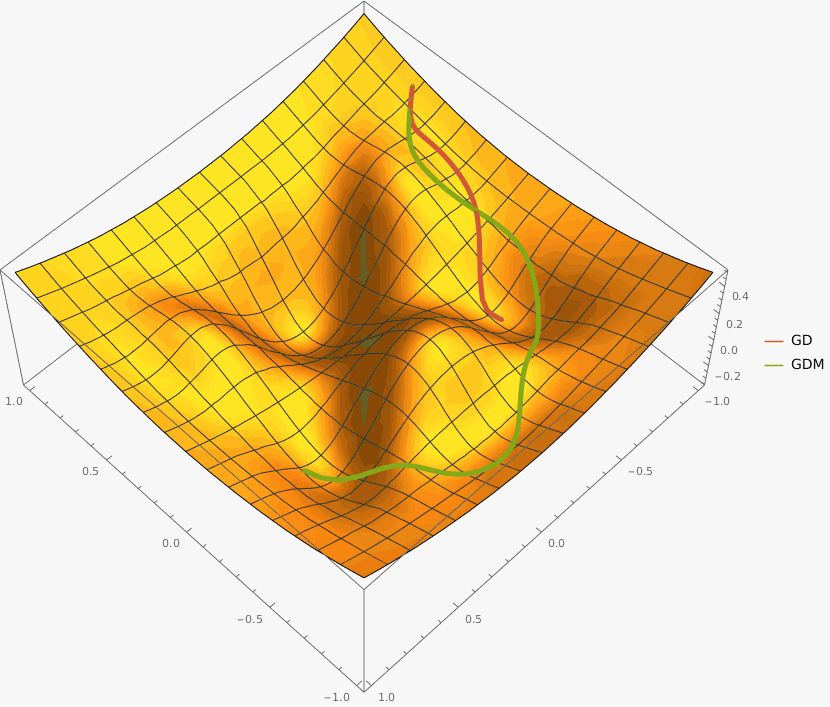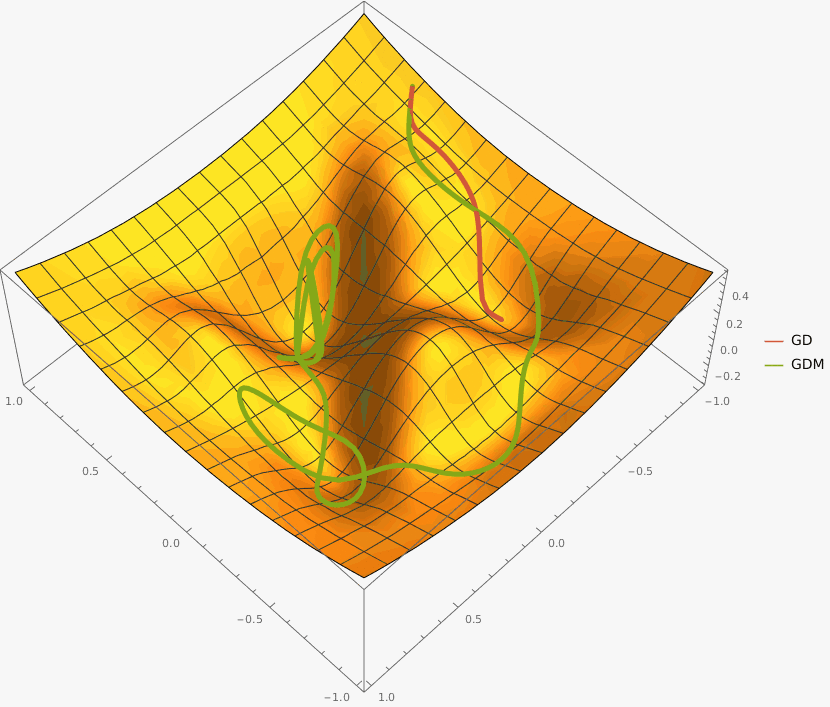
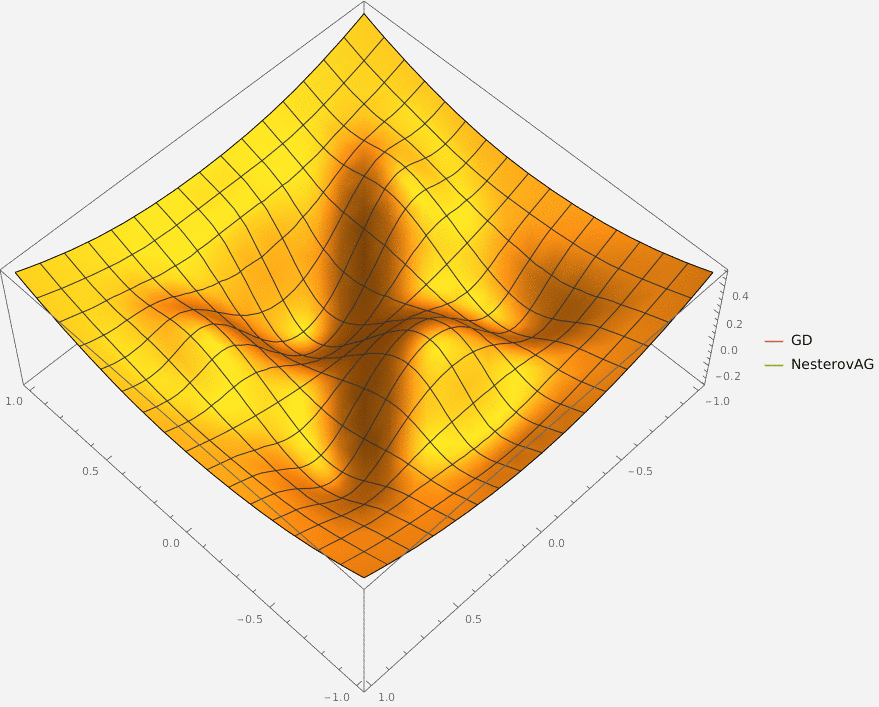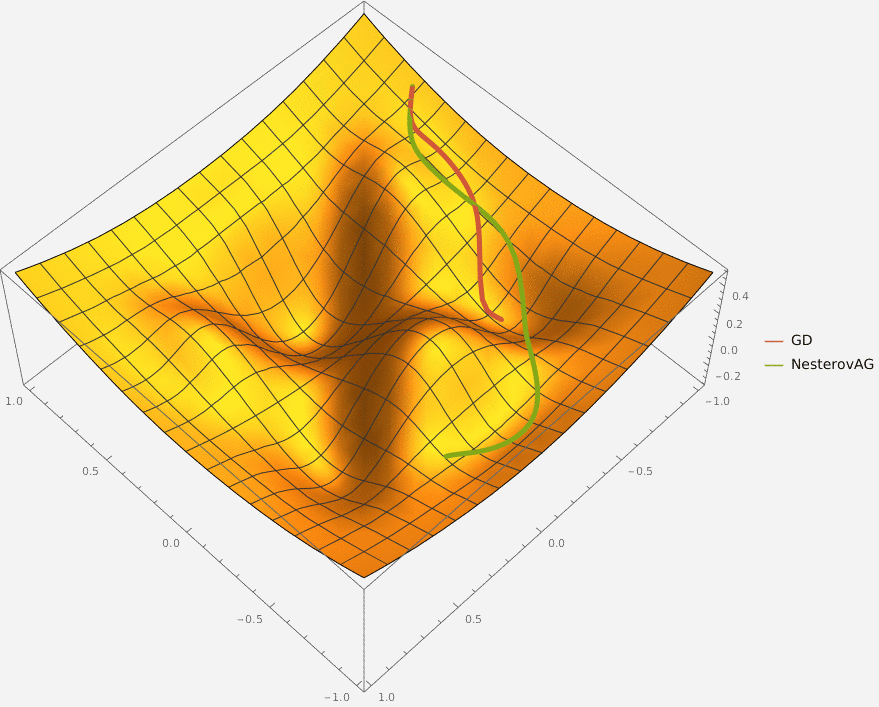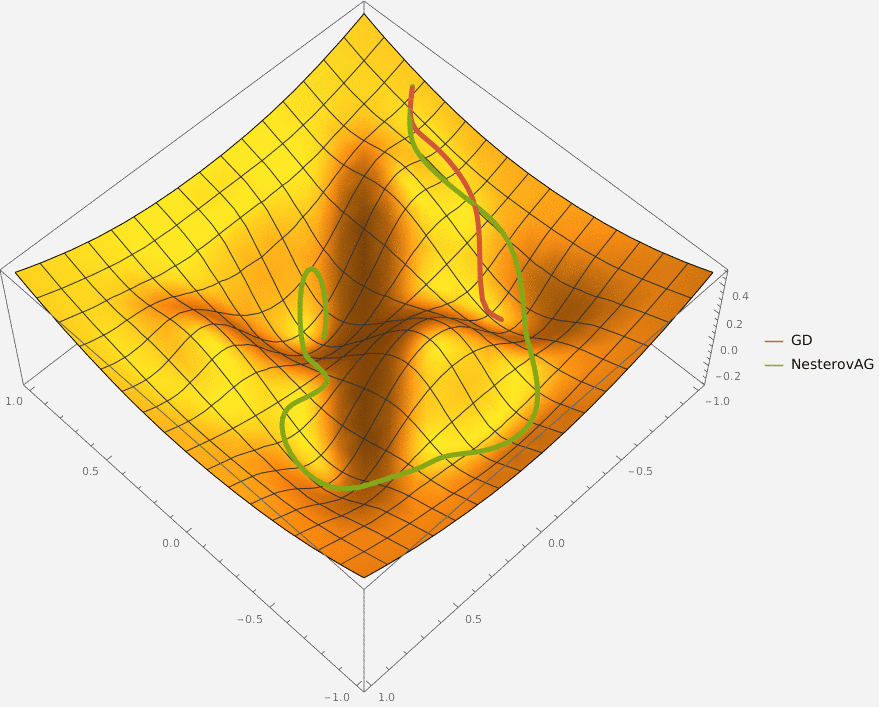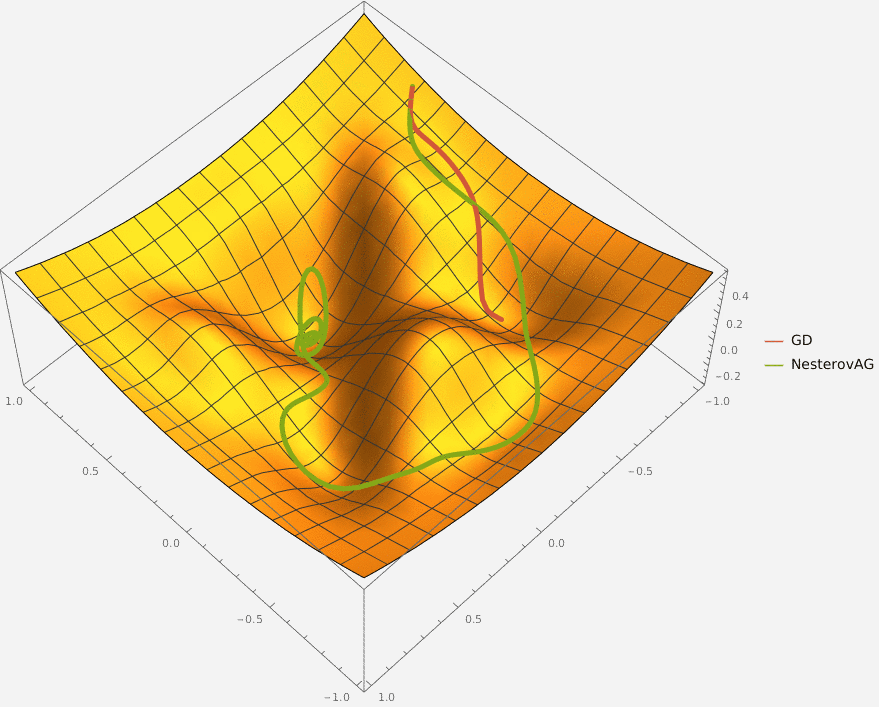
Задача A. Градиентный спуск
Условие
Требуется реализовать класс на языке Python ,
который соответствует следующему интерфейсу.
class GradientOptimizer :
def __init__ ( self , oracle , x0 ) :
self .oracle = oracle
self .x0 = x0
def optimize ( self , iterations , eps , alpha ) :
pass
В конструктор принимаются два аргумента —
оракул, с помощью которого можно получить градиент оптимизируемой функции,
а также точку, с которой необходимо начать градиентный спуск.
Метод optimize принимает максимальное число итераций для критерия остановки,
L2-норму градиента, которую можно считать оптимальной,
а также learning rate . Метод возвращает оптимальную точку.
Оракул имеет следующий интерфейс:
class Oracle :
def get_func ( self , x ) : pass
def get_grad ( self , x ) : pass
x имеет тип np.array вещественных чисел.
Формат выходных данных
Код должен содержать только класс и его реализацию. Он не должен
ничего выводить на экран.
Задача B. Gradient Descent with Momentum
Условие
Требуется реализовать на языке Python класс GDM, который описывает алгоритм градиентного спуска с моментом и имеет следующий интерфейс:
import numpy as np
class GDM :
'''Represents a Gradient Descent with Momentum optimizer
Fields:
eta: learning rate
alpha: exponential decay factor
'''
eta : float
alpha : float
def __init__ ( self , * , alpha : float = 0.9 , eta : float = 0.1 ) :
'''Initalizes `eta` and `alpha` fields'''
raise NotImplementedError ( )
def optimize ( self , oracle : Oracle , x0 : np .ndarray , * ,
max_iter : int = 100 , eps : float = 1e-5 ) -> np .ndarray :
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError ( )
Параметрами алгоритма являются:
alpha — скорость затухания момента,eta — learning rate .
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,x0 — начальная точка,max_iter — максимальное количество итераций,eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении
max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше
eps.
Класс Oracle описывает оптимизируемую функцию:
import numpy as np
class Oracle :
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value ( self , x : np .ndarray ) -> float :
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError ( )
def gradient ( self , x : np .ndarray ) -> np .ndarray :
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError ( )
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Задача C. Nesterov Accelerated Gradient
Условие
Требуется реализовать на языке Python класс NesterovAG, который описывает алгоритм ускоренного градиента Нестерова и имеет следующий интерфейс
import numpy as np
class NesterovAG :
'''Represents a Nesterov Accelerated Gradient optimizer
Fields:
eta: learning rate
alpha: exponential decay factor
'''
eta : float
alpha : float
def __init__ ( self , * , alpha : float = 0.9 , eta : float = 0.1 ) :
'''Initalizes `eta` and `aplha` fields'''
raise NotImplementedError ( )
def optimize ( self , oracle : Oracle , x0 : np .ndarray , * ,
max_iter : int = 100 , eps : float = 1e-5 ) -> np .ndarray :
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the current gradient is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError ( )
Параметрами алгоритма являются:
alpha — скорость затухания момента,eta — learning rate .
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,x0 — начальная точка,max_iter — максимальное количество итераций,eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении
max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше
eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle :
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value ( self , x : np .ndarray ) -> float :
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError ( )
def gradient ( self , x : np .ndarray ) -> np .ndarray :
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError ( )
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Задача D. AdaGrad
Условие
Требуется реализовать на языке Python класс AdaGrad, который описывает алгоритм адаптивного градиентного спуска и имеет следующий интерфейс
import numpy as np
class AdaGrad :
'''Represents an AdaGrad optimizer
Fields:
eta: learning rate
epsilon: smoothing term
'''
eta : float
epsilon : float
def __init__ ( self , * , eta : float = 0.1 , epsilon : float = 1e-8 ) :
'''Initalizes `eta` and `epsilon` fields'''
raise NotImplementedError ( )
def optimize ( self , oracle : Oracle , x0 : np .ndarray , * ,
max_iter : int = 100 , eps : float = 1e-5 ) -> np .ndarray :
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError ( )
Параметрами алгоритма являются:
eta — learning rate ,epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,x0 — начальная точка,max_iter — максимальное количество итераций,eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении
max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше
eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle :
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value ( self , x : np .ndarray ) -> float :
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError ( )
def gradient ( self , x : np .ndarray ) -> np .ndarray :
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError ( )
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Задача E. RMSProp
Условие
Требуется реализовать на языке Python класс RMSProp, который описывает одноименный алгоритм и имеет следующий интерфейс
import numpy as np
class RMSProp :
'''Represents an RMSProp optimizer
Fields:
eta: learning rate
gamma: exponential decay factor
epsilon: smoothing term
'''
eta : float
gamma : float
epsilon : float
def __init__ ( self , * , eta : float = 0.1 , gamma : float = 0.9 , epsilon : float = 1e-8 ) :
'''Initalizes `eta`, `gamma` and `epsilon` fields'''
raise NotImplementedError ( )
def optimize ( self , oracle : Oracle , x0 : np .ndarray , * ,
max_iter : int = 100 , eps : float = 1e-5 ) -> np .ndarray :
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError ( )
Параметрами алгоритма являются:
eta — learning rate ,gamma — коэффициент затухания,epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,x0 — начальная точка,max_iter — максимальное количество итераций,eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении
max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше
eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle :
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value ( self , x : np .ndarray ) -> float :
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError ( )
def gradient ( self , x : np .ndarray ) -> np .ndarray :
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError ( )
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Задача F. Adam
Условие
Требуется реализовать на языке Python класс Adam, который описывает одноименный алгоритм и имеет следующий интерфейс
import numpy as np
class Adam :
'''Represents an Adam optimizer
Fields:
eta: learning rate
beta1: first moment decay rate
beta2: second moment decay rate
epsilon: smoothing term
'''
eta : float
beta1 : float
beta2 : float
epsilon : float
def __init__ ( self , * , eta : float = 0.1 , beta1 : float = 0.9 , beta2 : float = 0.999 , epsilon : float = 1e-8 ) :
'''Initalizes `eta`, `beta1` and `beta2` fields'''
raise NotImplementedError ( )
def optimize ( self , oracle : Oracle , x0 : np .ndarray , * ,
max_iter : int = 100 , eps : float = 1e-5 ) -> np .ndarray :
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError ( )
Параметрами алгоритма являются:
eta — learning rate ,beta1 — коэффициент затухания первого момента,beta2 — коэффициент затухания второго момента,epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,x0 — начальная точка,max_iter — максимальное количество итераций,eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении
max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше
eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle :
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value ( self , x : np .ndarray ) -> float :
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError ( )
def gradient ( self , x : np .ndarray ) -> np .ndarray :
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError ( )
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Задача G. Линейная регрессия. Основы
Условие
Требуется реализовать следующие функции на языке Python .
def linear_func(theta, x) # function value
def linear_func_all(theta, X) # 1-d np.array of function values of all rows of the matrix X
def mean_squared_error(theta, X, y) # MSE value of current regression
def grad_mean_squared_error(theta, X, y) # 1-d array of gradient by theta
theta — одномерный np.array
x — одномерный np.array
X — двумерный np.array. Каждая строка соответствует по размерности вектору theta
y — реальные значения предсказываемой величины
Матрица X M × N M N
Используется линейная функция вида: h θ (x ) = θ1 x 1 2 x 2 n x N
Mean squared error (MSE) как функция от θ : J (θ) = 1 M M ∑ i = 1 y i h θ (x (i ) ))2 x (i ) i X
Градиент функции MSE: ∇ J (θ) = { ∂ J ∂ θ1 ∂ J ∂ θ2 ∂ J ∂ θN
Пример
X = np.array([[1,2],[3,4],[4,5]])
theta = np.array([5, 6])
y = np.array([1, 2, 1])
linear_func_all(theta, X) # --> array([17, 39, 50])
mean_squared_error(theta, X, y) # --> 1342.0
grad_mean_squared_error(theta, X, y) # --> array([215.33333333, 283.33333333])
Формат выходных данных
Код должен содержать только реализацию функций.
Задача H. Найти линейную регрессию
Условие
Требуется реализовать функцию на языке Python , которая находит линейную регрессию заданных векторов, используя метрику MSE .
def fit_linear_regression(X, y) # np.array of linear regression coefs
X — двумерный np.array. Каждая строка соответствует отдельному примеру.
y — реальные значения предсказываемой величины
Формат выходных данных
Код должен содержать только реализацию функций.
Задача I. Entropy
Условие
Требуется реализовать на языке Python функцию, вычисляющую значение энтропии заданной выборки.
entropy y ) = − ∑ v = set y )p (v )log p (v )
где set y )y
import numpy as np
def entropy ( y : np .ndarray ) -> float :
"""Computes entropy value for labels `y`.
Arguments:
y: 1d array of integers, sample labels
Returns:
float, entropy value for labels `y`"""
pass
Функция принимает единственный параметр y — одномерный np.array, значения классов в обучающей выборке.
При решении задачи следует использовать натуральный логарифм.
Формат выходных данных
Код должен содержать только реализацию функции. Запрещено пользоваться любыми готовыми реализациями вычисления функции entropy.
Задача J. Gini
Условие
Требуется реализовать на языке Python функцию, вычисляющую значение gini impurity заданной выборки.
gini y ) = 1 − ∑ v = set y )p 2 v )
где set y )y
import numpy as np
def gini ( y : np .ndarray ) -> float :
"""Computes gini impurity value for labels `y`.
Arguments:
y: 1d array of integers, sample labels
Returns:
float, gini impurity value for labels `y`"""
pass
y — одномерный np.array — значения классов в выборке
Формат выходных данных
Код должен содержать только реализацию функции. Запрещено пользоваться любыми готовыми реализациями вычисления функции gini.
Примеры тестов
№
Стандартный вход
Стандартный выход
1
3 2 4 4 2 0 1 3 0 1
0.8
Задача K. Decision tree split
Условие
Требуется реализовать следующие функцию на языке Python .
def tree_split(X, y, criterion) # col, row of best split
X — двумерный np.array — обучающая выборка
y — одномерный np.array — значения классов в обучающей выборке
criterion — строковое значение — вид критерия 'var', 'gini' или 'entropy'
tree_split должен возвращать номер признака и номер значения из обучающей выборки, которое будет использоваться в качестве порогового
Таким образом, tree_split возвращает наилучшее бинарное разделение по правилу вида x col X [row , col ]
Формат выходных данных
Код должен содержать только реализацию функции.
Задача L. Lasso
Условие
Пусть имеется задача регрессии f (x ) = a ⋅ x + b ≈ y a |{a i a i ∈ a , a i 0 }| = k , 0 < k ⩽ |a | = m . При этом должно выполняться условие R 2 1 − n ∑ i = 1 y i f (X i 2 n ∑ i = 1 y i y 2 ⩾ s Lasso
Формат входных данных
Данные для обучения содержатся в файле . Качество модели будет рассчитано на скрытом наборе данных
Первая строка входных данных содержит натуральное число N N n m k s R 2 n m + 1 y
Формат выходных данных
Решение должно представлять собой текстовый файл содержащий N a b
Примеры тестов
№
Стандартный вход
Стандартный выход
1
1
10 5 1 0.8
-0.5 -0.26 -0.11 -0.66 0.49 -24.89
0.08 -0.38 0.6 1.29 0.42 62.2
0.82 0.12 0.54 1.33 -0.82 47.55
-0.36 0.54 -0.6 0.55 -0.01 -15.96
-0.91 -0.71 0.59 1.0 0.43 -11.11
-0.97 -0.78 0.2 -0.93 1.24 -17.04
0.29 0.77 -0.87 -0.05 -0.71 -38.97
0.19 -0.16 1.0 0.63 1.79 188.63
0.22 -2.38 3.0 0.22 -0.53 23.32
0.36 -0.84 1.05 -1.06 -0.06 15.31
43.69 0.0 10.48 16.86 46.25 6.39
Задача M. k-point crossover
Условие
Требуется на языке Python реализовать методы точечного кроссовера .
Функция single_point_crossover ( a , b , point )
Функция two_point_crossover ( a , b , first , second )
Функция k_point_crossover ( a , b , points )
Функции должны иметь следующий интерфейс
import numpy as np
def single_point_crossover ( a : np .ndarray , b : np .ndarray , point : int ) -> tuple [ np .ndarray , np .ndarray ] :
"""Performs single point crossover of `a` and `b` using `point` as crossover point.
Chromosomes to the right of the `point` are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
point: crossover point
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError ( )
def two_point_crossover ( a : np .ndarray , b : np .ndarray , first : int , second : int ) -> tuple [ np .ndarray , np .ndarray ] :
"""Performs two point crossover of `a` and `b` using `first` and `second` as crossover points.
Chromosomes between `first` and `second` are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
first: first crossover point
second: second crossover point
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError ( )
def k_point_crossover ( a : np .ndarray , b : np .ndarray , points : np .ndarray ) -> tuple [ np .ndarray , np .ndarray ] :
"""Performs k point crossover of `a` and `b` using `points` as crossover points.
Chromosomes between each even pair of points are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
points: one-dimensional array, crossover points
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError ( )
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию функций.
Примеры тестов
№
Стандартный вход
Стандартный выход
1
a = np .array ([ 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ])
b = np .array ([ 9 , 8 , 7 , 6 , 5 , 4 , 3 , 2 , 1 , 0 ])
prep = lambda x : ' ' .join ( map ( str , x ))
print ( * map ( prep , single_point_crossover ( a , b , 4 )) , '' , sep = ' \n ' )
print ( * map ( prep , two_point_crossover ( a , b , 2 , 7 )) , '' , sep = ' \n ' )
print ( * map ( prep , k_point_crossover ( a , b , np .array ([ 1 , 5 , 8 ]))) , '' , sep = ' \n ' )
0 1 2 3 4 4 3 2 1 0
9 8 7 6 5 5 6 7 8 9
0 1 2 6 5 4 3 7 8 9
9 8 7 3 4 5 6 2 1 0
0 1 7 6 5 5 6 7 8 0
9 8 2 3 4 4 3 2 1 9
Задача N. Stochastic universal sampling
Условие
Требуется на языке Python реализовать алгоритм Stochastic universal sampling
Функция должна иметь следующий интерфейс
import numpy as np
def sus ( fitness : np .ndarray , n : int , start : float ) -> list :
"""Selects exactly `n` indices of `fitness` using Stochastic universal sampling alpgorithm.
Args:
fitness: one-dimensional array, fitness values of the population, sorted in descending order
n: number of individuals to keep
start: minimal cumulative fitness value
Return:
Indices of the new population"""
raise NotImplementedError ( )
Параметрами функции являются:
fitness — одномерный массив значений функции приспособленности, отсортированный по убыванию,n — количество особей, которых нужно оставить,start — минимальное кумулятивное значение функции приспособленности.
Функция возвращает список индексов выбранных особей
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию функции.
Примеры тестов
№
Стандартный вход
Стандартный выход
1
fitness = np .array ([ 10 , 4 , 3 , 2 , 1 ])
print ( * fitness [ sus ( fitness , 3 , 6 )])
10 4 1
Задача O. Метод ближайших соседей. Основы
Условие
Требуется реализовать следующие функцию на языке Python .
def knn_predict_simple(X, y, x, k) # array of pairs -- class and number of votes of neighbors
X — двумерный np.array — обучающая выборка
y — реальные значения классов в обучающей выборке
x — одномерный np.array-- тестовый пример
k — количество соседей, которые нужно рассматривать
Функция возвращает массив пар (класс, количество голосов) только для классов которые встречаются среди k
Для поиска ближайшего примера использовать евклидово расстояние.
Формат выходных данных
Код должен содержать только реализацию функции.
Задача P. Leave-one-out (метод скользящего контроля)
Условие
Требуется реализовать функцию
leave-one-out score на языке Python .
Результат функции должен быть целочисленным, то есть его НЕ следует нормировать на размер выборки.
def loo_score(predict, X, y, k) # integer loo score for predict function
predict — функция predict(X, y, x, k) , обучающая некоторый алгоритм на выборке X, y с параметром k и дающая предсказание на примере x
X — двумерный np.array — обучающая выборка
y — реальные значения классов в обучающей выборке
k — количество соседей, которые нужно рассматривать
Формат выходных данных
Код должен содержать только реализацию функции.
Задача Q. Border ratio
Условие
Пусть на некотором наборе точек X = {x i n i = 1 x i ∈ R m f : R m N border ratio α(x ) = ∥x̂ − y ∥2 ∥ x − y ∥2 x ∈ X , где y = arg min y ∈ X , f (x ) ≠ f (y )x − y ∥2 x̂ = arg min x̂ ∈ X , f (x ) = f (x̂ )x̂ − y ∥2
Формат входных данных
Первая строка входного файла содержит натуральные числа n , m n m
Формат выходных данных
Выходной файл должен содержать n border ratio каждой точки с точностью не менее трёх знаков после запятой.
Ограничения
6 ⩽ n ⩽ 1500
2 ⩽ m ⩽ 50
Примеры тестов
№
Стандартный вход
Стандартный выход
1
6 2
0 0 0
0 2 1
1 2 0
4 2 1
3 0 1
4 0 0
0.5 1.0 1.0 0.5 1.0 1.0
2
10 2
0 0 0
0 2 0
4 2 0
6 2 0
4 4 1
6 1 1
6 6 1
0 5 2
0 6 2
0 7 2
0.6 1.0 1.0 1.0 1.0 1.0 0.25 1.0 0.75 0.6
Задача R. KMeans
Условие
Пусть задан некоторый набор точек X = {x i n i = 1 x i ∈ R m k KMeans
Формат входных данных
Первая строка входных данных содержит натуральные числа n , m , k , t n m 0 k − 1
Формат выходных данных
Выходной данные должны содержать n
Ограничения
6 ⩽ n ⩽ 1000
2 ⩽ m , k ⩽ 10
10 ⩽ t ⩽ 10 9
Примеры тестов
№
Стандартный вход
Стандартный выход
1
6 2 2 10
0 0 0
0 3 1
3 0 1
2 5 0
5 2 0
5 5 1
0
0
0
1
1
1
0.263s 0.004s 59