В рамках одного научно-исследовательского проекта возникла необходимость в эффективной передаче экспериментальных данных, имеющих специальный вид, между различными узлами вычислительной сети.
В связи с этим была сформулирована следующая задача.
Пусть имеется некоторая бинарная последовательность (состоящая из нулей и единиц), разбитая на блоки фиксированной длины.
При этом заранее известно, что каждый такой блок содержит в себе ровно n нулей и m единиц.
При передаче указанной последовательности по внешнему каналу связи требуется представить ее в сжатом виде.
Для этого рассмотрим множество всех различных значений, которые могут принимать составляющие ее блоки.
Отсортировав их в лексикографическом порядке, получим некоторый упорядоченный алфавит.
Далее заменим каждый отдельный блок входной последовательности числовым кодом, указывающим его позицию в таком алфавите (будем полагать, что нумерация символов алфавита начинается с нуля).
Несложно показать, что размер полученного алфавита обратно пропорционален значению |n − m|.
Так, в предельном случае, когда n (или m) равно нулю, алфавит будет состоять всего-лишь из одного символа.
В свою очередь, чем меньше размер алфавита, тем меньшее число бит будет требоваться для представления номеров содержащихся в нем символов.
Если предположить, что во входной последовательности преобладают нулевые (либо единичные) биты, тогда от предложенного подхода можно будет ожидать достаточно высокой степени сжатия.
Формат входного файла
В первой строке входного файла "input.txt" записаны два целых неотрицательных числа n и m.
Далее следует текстовая строка, состоящая из n нулей и m единиц.
Формат выходного файла
Выходной файл "output.txt" должен содержать результирующий код указанной строки, представленный в двоичной системе счисления (ведущие нули при этом можно опустить).
Пусть имеется многочлен, представленный в следующем виде:
C0 ⋅ (x − C1) ⋅ … ⋅ (x − Cn), где все Ci принадлежат кольцу вычетов по некоторому заданному модулю p.
Требуется привести его к каноническому виду: A0 + A1 ⋅ x + … + An ⋅ xn.
Формат входного файла
В начале входного файла "input.txt" содержится значение модуля p и натуральное число n.
Далее следует набор значений Ci, где i = 0, 1, …, n.
Формат выходного файла
Выходной файл "output.txt" должен содержать массив коэффициентов Ai.
В рамках одного научного исследования по изучению псевдо-броуновского движения на плоскости возникла необходимость в моделировании поведения двумерных псевдо-частиц при их попадании в замкнутую ловушку, имеющую форму кольца.
Дело в том, что такого рода частицы в течение всей своей жизни совершают непрерывное прямолинейное движение с некоторой постоянной скоростью.
Когда частица сталкивается с каким-либо препятствием, она отклоняется от исходной траектории и продолжает свое движение, как ни в чем не бывало.
В очень редких случаях также могут встречаться абсолютно неподвижные частицы, скорости которых равны нулю.
Чтобы изучить подвижную псевдо-частицу, ее необходимо длительное время удерживать в некоторой ограниченной области.
Для этого в экспериментальной лаборатории воссоздаются условия при которых достаточно большой набор частиц окажется в пределах замкнутого кольца, граница которого образует силовой барьер, через который частицы не могут пройти.
Определим кольцо, как область, заключенную между двумя окружностями с общим центром (x0, y0) и разными радиусами: r2 > r1 > 0.
В этом случае исходное множество частиц можно условно разбить на три группы:
частицы, попадающие во внутренний круг с центром в точке (x0, y0) и радиусом r1 > 0;
частицы, заключенные между двумя окружностями с радиусами r1 и r2;
частицы, лежащие за пределами внешнего круга с радиусом r2 > r1.
Рассмотрим поведение указанных частиц на временном интервале от 0 до T.
В процессе своего движения каждая отдельно взятая частица может то и дело сталкиваться с границей содержащей ее области.
Будем полагать, что при столкновении частицы с границей она отражается относительно касательной прямой (как показано на рисунке).
Модуль ее скорости при этом сохраняется.
В свою очередь, взаимные столкновения двух и более частиц не влияют на их траектории и могут быть проигнорированы.
Требуется написать программу, которая по известному начальному положению частиц, исходным компонентам скорости и параметрам кольцевой области, производит расчет их траекторий в течение заданного промежутка времени.
В качестве ответа вывести координаты положения частиц в равноотстоящие моменты времени tk = k ⋅ (T / m), где k = 1, 2, …, m.
Важным условием здесь является то, что в процессе движения ни одна из частиц не должна покидать область, которой она принадлежала в начальный момент времени.
Данный факт следует также учесть при составлении проверочных тестов.
Формат входного файла
В первой строке входного файла "input.txt" содержатся параметры расчетной области: x0, y0, r1, r2.
Во второй строке указано значение T, задающее длину временного интервала, и число его подынтервалов m.
Далее следует натуральное число n и последовательность из 4 × n вещественных чисел, задающих начальные координаты и скорости каждой из частиц: xi, yi, ui, vi, где i = 1, 2, …, n.
Формат выходного файла
Выходной файл "output.txt" должен содержать координаты положения частиц в моменты времени tk (k = 1, 2, …, m), расположенные в том же порядке, что и во входном файле.
Все значения должны быть указаны с точностью до 5-го знака после запятой.
Ограничения
Полагается, что ни одна из частиц в начальный момент времени не лежит на границе кольца.
Пусть имеются две круглые плоские пластины, произвольным образом расположенные в трехмерном пространстве.
Каждая такая пластина однозначно задается ортогональным к ней вектором (Nxi, Nyi, Nzi), своим центром (Cxi, Cyi, Czi) и радиусом Ri.
Требуется определить наличие пересечения между указанными пластинами.
Будем считать, что пластины пересекаются, если у них имеется как минимум одна общая точка.
Формат входного файла
В начале входного файла "input.txt" хранится набор вещественных значений, задающих первую пластину: Nx1, Ny1, Nz1, Cx1, Cy1, Cz1, R1.
Далее следует такой же набор, задающий вторую пластину: Nx2, Ny2, Nz2, Cx2, Cy2, Cz2, R2.
Формат выходного файла
Выходной файл "output.txt" должен содержать:
1 — если заданные пластины пересекаются;
0 — в противном случае.
Ограничения
Гарантируется, что в пределах заданной
точности ответ может быть
получен однозначно.
Исходная строка, содержащая некоторое арифметическое выражение, состоит из набора символьных идентификаторов (выступающих в роли операндов), знаков операций ('+', '-', '*') и круглых скобок.
Между ними также допускается наличие разделителей из произвольного числа пробелов.
При этом знак минуса может обозначать как бинарную, так и унарную операцию.
Между любыми двумя знаками операций всегда присутствуют либо скобки, либо операнды.
Для записи операндов здесь используются строчные буквы латинского алфавита.
В указанном выражении требуется раскрыть скобки и выполнить приведение подобных слагаемых.
На выходе каждое такое слагаемое должно быть записано в следующем формате.
Вначале указывается целочисленный коэффициент (может быть опущен, если он равен единице),
за которым идет набор множителей. В качестве разделителя используется знак умножения '*'.
Каждому символу алфавита здесь должен соответствовать ровно один множитель.
Для обозначения кратных множителей используется знак возведения в степень '^',
за которым следует целое число, обозначающее его кратность.
При этом слагаемые, различающиеся только лишь порядком следования составляющих их множителей, полагаются тождественными и не должны встречаться более одного раза.
В свою очередь, слагаемые, перед которыми стоит нулевой коэффициент, а также множители, возведенные в нулевую степень, должны быть проигнорированы.
Формат входного файла
Входной файл "input.txt" содержит единственную строку с арифметическим выражением.
Формат выходного файла
Выходной файл "output.txt" должен содержать все полученные слагаемые, приведенные к требуемому виду и разделенные символами '+' либо '-'
(в зависимости от знаков стоящих перед ними коэффициентов).
Если полученное выражение тождественно равно нулю, в выходной файл выводится 0.
Ограничения
Полагается, что исходное выражение состоит не более чем из 25 арифметических операций и не содержит синтаксических ошибок.
Число открывающихся скобок ограничено и не превосходит 20.
Пусть имеется текстовая строка, содержащая запись составной математической функции.
В качестве операндов в ней выступают целые и вещественные константы (представленные в формате с десятичной точкой), а также переменный аргумент, обозначенный буквой 'x'.
Помимо этого, такая функция может включать в себя знаки арифметических операций ('+', '-', '*', '/', '^'), круглые скобки и элементарные функции (sqrt, log, exp, sin, cos).
При этом знак минуса может использоваться для обозначения как бинарной, так и унарной операции.
В свою очередь показателем степени может быть только натуральная целочисленная константа.
Аргументы всех элементарных функций в обязательном порядке заключаются в круглые скобки.
В указанном выражении также допускается наличие разделителей из произвольного числа пробелов.
Требуется получить выражение для производной указанной функции по аргументу 'x'.
Формат входного файла
Входной файл "input.txt" содержит строку, в которой записана исходная функция.
Формат выходного файла
Выходной файл "output.txt" должен содержать полученную производную.
Ограничения
Полагается, что исходная функция не содержит синтаксических ошибок.
Пусть имеется массив записей, поля которых могут принимать значения следующих типов: вещественные числа, знаковые и беззнаковые целые, символы и строки произвольной длины.
Для указанного массива требуется выполнить процедуру сортировки.
Две записи считаются равными, если все соответствующие поля у них имеют одинаковые значения.
В противном случае выполняется последовательное сравнение составляющих их полей в соответствии с установленными приоритетами.
Так, вначале выполняется сравнение полей с наивысшим приоритетом, и только в том случае, когда их значения совпадают, сравниваются поля с более низким приоритетом.
При этом полагается, что у двух различных полей не может быть одинаковых приоритетов.
При сравнении отдельных полей необходимо придерживаться следующих правил:
вещественные значения должны быть упорядочены по возрастанию;
знаковые целые — по убыванию;
беззнаковые — по возрастанию;
символьные значения — по убыванию своих позиций в таблице ASCII;
упорядочение строк производится по возрастанию (в лексикографическом порядке).
Формат входного файла
В первой строке входного файла "input.txt" содержится пара натуральных чисел n и m, указывающих общее количество таких записей и число их полей.
Во второй строке содержится массив из m символьных значений (разделенных пробелами), указывающих тип каждого поля в соответствии со следующей таблицей:
'd' — вещественное число, записанное с точностью до 5-го знака после запятой;
'i' — целое знаковое число, лежащее в диапазоне от -263 до 263-1;
'u' — целое беззнаковое число, лежащее в диапазоне от 0 до 264-1;
'c' — символьное значение (ASCII 32-126);
's' — строка (содержит от 0 до 24 символов).
Далее следует массив из m целых чисел pi, устанавливающих приоритеты указанных полей.
Начиная с четвертой строки располагается массив записей.
При этом значение каждого поля занимает ровно одну строку.
Формат выходного файла
Выходной файл "output.txt" должен содержать индексы исходных записей, расположенные в порядке их следования в отсортированном массиве.
При этом полагается, что нумерация записей в исходном массиве начинается с нуля.
Ограничения
n ≤ 2 ⋅ 104, m ≤ 10, 0 ≤ pi < 10
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
5 4
i s d c
2 9 7 0
-1
QWERTY
3.90000
a
-9
ASUS
0.47000
t
75
QWERTY
0.10000
x
9
ASKOLD
8.05000
b
0
ASUS
-0.00075
y
3
4
1
2
0
2
5 4
i u d c
9 8 1 3
-1
48
-3.50000
a
-9
15
0.90000
w
-9
10
4.70000
b
-1
48
-0.70000
z
-1
48
1.56000
p
Частотный словарь представляет собой список слов некоторого выбранного языка, каждому из которых ставится в соответствие частота его встречаемости в исходном наборе текстов.
Пусть имеется последовательность слов, состоящих из цифр и букв латинского алфавита.
При этом полагается, что регистр их написания неважен (заглавные и строчные символы эквивалентны между собой).
Все прочие символы, включая пробелы и знаки препинания, играют роль разделителей.
Требуется составить частотный словарь на основе имеющегося текста, определив число вхождений каждого встречаемого в нем слова.
При решении задачи рекомендуется использовать двоичные деревья поиска, списки с пропусками либо хеш-таблицы.
Формат входного файла
Во входном файле "input.txt" содержится исходная последовательность из слов и разделительных символов.
Формат выходного файла
Выходной файл "output.txt" должен содержать все найденные слова (без повторений), приведенные к одному регистру и расположенные в лексикографическом порядке.
Напротив каждого такого слова (через пробел) указывается число его вхождений во входной файл.
Если результирующий словарь оказался пустым, в выходной файл выводится единственный символ пробела.
Ограничения
Полагается, что длина отдельно взятого слова составляет не более 10 символов.
Число уникальных слов, формирующих словарь, не превосходит 5 ⋅ 104.
Размер входного файла не превосходит 10 МБ.
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
This is the house that Jack built.
This is the cheese that lay in the house that Jack built.
This is the rat that ate the cheese
That lay in the house that Jack built.
This is the cat that chased the rat
That ate the cheese that lay in the house that Jack built.
This is the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the rooster that crowed in the morn
That woke the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the farmer sowing his corn
That kept the rooster that crowed in the morn
That woke the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the horse and the hound and the horn
That belonged to the farmer sowing his corn
That kept the rooster that crowed in the morn
That woke the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
all 15
and 11
ate 10
belonged 1
built 12
cat 9
chased 9
cheese 11
corn 2
cow 7
crowed 3
crumpled 7
dog 8
farmer 2
forlorn 6
his 2
horn 8
horse 1
hound 1
house 12
in 14
is 12
jack 12
judge 4
kept 2
kissed 5
lay 11
maiden 6
man 5
married 4
milked 6
morn 3
rat 10
rooster 3
shaven 4
shorn 4
sowing 2
tattered 5
that 81
the 90
this 12
to 1
torn 5
tossed 7
with 7
woke 3
worried 8
Consider the directory that contains files.
Names of these files are composed from Latin letters (uppercase A-Z and lowercase a-z letters are distinct), digits, such characters as '-' (ASCII 45), '.' (ASCII 46) and spaces (ASCII 32).
Different files have different names.
Initial content of any file is unique.
In future it can not be changed, but it can be copied to a new file.
There is need to periodically synchronize the local version of this directory with its backup copy that is placed on remote server.
In this case the previous version of the remote directory must be updated to the current state with minimal computational costs.
For this purpose all operations that are performed in the local directory are stored to in a special log, in historical order.
This log contains records in following forms:
cpy "source" "target" — file "source" was copied to "target";
mov "source" "target" — file "source" was moved to "target";
new "target" — file "target" was created;
del "target" — file "target" was deleted.
It is known that these operations cause error if:
the source that is specified for cpy or mov does not exist;
the target that is specified for cpy, mov or new exists;
the target that is specified for del does not exist.
To update of the remote directory, we must apply similar operations to it.
In this case each of them has a certain cost: for mov and del it is 1, cost of cpy is 10.
Also we assume that operation new means to copy a file from the local directory to remote server and has cost is 100.
Your program must, given the initial state of remote directory and set of records of the log, obtain sequence of the operations with minimal total cost that allow to make update of the backup copy to the current state.
These operations must not cause errors.
Special file name "~" (ASCII 126) is considered acceptable by remote server, but is not used by operations in the log.
It is recommended to use this name for temporary file copies.
Input file format
Input file contains integer N — initial number of files in the directory, followed by the N file names enclosed in double quotes, one name per line.
After that, input file contains integer M — number of the records of the log, followed by M log records, one record per line.
All file names are enclosed in double quotes.
Output file format
Output file must contain integer L — number of the operations, followed by L operations in the same format as log records, one operation per line.
All file names must be enclosed in double quotes.
Constraints
File names have length from 1 to 16 characters.
Operations in the log do not cause errors.
0 ≤ N, M ≤ 104
Sample tests
No.
Input file (input.txt)
Output file (output.txt)
1
5
"BaNaNa-145"
"Example-01"
"MyMusic-03"
"MyGame.exe"
"UNIT.1.pas"
10
mov "MyMusic-03" "BestMusic.mp3"
mov "MyGame.exe" "F0"
mov "BaNaNa-145" "MyMusic-03"
del "Example-01"
cpy "UNIT.1.pas" "UNIT.2.pas"
del "UNIT.1.pas"
mov "F0" "BaNaNa-145"
new "x2"
mov "BestMusic.mp3" "MyGame.exe"
new "UNIT.1.pas"
8
mov "BaNaNa-145" "~"
mov "MyGame.exe" "BaNaNa-145"
mov "MyMusic-03" "MyGame.exe"
mov "~" "MyMusic-03"
del "Example-01"
mov "UNIT.1.pas" "UNIT.2.pas"
new "x2"
new "UNIT.1.pas"
2
5
"BaNaNa-145"
"Example-01"
"MyMusic-03"
"MyGame.exe"
"UNIT.1.pas"
10
mov "BaNaNa-145" "BaNaNa-360"
cpy "MyMusic-03" "M0"
cpy "BaNaNa-360" "NaN.InF"
mov "NaN.InF" "BaNaNa-145"
new "x2"
del "BaNaNa-360"
mov "M0" "Music.mp3"
del "MyMusic-03"
mov "Music.mp3" "MyMusic-03"
del "x2"
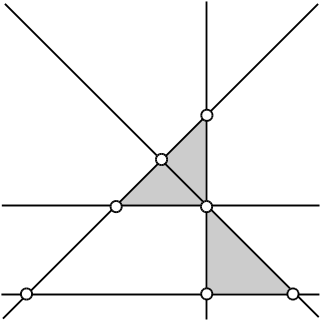
Рассмотрим конфигурацию из n прямых на плоскости.
Требуется определить число всех треугольных ячеек, образованных в результате разбиения плоскости указанным набором прямых.
Формат входного файла
Во входном файле "input.txt" записано натуральное число n, за которым следует ровно n прямых.
Каждая прямая задается парой несовпадающих точек: (Axi, Ayi), (Bxi, Byi).
Формат выходного файла
Выходной файл "output.txt" должен содержать число полученных треугольников.
Ограничения
Гарантируется, что никакие две прямые не совпадают между собой.
Все входные значения являются целыми десятичными числами.
Карта лабиринта, выступающего в качестве игрового поля, представлена в виде матрицы n × m клеток.
Каждая клетка маркируется одним из двух значений: свободное пространство либо непроходимый участок.
Полагается, что в процессе игры персонаж может передвигаться в одном из четырех направлений: вверх, вниз, вправо и влево, всегда при этом оставаясь в свободных клетках.
В лабиринте также могут встречаться закрытые комнаты, переходы между которыми остаются для персонажа недоступными.
Иначе говоря, находясь в одной из таких комнат, персонаж не сможет переместиться в любую другую стандартным для него способом.
Для некоторого заданного лабиринта требуется определить общее число закрытых комнат.
Формат входного файла
Во входном файле "input.txt" построчно хранится двумерный массив символов, представляющий собой карту лабиринта.
Свободные клетки в нем обозначаются пробелами (ASCII 32), в то время как все остальные выступают в качестве непроходимых участков.
Формат выходного файла
Выходной файл "output.txt" должен содержать полученное число комнат.
Одна курьерская компания, занимающаяся междугородными перевозками крупногабаритных грузов, решила упростить жизнь своим сотрудникам.
Для этого перед программистами поставили задачу, определить наиболее короткие маршруты, по которым можно было бы доставлять грузы между различными населенными пунктами.
В качестве входных данных им выдали дорожную карту, представленную в виде взвешенного графа, вершины которого отвечают за населенные пункты, а ребра обозначают соединяющие их двусторонние магистрали.
Каждое ребро имеет вес, указывающий длину соответствующей магистрали.
На выходе требуется получить список кратчайших маршрутов между всеми возможными парами вершин в таком графе.
При этом среди них приоритетными считаются маршруты с максимально возможным числом остановок в промежуточных пунктах, т.е. проходящие через как можно большее число вершин.
Формат входного файла
В начале входного файла "input.txt" записаны два натуральных числа: n — число вершин и m — число соединяющих их ребер.
Далее следует набор из m таких ребер, каждое из которых представлено тройкой целых чисел: (ai, bi) — номера вершин, wi — вес ребра.
При этом полагается, что нумерация вершин начинается с нуля.
Формат выходного файла
В выходной файл "output.txt" следует построчно вывести маршруты, удовлетворяющие условию задачи и представленные в виде последовательностей из номеров вершин.
Если для какой-либо пары вершин существует более одного такого маршрута, достаточно будет вывести любой из них.
Ограничения
Гарантируется, что исходный граф является связным, т.е. между любой парой его вершин можно проложить маршрут.
У одной инженерной компании, занимающейся прокладкой труб холодного водоснабжения, возникла необходимость в оптимизации потенциальных затрат на постройку очередного водопровода.
Решение указанной задачи, естественно, возложили на программистов.
В качестве входных данных им выдали карту, представленную в виде взвешенного графа, вершины которого отвечают за населенные пункты (с расположенными в них распределительными станциями), а ребра обозначают соединяющие их магистрали.
Каждое ребро имеет вес, указывающий длину соответствующей магистрали.
Для того, чтобы обеспечить водой даже самые труднодоступные районы, требуется построить распределенную сеть из водонапорных труб, проходящую через все указанные пункты.
При этом сами трубы должны пролегать строго вдоль выделенных магистралей.
В целях экономии ресурсов также необходимо чтобы такая сеть имела минимально возможную длину.
При решении задачи следует полагать, что в полученной сети существует всего лишь один источник воды, от которого будут запитываться все остальные узлы.
Формат входного файла
В начале входного файла "input.txt" записаны два натуральных числа: n — число вершин и m — число соединяющих их ребер.
Далее следует набор из m таких ребер, каждое из которых представлено тройкой целых чисел: (ai, bi) — номера вершин, wi — вес ребра.
При этом полагается, что нумерация вершин начинается с нуля.
Формат выходного файла
В выходной файл "output.txt" следует вывести номера тех ребер, через которые должен пройти водопровод.
При этом полагается, что нумерация ребер начинается с нуля.
Ограничения
Гарантируется, что исходный граф является связным, т.е. между любой парой его вершин можно проложить маршрут.
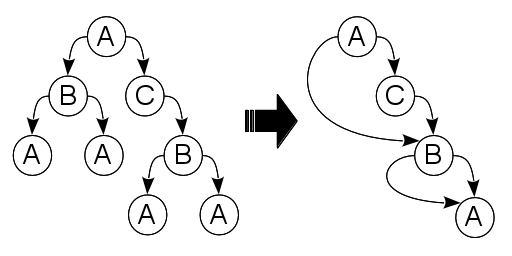
Пусть имеется корневое дерево, узлам которого ранее был приписан определенный набор цветов.
Каждый нелистовой узел такого дерева содержит произвольное число ссылок на своих потомков.
При этом полагается, что порядок их следования имеет значение.
В исходном дереве могут встречаться поддеревья, обладающие одинаковой структурой.
Здесь используется тот факт, что с точки зрения стороннего наблюдателя, два дерева считаются тождественными, если их корни окрашены в одинаковые цвета и все соответствующие потомки тождественны между собой.
Как следствие, ссылки на указанные поддеревья также являются взаимозаменяемыми.
Для экономии памяти, исходное дерево следует представить в сжатом виде.
С этой целью требуется расставить ссылки на потомков таким образом, чтобы минимизировать число узлов в полученном графе, сохранив при этом структуру исходного дерева.
Формат входного файла
Во входном файле "input.txt" хранится дерево, представленное в следующем виде.
Вначале идет цвет корневого узла, после которого (через пробел) указывается число его прямых потомков.
Затем следует упорядоченный набор таких потомков, записанных аналогичным образом.
Для обозначения цветов здесь используются цифры и строчные буквы латинского алфавита.
Каждому узлу также ставится в соответствие его порядковый номер (начиная с нуля).
Формат выходного файла
Выходной файл "output.txt" должен содержать пары значений: номер старого узла и номер узла, на который его следует заменить.
При этом корень дерева (узел с нулевым индексом) является не перемещаемым.
В случае если сжатие не может быть выполнено, выходной файл следует оставить пустым.
Ограничения
Полагается, что каждый узел имеет не более 10 потомков.
При этом общее число узлов не превосходит 2 ⋅ 105.
Жители одного крупного города озаботились сложившейся в его окрестностях экологической обстановкой.
Дело в том, что в прилегающих к нему районах имеется достаточно большое число промышленных предприятий, вредные выбросы которых неблагоприятным образом влияют на окружающую среду.
Ситуация усугубляется еще и тем, что расположены они в основном по берегам рек, воды которых также идут на хозяйственные нужды горожан.
Для того, чтобы оценить величину наносимого ущерба, понадобилось провести ряд исследований, направленных на выявление наиболее вредных объектов промышленности.
Однако представители крупных коммерческих предприятий отказались предоставлять точную информацию об объемах сбрасываемых в реку загрязнений.
В связи с этим, члены экологического общества поставили перед собой задачу — попытаться восстановить их значения, руководствуясь только лишь данными, полученными из открытых источников.
Карта речной системы представляет собой ориентированный бесконтурный граф (сеть), в узлах которого располагаются очистные сооружения и разнообразные источники загрязнений.
На входе указанной сети располагаются узлы, связанные с крупнейшими заводами.
Каждый i-й завод непрерывно за одну единицу времени сбрасывает в реку ровно Xi тонн химических отходов.
Известно, что при прохождении через k-й промежуточный узел концентрация примеси изменяется на аддитивную константу Fk.
Процент примеси, пропускаемый через ребро, направленное из узла с номером k в узел с номером l, определяется коэффициентом Wkl.
На выходе располагаются системы сбора воды с установленными на них датчиками, которые регистрируют количество примеси Yj, проходящее через них за одну единицу времени.
По имеющимся данным требуется определить концентрацию примеси, выбрасываемую каждым отдельным заводом.
Формат входного файла
Во входном файле "input.txt" хранится карта речной сети, записанная в следующем виде.
Вначале идет пара натуральных значений n и m — число вершин и ребер в таком графе.
За ними следует набор из m ребер, каждое из которых задается тремя значениями:
k и l — номера вершин, которые оно соединяет;
Wkl — весовой коэффициент.
При этом полагается, что нумерация вершин начинается с нуля.
На входе такой сети располагаются вершины, связанные с основными заводами.
В отличие от остальных вершин, они не имеют входящих ребер.
Вершины, имеющие как входные так и выходные ребра, связаны с промежуточными узлами, а вершины, не имеющие выходных ребер — с конечными.
Далее следует список, в котором каждому промежуточному узлу с номером k ставится в соответствие вещественная константа Fk,
а каждому конечному узлу с номером j — значение Yj.
Порядок следования узлов в таком списке не гарантирован!
Формат выходного файла
Если задача имеет единственное решение, в выходной файл "output.txt" выводится строка 'SOLUTION:',
за которой следует список из номеров входных узлов i и соответствующих им значений Xi,
указанных с точностью до 5-го знака после запятой.
В противном случае, выходной файл должен содержать строку 'INFINITY!'.
Ограничения
Гарантируется, что точное решение всегда существует
и удовлетворяет следующим соотношениям: 0 ≤ Xi ≤ 10.
Все тесты подобраны таким образом, чтобы снизить влияние погрешности
машинного округления на результат решения.
Гарантируется отсутствие висячих вершин
(не связанных ни с одним из ребер).
Число ребер, исходящих из одной вершины, не превосходит 10,
а их суммарный вес равен 1.
Матрица фотоаппарата представляет собой прямоугольную таблицу размерности [n × m], состоящую из светочувствительных элементов (ячеек).
В момент съемки каждой ячейке такой таблицы ставится в соответствие вещественное значение Xij, указывающее ее состояние (интенсивность).
Известно, что при считывании состояния отдельно взятой ячейки к нему добавляется взвешенная сумма состояний окружающих ее ячеек, которые формируют упорядоченный набор слоев (см. рисунок).
При этом каждый последующий слой имеет в два раза меньшее влияние, чем предыдущий.
Коэффициент влияния каждой такой ячейки на полученное значение равен 1 / (2l ⋅ Nl), где l — номер содержащего ее слоя, Nl — число ячеек в l-м слое.
Также для отдельно взятой модели фотоаппарата известно максимальное число слоев k, оказывающих влияние на результат измерения.
Для заданной матрицы Y, полученной в результате измерений, и радиуса воздействия k требуется восстановить исходные значения Xij.
Значения фиктивных ячеек (лежащих за пределами матрицы) полагаются равными нулю.
Формат входного файла
В начале входного файла хранятся три натуральных числа: n, m и k.
Далее следует матрица результатов измерений Y, записанная в строчном формате.
Формат выходного файла
Выходной файл должен содержать восстановленную матрицу X.
Все значения должны быть указаны с точностью до 5-го знака после запятой.

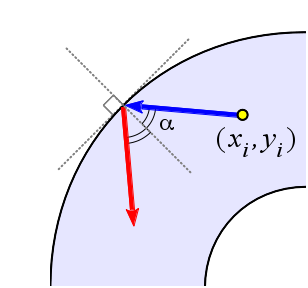 Определим кольцо, как область, заключенную между двумя окружностями с общим центром (x0, y0) и разными радиусами: r2 > r1 > 0.
В этом случае исходное множество частиц можно условно разбить на три группы:
Определим кольцо, как область, заключенную между двумя окружностями с общим центром (x0, y0) и разными радиусами: r2 > r1 > 0.
В этом случае исходное множество частиц можно условно разбить на три группы: