Рассмотрим все различные строки, которые могут быть получены путем циклического сдвига некоторой заданной строки S.
Отсортировав их в лексикографическом порядке, сформируем из них упорядоченную последовательность.
Требуется определить номер строки S в полученной последовательности.
При этом полагается, что элементы такой последовательности нумеруются с нуля.
Формат входного файла
В заголовке входного файла "input.txt" содержится единственная строка S, состоящая из цифр и строчных букв латинского алфавита.
Формат выходного файла
Выходной файл "output.txt" должен содержать порядковый номер исходной строки.
Пусть имеется набор из n точек, расположенных на поверхности цилиндра.
Каждая i-я точка задается своими цилиндрическими координатами: (zi, φi), где zi направлена вдоль вертикальной оси цилиндра, φi — полярный угол, указанный в радианах.
Требуется найти геодезическое расстояние между ближайшей парой таких точек, если известно, что радиус цилиндра равен 1.
Формат входного файла
Во входном файле "input.txt" записано натуральное число n, за которым следует ровно n пар вещественных чисел (zi, φi), отвечающих за координаты исходных точек.
Формат выходного файла
Выходной файл "output.txt" должен содержать ответ, записанный с точностью до 5-го знака после запятой.
При проведении конкурса творческих работ возникла необходимость в разработке онлайн-системы подсчета голосов.
На вход такой системе поступают запросы о начислении баллов (или штрафов) отдельным участникам соревнований.
После каждого такого запроса требуется выводить текущую информацию о первых трех (призовых) местах в командном зачете.
Полагается, что изначально всем участникам присваивается ноль баллов.
Далее за каждый отданный голос участнику начисляется по одному дополнительному баллу.
За нарушение правил могут начисляться штрафы (отрицательные баллы), размер которых по абсолютной величине никогда не превосходит числа имеющихся баллов.
При формировании рейтинга среди участников, имеющих равное количество баллов, на переднее место перемещается тот, за кого проголосовали в последнюю очередь.
Участники с нулевыми баллами в рейтинговой таблице не учитываются.
В этом случае допускается существование меньшего числа призовых мест (от нуля до трех).
Формат входного файла
В начале входного файла "input.txt" указано общее число участников n и количество поступающих запросов m.
Далее следует ровно m таких запросов, представленных в виде пар целых чисел: ai — номер участника; bi — начисленные баллы/штрафы.
При этом полагается, что нумерация участников начинается с нуля.
Формат выходного файла
Выходной файл "output.txt" должен содержать результаты выполнения каждого отдельного запроса, записанные в следующем виде.
Вначале указывается число доступных призовых мест (не более трех).
Далее записываются номера соответствующих им участников.
Начинающий программист Вася занимается разработкой системы, отвечающей за анимацию подвижных частиц.
Известно, что каждая такая частица должна двигаться вдоль ломаной линии, которая в моменты времени ti проходит через установленные точки с координатами: (xi, yi), где i = 0, 1, …, (n − 1).
При этом полагается, что на каждом интервале [ti, ti + 1] скорость частицы остается неизменной.
В свою очередь, информация о положениях частицы в моменты времени ti в дальнейшем может уточняться.
Помимо всего прочего ему также требуется эффективным образом обрабатывать запросы следующих видов:
movixy — обновить координаты положения частицы в момент времени ti;
getab — вернуть расстояние, пройденное частицей за время [a, b].
Поскольку Вася еще недостаточно опытен в решении подобных задач, он обратился за помощью к Вам.
Формат входного файла
В начале входного файла "input.txt" записано натуральное n, за которым следует ровно 3 × n вещественных чисел (ti, xi, yi), определяющих изначальную траекторию.
Далее идет натуральное m, за которым следует ровно m запросов.
Формат выходного файла
Выходной файл "output.txt" должен содержать результаты выполнения каждого из get-запросов, указанные с точностью до 5-го знака после запятой.
Карта лабиринта, выступающего в качестве игрового поля, представлена в виде матрицы n × m клеток.
Каждая клетка маркируется одним из двух значений: свободное пространство либо непроходимый участок.
Полагается, что в процессе игры персонаж может передвигаться в одном из четырех направлений: вверх, вниз, вправо и влево, всегда при этом оставаясь в свободных клетках.
В лабиринте также могут встречаться закрытые комнаты, переходы между которыми остаются для персонажа недоступными.
Иначе говоря, находясь в одной из таких комнат, персонаж не сможет переместиться в любую другую стандартным для него способом.
Для некоторого заданного лабиринта требуется определить общее число закрытых комнат.
Формат входного файла
Во входном файле "input.txt" построчно хранится двумерный массив символов, представляющий собой карту лабиринта.
Свободные клетки в нем обозначаются пробелами (ASCII 32), в то время как все остальные выступают в качестве непроходимых участков.
Формат выходного файла
Выходной файл "output.txt" должен содержать полученное число комнат.
Частотный словарь представляет собой список слов некоторого выбранного языка, каждому из которых ставится в соответствие частота его встречаемости в исходном наборе текстов.
Пусть имеется последовательность слов, состоящих из цифр и букв латинского алфавита.
При этом полагается, что регистр их написания неважен (заглавные и строчные символы эквивалентны между собой).
Все прочие символы, включая пробелы и знаки препинания, играют роль разделителей.
Требуется составить частотный словарь на основе имеющегося текста, определив число вхождений каждого встречаемого в нем слова.
При решении задачи рекомендуется использовать двоичные деревья поиска, списки с пропусками либо хеш-таблицы.
Формат входного файла
Во входном файле "input.txt" содержится исходная последовательность из слов и разделительных символов.
Формат выходного файла
Выходной файл "output.txt" должен содержать все найденные слова (без повторений), приведенные к одному регистру и расположенные в лексикографическом порядке.
Напротив каждого такого слова (через пробел) указывается число его вхождений во входной файл.
Если результирующий словарь оказался пустым, в выходной файл выводится единственный символ пробела.
Ограничения
Полагается, что длина отдельно взятого слова составляет не более 10 символов.
Число уникальных слов, формирующих словарь, не превосходит 5 ⋅ 104.
Размер входного файла не превосходит 10 МБ.
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
This is the house that Jack built.
This is the cheese that lay in the house that Jack built.
This is the rat that ate the cheese
That lay in the house that Jack built.
This is the cat that chased the rat
That ate the cheese that lay in the house that Jack built.
This is the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the rooster that crowed in the morn
That woke the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the farmer sowing his corn
That kept the rooster that crowed in the morn
That woke the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the horse and the hound and the horn
That belonged to the farmer sowing his corn
That kept the rooster that crowed in the morn
That woke the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
all 15
and 11
ate 10
belonged 1
built 12
cat 9
chased 9
cheese 11
corn 2
cow 7
crowed 3
crumpled 7
dog 8
farmer 2
forlorn 6
his 2
horn 8
horse 1
hound 1
house 12
in 14
is 12
jack 12
judge 4
kept 2
kissed 5
lay 11
maiden 6
man 5
married 4
milked 6
morn 3
rat 10
rooster 3
shaven 4
shorn 4
sowing 2
tattered 5
that 81
the 90
this 12
to 1
torn 5
tossed 7
with 7
woke 3
worried 8
Оперативная память компьютера может быть представлена в виде массива байт, где адрес каждого байта определяется его позицией относительно начала такого массива.
В процессе своей работы различные программы могут запрашивать отдельные участки (блоки) памяти, которые должны выделяться и освобождаться по мере необходимости.
Требуется написать менеджер памяти, который хранит информацию о всех доступных блоках и отвечает за обработку запросов следующего вида.
Запрос на выделение памяти
Вначале выбирается свободный блок наименьшего размера, который может уместить запрашиваемый объем данных.
Если таких блоков несколько, среди них выбирается блок с наименьшим адресом (смещением).
При этом размещаемые в нем данные выравниваются по левому (нижнему) краю.
В этом случае адрес свободного пространства сдвигается вверх (в сторону окончания блока).
В качестве ответа в выходной поток следует вывести адрес выделенного блока.
В случае отказа от выделения памяти (если блок подходящего размера не был найден), в выходной поток выводится ' − 1'.
Запрос на удаление
Вначале выполняется поиск выделенного блока с заданным адресом.
Если такой блок был найден, он удаляется из таблицы (дополняя окружающее его свободное пространство), а в выходной поток выводится его размер.
В противном случае, выводится ' − 2'.
Формат входного файла
В начале входного файла "input.txt" хранятся два натуральных числа: L — доступный объем памяти и n — общее число запросов.
Далее следует ровно n строк, записанных в следующем формате:
new <размер_блока> — запрос на выделение;
del <адрес_блока> — запрос на удаление.
Формат выходного файла
Выходной файл "output.txt" должен содержать результаты выполнения каждого такого запроса.
Ограничения
Полагается, что адресация памяти начинается с нуля.
0 < L ≤ 109, 0 < n ≤ 105
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
1024
10
new 100
new 10
new 100
new 10
new 100
del 210
del 100
new 5
del 110
new 110
0
100
110
210
220
10
10
100
100
105
2
1024
10
new 1000
new 1000
del 0
new 128
del 45
new 256
new 360
del 128
del 128
new 200
Пусть имеется текстовая строка S, состоящая из цифр и букв латинского алфавита. При этом полагается, что регистр их написания неважен, т.е. заглавные и строчные символы эквивалентны между собой.
На основе указанной строки требуется сформировать словарь T, в котором отдельным ее подстрокам ставятся в соответствие некоторые числовые коды.
Описание вычислительной процедуры для получения таких кодов приводится ниже:
на начальном этапе алгоритма создадим пустой словарь T и заведем счетчик k = 0;
будем двигаться по заданной строке, читая ее символы слева направо;
находясь в начале очередного суффикса строки S, выберем наименьший непустой его префикс, который отсутствует в словаре T;
выбранный на предыдущем этапе префикс добавим в словарь, указав в качестве числового кода его порядковый номер k;
увеличим счетчик k на единицу;
дальнейший поиск продолжается с позиции, следующей после указанного префикса.
Если при попытке добавления очередной подстроки число записей в словаре превысит некоторое заданное n, словарь должен быть очищен.
Счетчик k при этом обнуляется.
Последний считанный символ (в окончании текущего префикса) возвращается в поток, и процедура возобновляется с той же позиции, в которой она остановилась.
В качестве ответа требуется вывести содержимое такого словаря на момент окончания входной строки.
Формат входного файла
В первой строке входного файла "input.txt" записано натуральное число n.
Далее следует строка S, для которой необходимо построить словарь.
Формат выходного файла
В выходной файл "output.txt" нужно вывести все содержащиеся в словаре подстроки, приведенные к одному регистру и расположенные в лексикографическом порядке.
Напротив каждой такой строки (через пробел) следует указать ее порядковый номер.
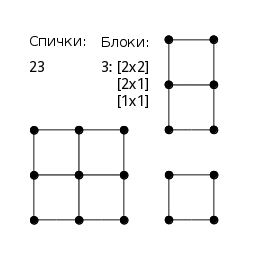
Пусть имеется n спичек равной длины.
Из указанных спичек необходимо собрать набор прямоугольных блоков, каждый из которых представляет собой двумерную матрицу квадратных ячеек (см. рисунок).
При этом каждое ребро в таком блоке соответствует ровно одной спичке.
Таким образом, полученный блок однозначно определяется своей конфигурацией [A × B], где A и B — размеры его сторон.
Блоки, совпадающие с точностью до поворота, считаются одинаковыми, т.е. [A × B] = [B × A].
Требуется вывести все уникальные комбинации прямоугольных блоков, которые можно составить из заданного числа спичек.
При этом каждая такая комбинация должна включать в себя все имеющиеся спички.
Комбинации, различающиеся только лишь порядком следования составляющих их блоков, полагаются тождественными и не должны встречаться более одного раза.
Формат входного файла
Входной файл "input.txt" содержит исходное число спичек n.
Формат выходного файла
Выходной файл "output.txt" должен содержать все найденные комбинации, представленные в следующем формате:
вначале указывается число блоков в текущей комбинации k;
далее следует ровно k пар натуральных чисел, определяющих конфигурации имеющихся блоков.
В случае, если подходящие комбинации не были найдены,
выходной файл следует оставить пустым.
В рамках одного научно-исследовательского проекта возникла необходимость в эффективной передаче экспериментальных данных, имеющих специальный вид, между различными узлами вычислительной сети.
В связи с этим была сформулирована следующая задача.
Пусть имеется некоторая бинарная последовательность (состоящая из нулей и единиц), разбитая на блоки фиксированной длины.
При этом заранее известно, что каждый такой блок содержит в себе ровно n нулей и m единиц.
При передаче указанной последовательности по внешнему каналу связи требуется представить ее в сжатом виде.
Для этого рассмотрим множество всех различных значений, которые могут принимать составляющие ее блоки.
Отсортировав их в лексикографическом порядке, получим некоторый упорядоченный алфавит.
Далее заменим каждый отдельный блок входной последовательности числовым кодом, указывающим его позицию в таком алфавите (будем полагать, что нумерация символов алфавита начинается с нуля).
Несложно показать, что размер полученного алфавита обратно пропорционален значению |n − m|.
Так, в предельном случае, когда n (или m) равно нулю, алфавит будет состоять всего-лишь из одного символа.
В свою очередь, чем меньше размер алфавита, тем меньшее число бит будет требоваться для представления номеров содержащихся в нем символов.
Если предположить, что во входной последовательности преобладают нулевые (либо единичные) биты, тогда от предложенного подхода можно будет ожидать достаточно высокой степени сжатия.
Формат входного файла
В первой строке входного файла "input.txt" записаны два целых неотрицательных числа n и m.
Далее следует текстовая строка, состоящая из n нулей и m единиц.
Формат выходного файла
Выходной файл "output.txt" должен содержать результирующий код указанной строки, представленный в двоичной системе счисления (ведущие нули при этом можно опустить).
Пусть имеется формальный язык, слова которого представляют собой цепочки символов, составленные из отдельных неперекрывающихся подцепочек (морфов).
Значения, которые способны принимать указанные морфы, образуют словарь базовых единиц (основ) исходного языка.
При этом полагается, что никакие две основы не могут иметь общих префиксов.
Для заданного набора слов требуется определить список основ, разбивающих их на минимально возможное число морфов.
Для каждой такой основы необходимо также посчитать, сколько раз она встречается в исходном тексте (в качестве значения какого-либо морфа).
Формат входного файла
В начале входного файла "input.txt" хранится натуральное число n.
Далее следует набор из n слов, состоящих из цифр и букв латинского алфавита (регистр их написания неважен).
При этом каждое слово располагается в отдельной строке.
Формат выходного файла
Выходной файл "output.txt" должен содержать все найденные основы (без повторений), приведенные к одному регистру и расположенные в лексикографическом порядке.
Напротив каждой такой основы (через пробел) указывается число совпадающих с ней морфов.
Ограничения
Полагается, что длина отдельно взятого слова лежит в диапазоне от 1 до 5000.
Палиндромом называется строка символов, которая одинаково читается в обоих направлениях (слева направо и справа налево).
Пусть имеется произвольная строка S.
Рассмотрим упорядоченный список всех различных палиндромов, которые могут быть получены через операции удаления и перестановки символов в исходной строке.
Из указанного списка требуется исключить палиндромы, лексикографический порядок которых меньше, чем у некоторой заданной строки T.
Если после этого его длина окажется больше n, лишние (с конца) палиндромы также следует удалить.
Формат входного файла
В заголовке входного файла "input.txt" содержатся две строки S и T, состоящие из цифр и строчных букв латинского алфавита.
За ними следует натуральное число n.
Формат выходного файла
Выходной файл "output.txt" должен содержать все оставшиеся палиндромы, расположенные в лексикографическом порядке.
В случае если их число равно нулю, выходной файл следует оставить пустым.
Ограничения
0 < |T| ≤ |S| ≤ 100,
0 < n ≤ 2 ⋅ 104
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
abcbac
aca
15
aca
acbbca
acbca
acca
b
baab
bab
bacab
baccab
bb
bcaacb
bcacb
bcb
bccb
c
Вася изобрел устройство, работающее по принципу конечного автомата.
На вход ему подается циклическая цепочка (строка) символов, по которой двигается специальный указатель.
За один такт устройства оно считывает символ, находящийся в текущей позиции указателя, и выполняет некоторое действие, определенное специальной таблицей команд.
Каждая i-я команда в такой таблице задается набором следующих значений: SiCiQiHi,
где Si — текущее состояние устройства;
Ci — символ в текущей позиции;
Qi — состояние, в которое следует перейти;
Hi указывает величину, на которую необходимо сдвинуть указатель (положительные значения — вправо, отрицательные — влево).
Известно также, что программа прекратит свою работу в одном из следующих случаев:
если указатель вернется в позицию, в которой он был ранее, приняв при этом то же состояние, что и на момент первого посещения;
если в таблице команд не будет найдено инструкции, соответствующей текущему состоянию и символу.
Для некоторой заданной строки и таблицы команд требуется определить начальные условия (номер позиции и состояние)
при которых указанное устройство выполнит максимально возможное число шагов.
Формат входного файла
В начале входного файла "input.txt" хранится строка T, состоящая из цифр и строчных символов латинского алфавита.
Далее указано натуральное число M, за которым следует ровно M команд, записанных в указанном выше формате.
Формат выходного файла
Выходной файл "output.txt" должен содержать номер стартовой позиции и начальное состояние.
При этом полагается, что нумерация позиций в строке начинается с нуля.
Ограничения
Гарантируется, что заданная программа является корректной
и не содержит взаимоисключающих инструкций.
Рассмотрим строку S, выступающую в качестве ключа в некотором симметричном алгоритме шифрования.
Для того, чтобы закодировать очередной символ входной последовательности, его необходимо переместить в начало такой строки путем ее циклического сдвига.
Стоимость каждого отдельного сдвига определяется числом пропущенных позиций.
Требуется определить набор циклических сдвигов строки S с наименьшей общей стоимостью, необходимых для того, чтобы последовательно закодировать заданный набор символов T.
Формат входного файла
В начале входного файла "input.txt" записана строка S.
Далее следует последовательность символов T, которую необходимо закодировать.
Формат выходного файла
Выходной файл "output.txt" должен содержать последовательность сдвигов строки S, оптимальным образом кодирующих строку T.
При этом сдвиги вправо обозначаются положительными числами, влево — отрицательными.
Ограничения
Полагается, что обе строки состоят из цифр и строчных букв латинского алфавита.
При этом строка T не может содержать символы, отсутствующие в строке S.
Вася устроился шеф-поваром в один из элитных ресторанов.
Каждый день он вынужден обслуживать большое число клиентов, которые зачастую бывают очень привередливы в своих вкусовых предпочтениях.
Одной из важнейших особенностей его блюд являются разного рода специи.
Каждому клиенту, в соответствии с его вкусом, требуется определенное количество специй каждого вида.
Если же в его блюдо положить недостаточное количество специй, он останется крайне недоволен.
По причине того, что в отдельно взятый период времени на кухне существует некоторое ограниченное количество специй, порой бывает невозможно должным образом обслужить всех клиентов.
В связи с этим Вася обратился к Вам с просьбой помочь ему минимизировать число недовольных клиентов.
Формат входного файла
В начале входного файла "input.txt" записано число разных видов специй M, за которым следует ровно M целых чисел Aj, указывающих количество специй каждого вида.
Далее следует N — число гостей, и матрица Pij — в которой каждому i-му гостю приписано число специй j-го вида, которое ему требуется.
Формат выходного файла
Выходной файл "output.txt" должен содержать порядковые номера гостей, которых удастся обслужить.
При этом полагается, что нумерация гостей начинается с нуля.
Ограничения
Все входные значения являются целыми десятичными числами.
Consider the directory that contains files.
Names of these files are composed from Latin letters (uppercase A-Z and lowercase a-z letters are distinct), digits, such characters as '-' (ASCII 45), '.' (ASCII 46) and spaces (ASCII 32).
Different files have different names.
Initial content of any file is unique.
In future it can not be changed, but it can be copied to a new file.
There is need to periodically synchronize the local version of this directory with its backup copy that is placed on remote server.
In this case the previous version of the remote directory must be updated to the current state with minimal computational costs.
For this purpose all operations that are performed in the local directory are stored to in a special log, in historical order.
This log contains records in following forms:
cpy "source" "target" — file "source" was copied to "target";
mov "source" "target" — file "source" was moved to "target";
new "target" — file "target" was created;
del "target" — file "target" was deleted.
It is known that these operations cause error if:
the source that is specified for cpy or mov does not exist;
the target that is specified for cpy, mov or new exists;
the target that is specified for del does not exist.
To update of the remote directory, we must apply similar operations to it.
In this case each of them has a certain cost: for mov and del it is 1, cost of cpy is 10.
Also we assume that operation new means to copy a file from the local directory to remote server and has cost is 100.
Your program must, given the initial state of remote directory and set of records of the log, obtain sequence of the operations with minimal total cost that allow to make update of the backup copy to the current state.
These operations must not cause errors.
Special file name "~" (ASCII 126) is considered acceptable by remote server, but is not used by operations in the log.
It is recommended to use this name for temporary file copies.
Input file format
Input file contains integer N — initial number of files in the directory, followed by the N file names enclosed in double quotes, one name per line.
After that, input file contains integer M — number of the records of the log, followed by M log records, one record per line.
All file names are enclosed in double quotes.
Output file format
Output file must contain integer L — number of the operations, followed by L operations in the same format as log records, one operation per line.
All file names must be enclosed in double quotes.
Constraints
File names have length from 1 to 16 characters.
Operations in the log do not cause errors.
0 ≤ N, M ≤ 104
Sample tests
No.
Input file (input.txt)
Output file (output.txt)
1
5
"BaNaNa-145"
"Example-01"
"MyMusic-03"
"MyGame.exe"
"UNIT.1.pas"
10
mov "MyMusic-03" "BestMusic.mp3"
mov "MyGame.exe" "F0"
mov "BaNaNa-145" "MyMusic-03"
del "Example-01"
cpy "UNIT.1.pas" "UNIT.2.pas"
del "UNIT.1.pas"
mov "F0" "BaNaNa-145"
new "x2"
mov "BestMusic.mp3" "MyGame.exe"
new "UNIT.1.pas"
8
mov "BaNaNa-145" "~"
mov "MyGame.exe" "BaNaNa-145"
mov "MyMusic-03" "MyGame.exe"
mov "~" "MyMusic-03"
del "Example-01"
mov "UNIT.1.pas" "UNIT.2.pas"
new "x2"
new "UNIT.1.pas"
2
5
"BaNaNa-145"
"Example-01"
"MyMusic-03"
"MyGame.exe"
"UNIT.1.pas"
10
mov "BaNaNa-145" "BaNaNa-360"
cpy "MyMusic-03" "M0"
cpy "BaNaNa-360" "NaN.InF"
mov "NaN.InF" "BaNaNa-145"
new "x2"
del "BaNaNa-360"
mov "M0" "Music.mp3"
del "MyMusic-03"
mov "Music.mp3" "MyMusic-03"
del "x2"
Пусть имеется корневое дерево, узлам которого ранее был приписан определенный набор цветов.
Каждый нелистовой узел такого дерева содержит произвольное число ссылок на своих потомков.
При этом полагается, что порядок их следования имеет значение.
В исходном дереве могут встречаться поддеревья, обладающие одинаковой структурой.
Здесь используется тот факт, что с точки зрения стороннего наблюдателя, два дерева считаются тождественными, если их корни окрашены в одинаковые цвета и все соответствующие потомки тождественны между собой.
Как следствие, ссылки на указанные поддеревья также являются взаимозаменяемыми.
Для экономии памяти, исходное дерево следует представить в сжатом виде.
С этой целью требуется расставить ссылки на потомков таким образом, чтобы минимизировать число узлов в полученном графе, сохранив при этом структуру исходного дерева.
Формат входного файла
Во входном файле "input.txt" хранится дерево, представленное в следующем виде.
Вначале идет цвет корневого узла, после которого (через пробел) указывается число его прямых потомков.
Затем следует упорядоченный набор таких потомков, записанных аналогичным образом.
Для обозначения цветов здесь используются цифры и строчные буквы латинского алфавита.
Каждому узлу также ставится в соответствие его порядковый номер (начиная с нуля).
Формат выходного файла
Выходной файл "output.txt" должен содержать пары значений: номер старого узла и номер узла, на который его следует заменить.
При этом корень дерева (узел с нулевым индексом) является не перемещаемым.
В случае если сжатие не может быть выполнено, выходной файл следует оставить пустым.
Ограничения
Полагается, что каждый узел имеет не более 10 потомков.
При этом общее число узлов не превосходит 2 ⋅ 105.
У одной инженерной компании, занимающейся прокладкой труб холодного водоснабжения, возникла необходимость в оптимизации потенциальных затрат на постройку очередного водопровода.
Решение указанной задачи, естественно, возложили на программистов.
В качестве входных данных им выдали карту, представленную в виде взвешенного графа, вершины которого отвечают за населенные пункты (с расположенными в них распределительными станциями), а ребра обозначают соединяющие их магистрали.
Каждое ребро имеет вес, указывающий длину соответствующей магистрали.
Для того, чтобы обеспечить водой даже самые труднодоступные районы, требуется построить распределенную сеть из водонапорных труб, проходящую через все указанные пункты.
При этом сами трубы должны пролегать строго вдоль выделенных магистралей.
В целях экономии ресурсов также необходимо чтобы такая сеть имела минимально возможную длину.
При решении задачи следует полагать, что в полученной сети существует всего лишь один источник воды, от которого будут запитываться все остальные узлы.
Формат входного файла
В начале входного файла "input.txt" записаны два натуральных числа: n — число вершин и m — число соединяющих их ребер.
Далее следует набор из m таких ребер, каждое из которых представлено тройкой целых чисел: (ai, bi) — номера вершин, wi — вес ребра.
При этом полагается, что нумерация вершин начинается с нуля.
Формат выходного файла
В выходной файл "output.txt" следует вывести номера тех ребер, через которые должен пройти водопровод.
При этом полагается, что нумерация ребер начинается с нуля.
Ограничения
Гарантируется, что исходный граф является связным, т.е. между любой парой его вершин можно проложить маршрут.
Караван купцов движется из города S в город F. Их маршрут должен пройти через города, соединенные между собой прямыми путями.
Известно, что за проход через отдельно взятый город купцам придется платить некоторую установленную пошлину.
Помимо этого за каждую единицу пути, караван тратит определенное число ресурсов, также выраженных в денежном эквиваленте.
Требуется проложить маршрут, минимизирующий суммарную пошлину и число затраченных ресурсов.
В случае, если существует несколько таких маршрутов, необходимо выбрать тот, который проходит через наибольшее число городов.
Формат входного файла
В начале входного файла "input.txt" указано натуральное N — число городов, за которым следует набор из N целых чисел
Pi — размер пошлины для каждого i-го города.
Далее указано натуральное M, за которым следует ровно M троек целых чисел:
Aj, Bj — номера соседних городов;
Wj — стоимость перехода.
В конце входного файла указаны индексы начального S и конечного F города.
При этом полагается, что нумерация городов начинается с нуля.
Формат выходного файла
Выходной файл "output.txt" должен содержать оптимальный маршрут,
представленный в виде последовательности городов,
через которые он проходит.
Пусть имеется неориентированный граф, по ребрам которого движутся два гонщика (игрока).
Каждому ребру такого графа ставится в соответствие целый положительный вес, обозначающий его длину.
Полагается, что за одну единицу времени каждый гонщик проходит ровно одну единицу пути.
Известно, что первый игрок изначально выбирает оптимальный для себя маршрут.
В случае, если для него существует несколько таких маршрутов, он может выбрать любой из них.
Второй игрок задумал перехватить своего соперника до того, как тот достигнет финишной вершины.
С этой целью он хочет дождаться его в одной из промежуточных вершин.
Чтобы помочь 2-му игроку, необходимо определить номера тех вершин, через которые гарантированно (независимо от выбранного пути) пройдет 1-й игрок.
После чего из числа таких вершин выбрать те, до которых 2-й игрок сможет добраться не позднее, чем это сделает 1-й.
Формат входного файла
В начале входного файла "input.txt" записаны два натуральных числа:
n — число вершин и m — число соединяющих их ребер.
Далее следует набор из m таких ребер, каждое из которых представлено тройкой целых чисел:
(ai, bi) — номера вершин, wi — вес ребра.
При этом полагается, что нумерация вершин начинается с нуля.
В конце входного файла хранятся три числа f, p1 и p2, указывающие номер финишной вершины и стартовые позиции каждого из игроков.
Формат выходного файла
Выходной файл "output.txt" должен содержать список из номеров вершин, удовлетворяющих условию задачи.
В случае, если таковых нет, выходной файл следует оставить пустым.
Ограничения
Гарантируется, что исходный граф является связным.