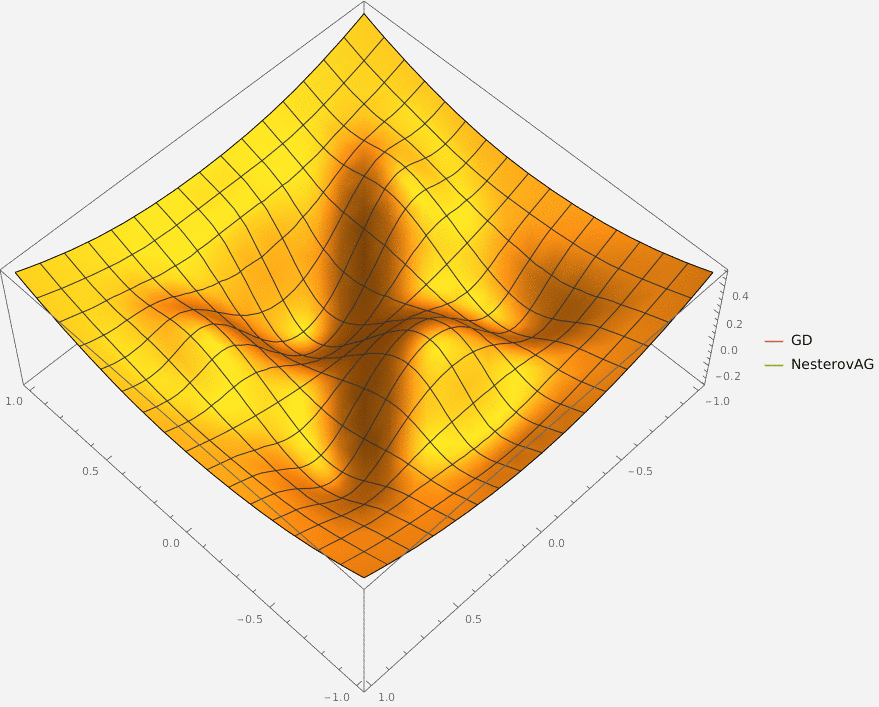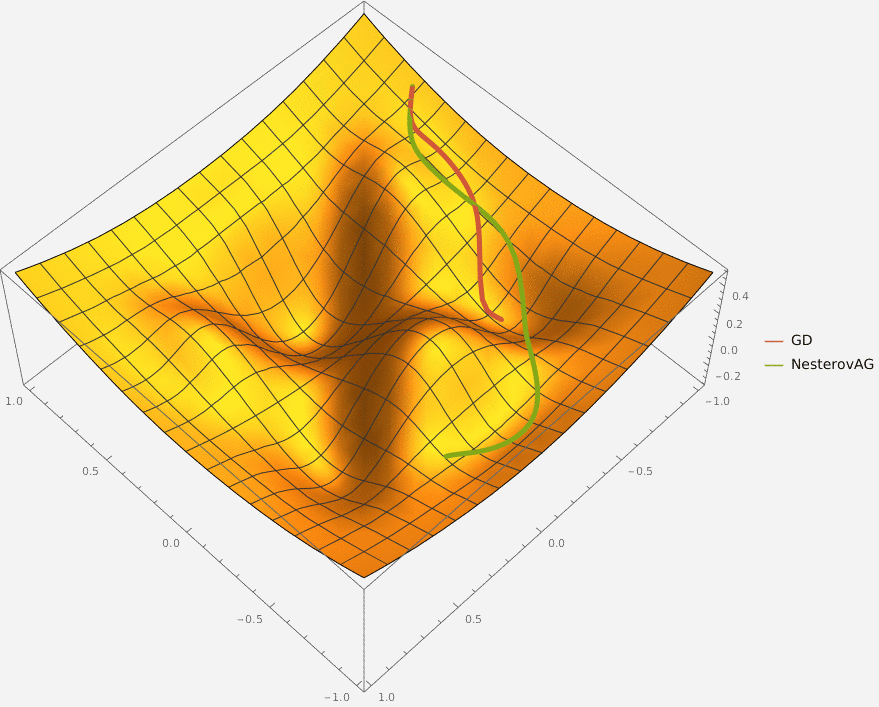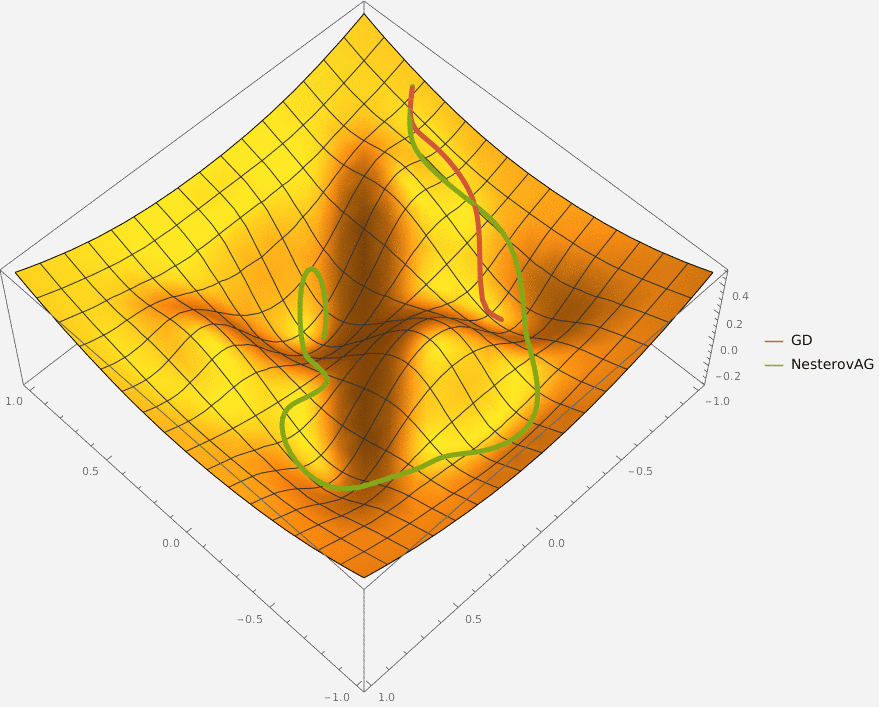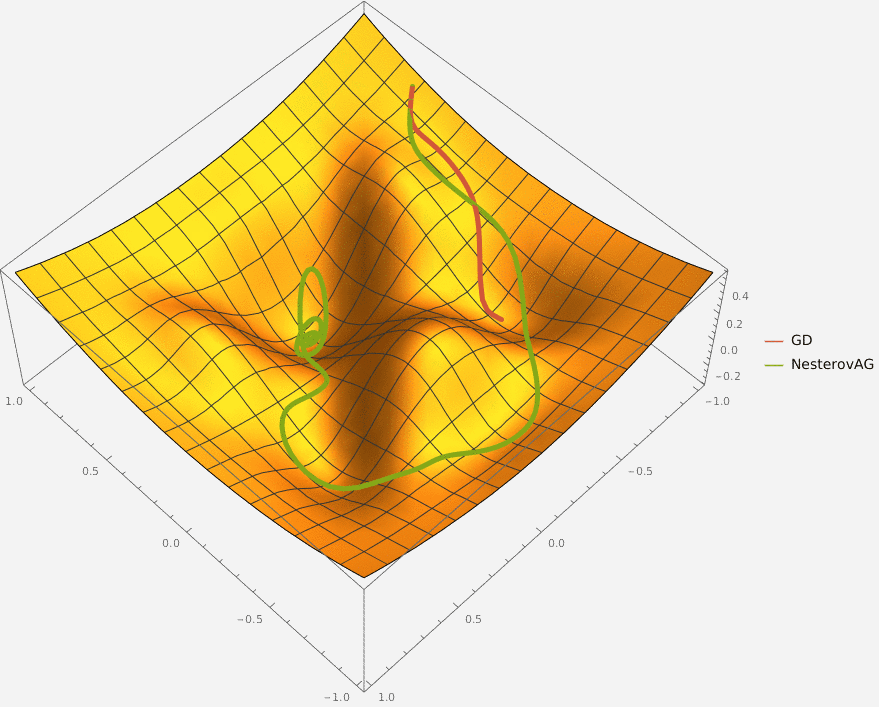
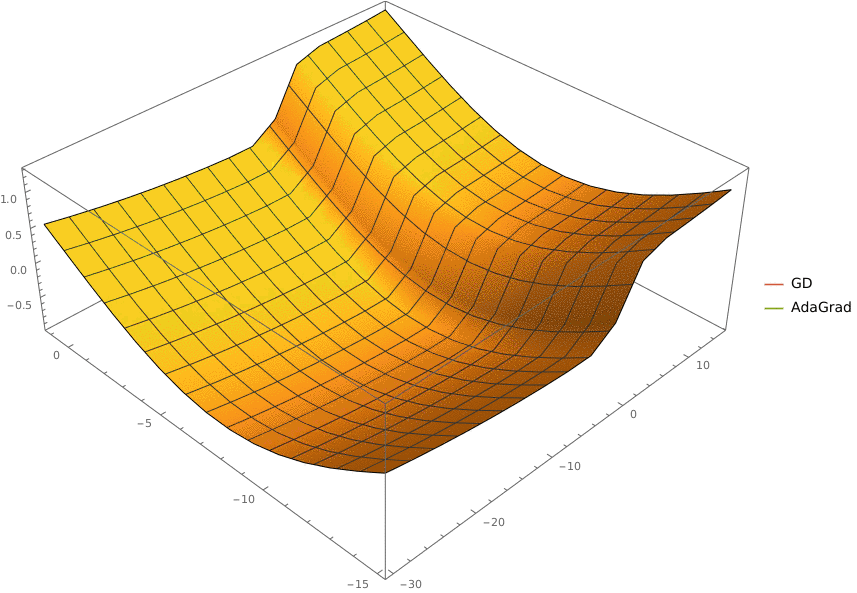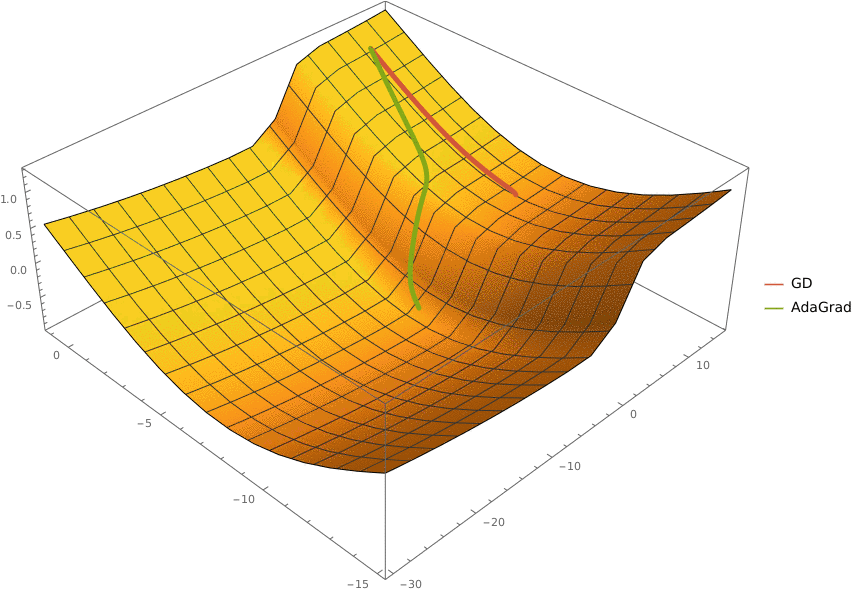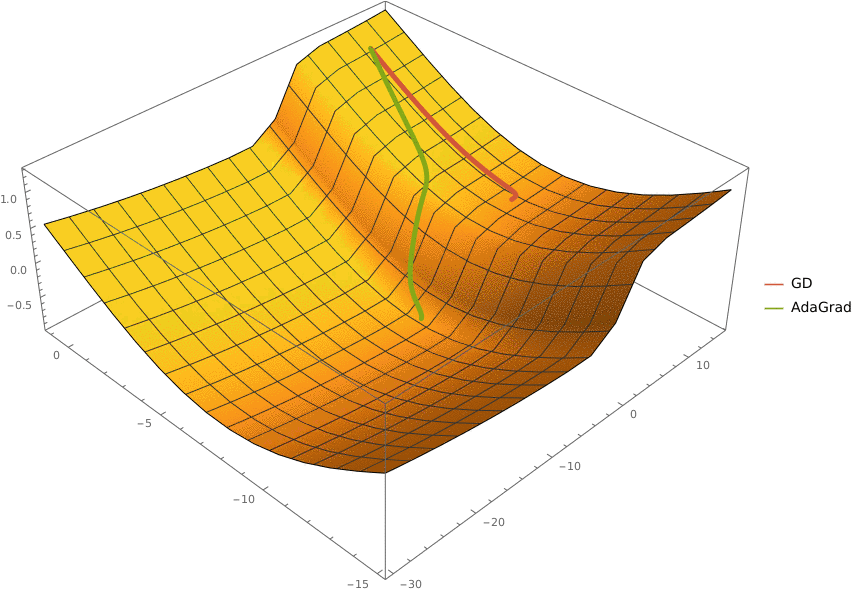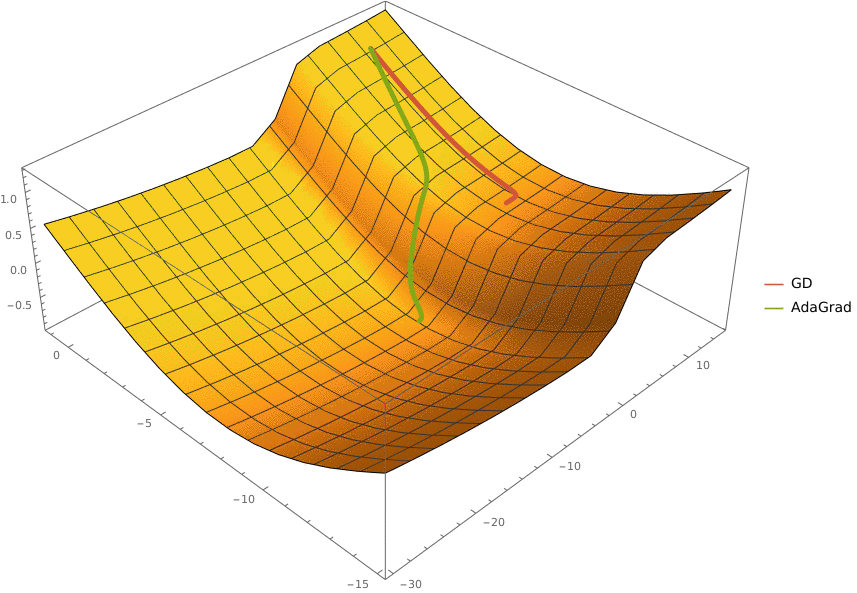
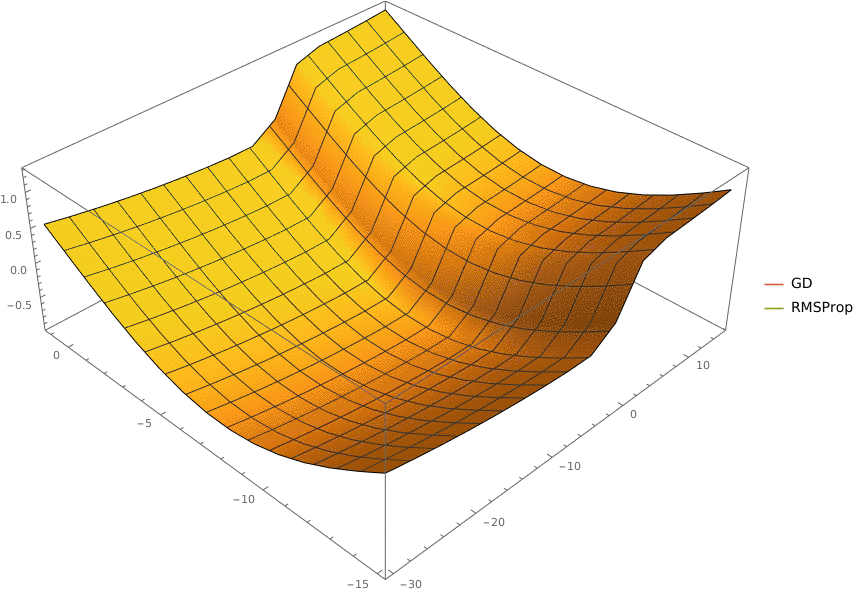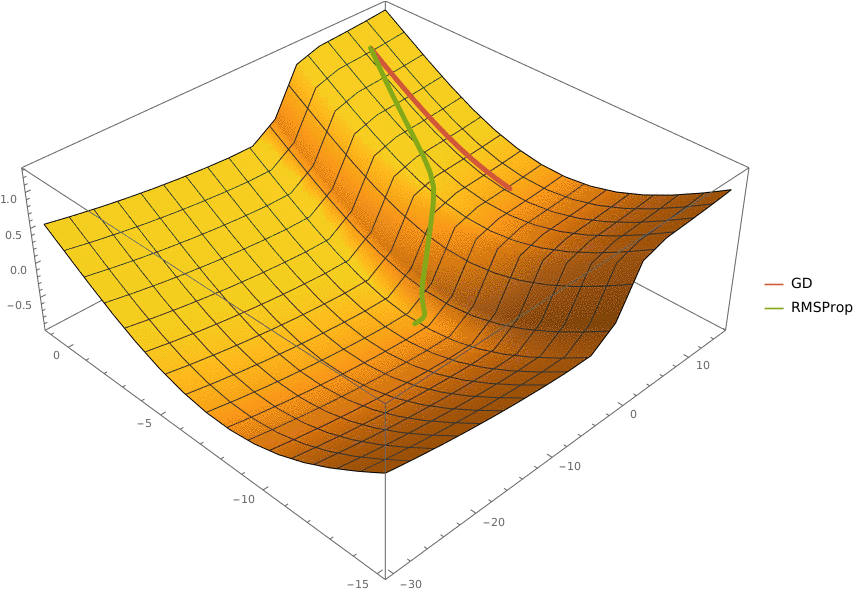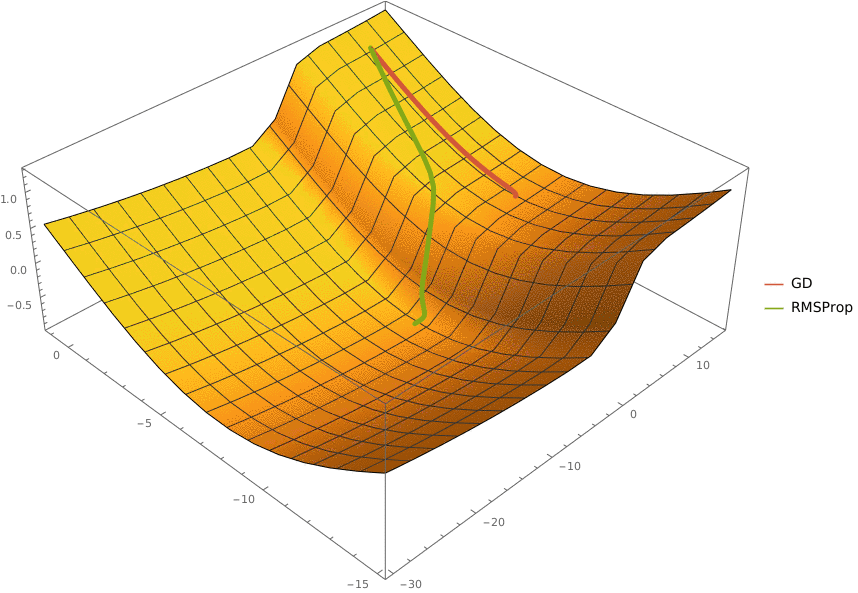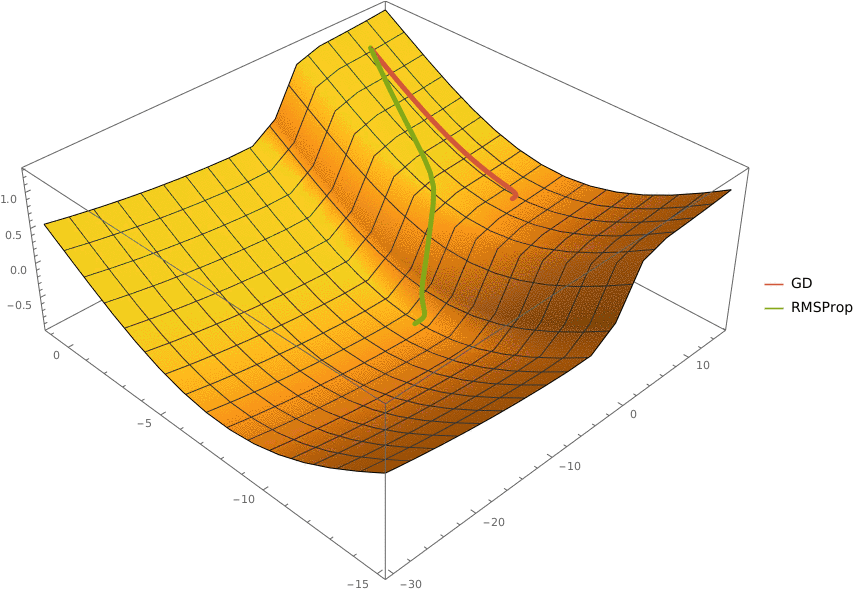
В конструктор принимаются два аргумента —
оракул, с помощью которого можно получить градиент оптимизируемой функции,
а также точку, с которой необходимо начать градиентный спуск.
Метод optimize принимает максимальное число итераций для критерия остановки,
L2-норму градиента, которую можно считать оптимальной,
а также learning rate. Метод возвращает оптимальную точку.
Оракул имеет следующий интерфейс:
class Oracle:
def get_func(self, x): pass
def get_grad(self, x): pass
x имеет тип np.array вещественных чисел.
Формат выходных данных
Код должен содержать только класс и его реализацию. Он не должен
ничего выводить на экран.
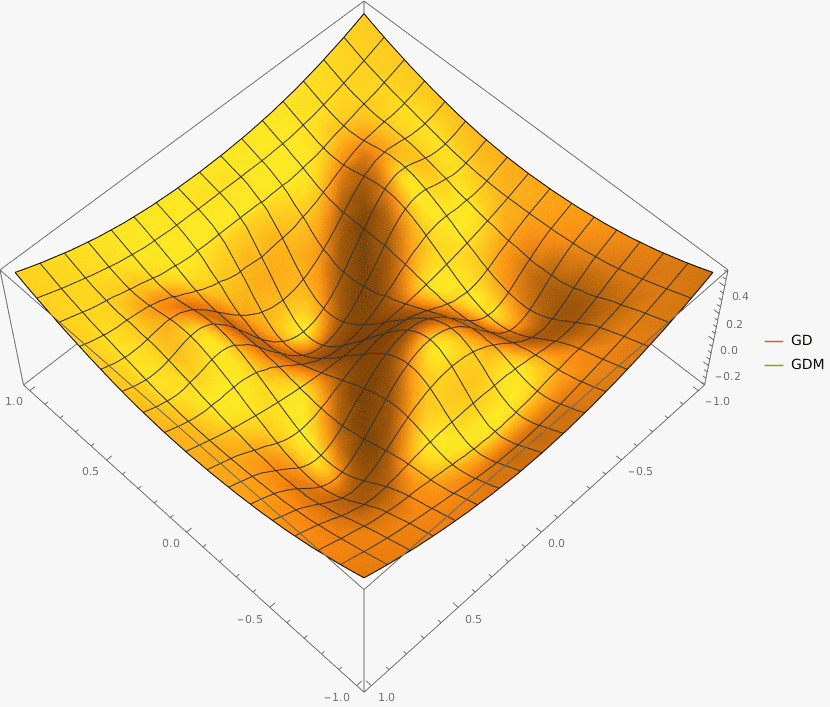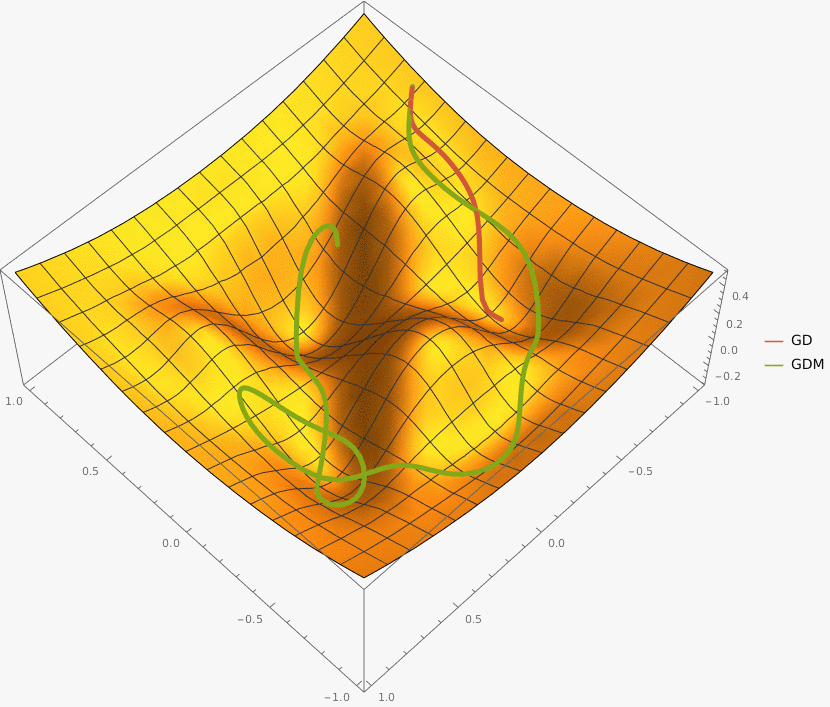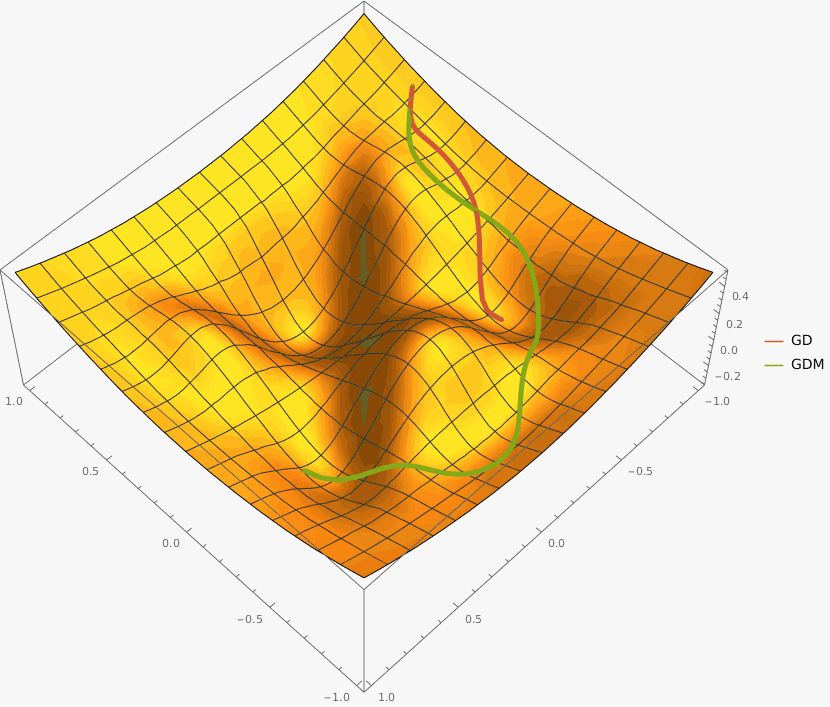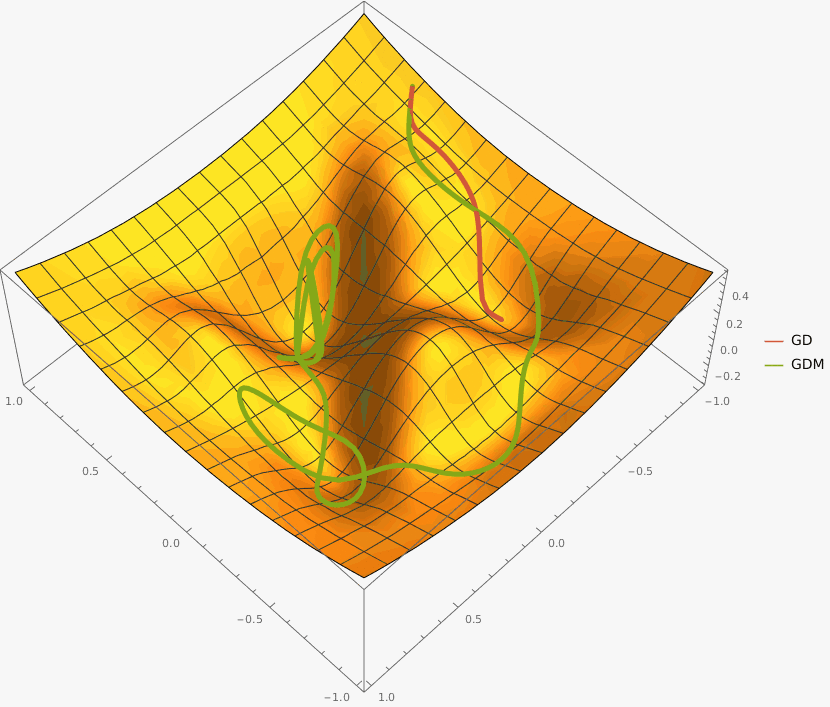
Требуется реализовать на языке Python класс GDM, который описывает алгоритм градиентного спуска с моментом и имеет следующий интерфейс:
import numpy as np
class GDM:
'''Represents a Gradient Descent with Momentum optimizer
Fields:
eta: learning rate
alpha: exponential decay factor
'''
eta: float
alpha: float
def __init__(self, *, alpha: float = 0.9, eta: float = 0.1):
'''Initalizes `eta` and `alpha` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
alpha — скорость затухания момента,
eta — learning rate.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию:
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс NesterovAG, который описывает алгоритм ускоренного градиента Нестерова и имеет следующий интерфейс
import numpy as np
class NesterovAG:
'''Represents a Nesterov Accelerated Gradient optimizer
Fields:
eta: learning rate
alpha: exponential decay factor
'''
eta: float
alpha: float
def __init__(self, *, alpha: float = 0.9, eta: float = 0.1):
'''Initalizes `eta` and `aplha` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the current gradient is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
alpha — скорость затухания момента,
eta — learning rate.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс AdaGrad, который описывает алгоритм адаптивного градиентного спуска и имеет следующий интерфейс
import numpy as np
class AdaGrad:
'''Represents an AdaGrad optimizer
Fields:
eta: learning rate
epsilon: smoothing term
'''
eta: float
epsilon: float
def __init__(self, *, eta: float = 0.1, epsilon: float = 1e-8):
'''Initalizes `eta` and `epsilon` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс RMSProp, который описывает одноименный алгоритм и имеет следующий интерфейс
import numpy as np
class RMSProp:
'''Represents an RMSProp optimizer
Fields:
eta: learning rate
gamma: exponential decay factor
epsilon: smoothing term
'''
eta: float
gamma: float
epsilon: float
def __init__(self, *, eta: float = 0.1, gamma: float = 0.9, epsilon: float = 1e-8):
'''Initalizes `eta`, `gamma` and `epsilon` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
gamma — коэффициент затухания,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать на языке Python класс Adam, который описывает одноименный алгоритм и имеет следующий интерфейс
import numpy as np
class Adam:
'''Represents an Adam optimizer
Fields:
eta: learning rate
beta1: first moment decay rate
beta2: second moment decay rate
epsilon: smoothing term
'''
eta: float
beta1: float
beta2: float
epsilon: float
def __init__(self, *, eta: float = 0.1, beta1: float = 0.9, beta2: float = 0.999, epsilon: float = 1e-8):
'''Initalizes `eta`, `beta1` and `beta2` fields'''
raise NotImplementedError()
def optimize(self, oracle: Oracle, x0: np.ndarray, *,
max_iter: int = 100, eps: float = 1e-5) -> np.ndarray:
'''Optimizes a function specified as `oracle` starting from point `x0`.
The optimizations stops when `max_iter` iterations were completed or
the L2-norm of the gradient at current point is less than `eps`
Args:
oracle: function to optimize
x0: point to start from
max_iter: maximal number of iterations
eps: threshold for L2-norm of gradient
Returns:
A point at which the optimization stopped
'''
raise NotImplementedError()
Параметрами алгоритма являются:
eta — learning rate,
beta1 — коэффициент затухания первого момента,
beta2 — коэффициент затухания второго момента,
epsilon — сглаживающий коэффициент.
Параметрами процесса оптимизации являются:
oracle — оптимизируемая функция,
x0 — начальная точка,
max_iter — максимальное количество итераций,
eps — пороговое значение L2 нормы градиента.
Оптимизация останавливается при достижении max_iter количества итераций или при достижении точки, в которой L2 норма градиента меньше eps.
Класс Oracle описывает оптимизируемую функцию
import numpy as np
class Oracle:
'''Provides an interface for evaluating a function and its derivative at arbitrary point'''
def value(self, x: np.ndarray) -> float:
'''Evaluates the underlying function at point `x`
Args:
x: a point to evaluate funciton at
Returns:
Function value
'''
raise NotImplementedError()
def gradient(self, x: np.ndarray) -> np.ndarray:
'''Evaluates the underlying function derivative at point `x`
Args:
x: a point to evaluate derivative at
Returns:
Function derivative
'''
raise NotImplementedError()
Формат выходных данных
Код решения должен содержать только определение и реализацию класса.
Требуется реализовать следующие функции на языке Python.
def linear_func(theta, x) # function value
def linear_func_all(theta, X) # 1-d np.array of function values of all rows of the matrix X
def mean_squared_error(theta, X, y) # MSE value of current regression
def grad_mean_squared_error(theta, X, y) # 1-d array of gradient by theta
theta — одномерный np.array
x — одномерный np.array
X — двумерный np.array. Каждая строка соответствует по размерности вектору theta
y — реальные значения предсказываемой величины
Матрица X имеет размер M × N. M строк и N столбцов.
Используется линейная функция вида: hθ(x) = θ1x1 + θ2x2 + ... + θnxN
Mean squared error (MSE) как функция от θ: J(θ) = 1MM∑i = 1(yi − hθ(x(i)))2. Где x(i) — i-я строка матрицы X
Пусть имеется задача регрессии f(x) = a⋅ x + b ≈ y. Требуется найти коэффициенты регрессии a, такие, что |{ai | ai∈ a, ai = 0}| = k, 0 < k ⩽ |a| = m. При этом должно выполняться условие R2 = 1 − n∑i = 1(yi − f(Xi))2n∑i = 1(yi − y)2⩾ s. При решении задачи предполагается использование алгоритма Lasso.
Формат входных данных
Данные для обучения содержатся в файле. Качество модели будет рассчитано на скрытом наборе данных
Первая строка входных данных содержит натуральное число N — количество тестов. В следующих N блоках содержится описание тестов. Первая строка блока содержит целые числа n — количество примеров обучающей выборки, m — размерность пространства, k — необходимое количество нулевых коэффициентов, и вещественное число s — минимальное значение метрики R2. Следующие n строк содержат по m + 1 вещественному числу — координаты точки пространства и значение целевой переменной y.
Формат выходных данных
Решение должно представлять собой текстовый файл содержащий N строк — коэффициенты a и b линейной регрессии разделённые символом пробел.
Функция single_point_crossover(a, b, point) выполняет одноточечный кроссовер, значения справа от точки кроссовера меняются местами.
Функция two_point_crossover(a, b, first, second) выполняет двухточечный кроссовер, значения между точек кроссовера меняются местами.
Функция k_point_crossover(a, b, points) выполняет k-точечный кроссовер, значения между каждой чётной парой точек меняются местами.
Функции должны иметь следующий интерфейс
import numpy as np
def single_point_crossover(a: np.ndarray, b: np.ndarray, point: int) -> tuple[np.ndarray, np.ndarray]:
"""Performs single point crossover of `a` and `b` using `point` as crossover point.
Chromosomes to the right of the `point` are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
point: crossover point
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError()
def two_point_crossover(a: np.ndarray, b: np.ndarray, first: int, second: int) -> tuple[np.ndarray, np.ndarray]:
"""Performs two point crossover of `a` and `b` using `first` and `second` as crossover points.
Chromosomes between `first` and `second` are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
first: first crossover point
second: second crossover point
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError()
def k_point_crossover(a: np.ndarray, b: np.ndarray, points: np.ndarray) -> tuple[np.ndarray, np.ndarray]:
"""Performs k point crossover of `a` and `b` using `points` as crossover points.
Chromosomes between each even pair of points are swapped
Args:
a: one-dimensional array, first parent
b: one-dimensional array, second parent
points: one-dimensional array, crossover points
Return:
Two np.ndarray objects -- the offspring"""
raise NotImplemetnedError()
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию функций.
import numpy as np
def sus(fitness: np.ndarray, n: int, start: float) -> list:
"""Selects exactly `n` indices of `fitness` using Stochastic universal sampling alpgorithm.
Args:
fitness: one-dimensional array, fitness values of the population, sorted in descending order
n: number of individuals to keep
start: minimal cumulative fitness value
Return:
Indices of the new population"""
raise NotImplementedError()
Параметрами функции являются:
fitness — одномерный массив значений функции приспособленности, отсортированный по убыванию,
n — количество особей, которых нужно оставить,
start — минимальное кумулятивное значение функции приспособленности.
Функция возвращает список индексов выбранных особей
Формат выходных данных
Код решения должен содержать импортируемые модули, определение и реализацию функции.
Требуется реализовать функцию
leave-one-out score на языке Python.
Результат функции должен быть целочисленным, то есть его НЕ следует нормировать на размер выборки.
def loo_score(predict, X, y, k) # integer loo score for predict function
predict — функция predict(X, y, x, k) , обучающая некоторый алгоритм на выборке X, y с параметром k и дающая предсказание на примере x
X — двумерный np.array — обучающая выборка
y — реальные значения классов в обучающей выборке
k — количество соседей, которые нужно рассматривать
Пусть на некотором наборе точек X = {xi}ni = 1, xi∈Rm задана функция f: Rm↦N. Требуется написать программу, вычисляющую значение border ratioα(x) = ∥x̂ − y∥2∥ x − y∥2, ∀ x∈ X, где y = argminy∈ X, f(x)≠ f(y)∥ x − y∥2, x̂ = argminx̂∈ X, f(x) = f(x̂)∥x̂ − y∥2.
Формат входных данных
Первая строка входного файла содержит натуральные числа n, m — количество точек и размерность пространства соответственно. В следующих n строках содержится m вещественных чисел и одно натуральное число — координаты точки и значение функции в этой точке.
Формат выходных данных
Выходной файл должен содержать n вещественных чисел — значения border ratio каждой точки с точностью не менее трёх знаков после запятой.
Пусть задан некоторый набор точек X = {xi}ni = 1, xi∈Rm.
Требуется выполнить кластеризацию точек на k кластеров,
используя наивный алгоритм
KMeans.
Формат входных данных
Первая строка входных данных содержит натуральные числа n, m, k, t —
количество точек, размерность пространства,
количество кластеров и максимальное количество итераций соответственно.
В каждой из следующих n строк содержится m вещественных чисел и
одно натуральное число — координаты точки и начальное значение кластера точки.
Значения кластеров нумеруются от 0 до k − 1.
Формат выходных данных
Выходной данные должны содержать n натуральных чисел — номер кластера каждой точки.