Данная задача является интерактивной и предполагает взаимодействие с сервером путем отправки и приема сообщений определенного вида.
Пусть имеется функция F(x1, x2, …, xn), которая в некоторой заданной области D = [a1, b1] × [a2, b2] × … × [an, bn] обладает монотонным профилем по каждой из осей координат.
Иначе говоря, если зафиксировать любые n − 1 из ее аргументов, то мы получим монотонную функцию одной переменной.
Примером такой функции (в случае трех переменных) является: F(x1, x2, x3) = (x1 + x2) ⋅ x3.
Требуется найти любую такую точку x = (x1, x2, …, xn) из D, в которой исходная функция принимает заданное значение f0.
При этом погрешность решения должна составлять не более, чем 10 − 9.
В качестве погрешности решения здесь будем рассматривать величину следующего вида:
Er = miny ∈ S(maxi|xi − yi|), где S = {y ∈ D: F(y) = f0} — область точных решений.
Протокол взаимодействия
Взаимодействие с сервером происходит посредством следующих команд, которые выводятся в выходной поток (stdout).
При первом запросе в выходной поток необходимо вывести команду:
run
В качестве ответа через входной поток (stdin) будет получено натуральное n — число аргументов целевой функции,
за которым следуют n пар вещественных чисел [ai, bi], определяющих диапазон изменений i-го аргумента, и значение f0.
Для вычисления функции в заданной точке, используется команда:
get, за которой следует набор из n вещественных аргументов (отделенных друг от друга пробелами).
В качестве ответа будет отправлено полученное значение.
Данная команда приводит к возникновению ошибки, если заданная точка лежит за пределами допустимой области.
Если решение было найдено, сеанс завершается командой:
ans, за которой следует набор из n вещественных значений, определяющих искомую точку.
В противном случае, сеанс завершается командой:
not
Ограничения
Для корректной работы программы, после каждой команды, отправленной в выходной поток,
следует осуществлять вывод перевода строки и выполнять сброс буфера (flush).
Общее число запросов к серверу не должно превышать 1100.
Все вещественные значения указываются с точностью
до 10-го знака после запятой.
На завод, занимающийся производством игрушек, привезли исходные материалы в виде набора наклеек с разного рода цветными изображениями.
Указанные наклейки было решено задействовать при заготовке детских кубиков (по одной на каждую грань).
При этом, по задумке дизайнеров, каждый такой кубик не должен содержать наклеек с одинаковыми изображениями.
Кубики, состоящие из одного и того же набора наклеек, объединяются в отдельные группы.
В свою очередь, наклейки одного вида не могут встречаться на кубиках, принадлежащих к разным группам.
Требуется определить максимально возможное число таких кубиков, которые можно покрыть имеющимся набором наклеек.
Формат входного файла
В заголовке входного файла "input.txt" хранится число доступных разновидностей наклеек n.
Далее следует набор из n значений Ai, указывающих число наклеек каждого вида.
Формат выходного файла
Выходной файл "output.txt" должен содержать максимально возможное число кубиков.
Для заданных натуральных чисел k и q определим последовательность следующего вида: A1 = k, Ai + 1 = Ai + Bi − Ci, где Bi — сумма цифр числа Ai (в системе счисления по основанию q), расположенных на нечетных позициях, а Ci — сумма цифр, расположенных на четных позициях.
При этом полагается, что позиции цифр в числе нумеруются слева направо (начиная от старшего ненулевого разряда, которому присваивается 1-й номер).
Обозначим за L(k) наиболее раннюю позицию с которой указанная последовательность начинает повторяться.
Иначе говоря, имеет место следующее утверждение: L(k) = min{l: ∀ (i > l) ∃ (j < i): (Aj = Ai)}.
Требуется вычислить последовательность значений L(k) для всех натуральных k ≤ m при некотором фиксированном q.
Формат входного файла
Входной файл "input.txt" содержит пару натуральных чисел: q и m.
Формат выходного файла
Выходной файл "output.txt" должен содержать последовательность значений L(k), расположенных в порядке возрастания величины k = 1, 2, …, m.
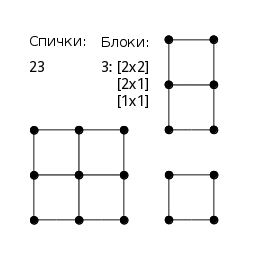
Пусть имеется n спичек равной длины.
Из указанных спичек необходимо собрать набор прямоугольных блоков, каждый из которых представляет собой двумерную матрицу квадратных ячеек (см. рисунок).
При этом каждое ребро в таком блоке соответствует ровно одной спичке.
Таким образом, полученный блок однозначно определяется своей конфигурацией [A × B], где A и B — размеры его сторон.
Блоки, совпадающие с точностью до поворота, считаются одинаковыми, т.е. [A × B] = [B × A].
Требуется вывести все уникальные комбинации прямоугольных блоков, которые можно составить из заданного числа спичек.
При этом каждая такая комбинация должна включать в себя все имеющиеся спички.
Комбинации, различающиеся только лишь порядком следования составляющих их блоков, полагаются тождественными и не должны встречаться более одного раза.
Формат входного файла
Входной файл "input.txt" содержит исходное число спичек n.
Формат выходного файла
Выходной файл "output.txt" должен содержать все найденные комбинации, представленные в следующем формате:
вначале указывается число блоков в текущей комбинации k;
далее следует ровно k пар натуральных чисел, определяющих конфигурации имеющихся блоков.
В случае, если подходящие комбинации не были найдены,
выходной файл следует оставить пустым.
В рамках одного научно-исследовательского проекта возникла необходимость в эффективной передаче экспериментальных данных, имеющих специальный вид, между различными узлами вычислительной сети.
В связи с этим была сформулирована следующая задача.
Пусть имеется некоторая бинарная последовательность (состоящая из нулей и единиц), разбитая на блоки фиксированной длины.
При этом заранее известно, что каждый такой блок содержит в себе ровно n нулей и m единиц.
При передаче указанной последовательности по внешнему каналу связи требуется представить ее в сжатом виде.
Для этого рассмотрим множество всех различных значений, которые могут принимать составляющие ее блоки.
Отсортировав их в лексикографическом порядке, получим некоторый упорядоченный алфавит.
Далее заменим каждый отдельный блок входной последовательности числовым кодом, указывающим его позицию в таком алфавите (будем полагать, что нумерация символов алфавита начинается с нуля).
Несложно показать, что размер полученного алфавита обратно пропорционален значению |n − m|.
Так, в предельном случае, когда n (или m) равно нулю, алфавит будет состоять всего-лишь из одного символа.
В свою очередь, чем меньше размер алфавита, тем меньшее число бит будет требоваться для представления номеров содержащихся в нем символов.
Если предположить, что во входной последовательности преобладают нулевые (либо единичные) биты, тогда от предложенного подхода можно будет ожидать достаточно высокой степени сжатия.
Формат входного файла
В первой строке входного файла "input.txt" записаны два целых неотрицательных числа n и m.
Далее следует текстовая строка, состоящая из n нулей и m единиц.
Формат выходного файла
Выходной файл "output.txt" должен содержать результирующий код указанной строки, представленный в двоичной системе счисления (ведущие нули при этом можно опустить).
Пусть имеются две строки, содержащие набор слов, состоящих из цифр и символов латинского алфавита, и отделенных друг от друга пробелами либо знаками препинания ('-', '.', ',', ':', ';', '!', '?').
Регистр символов, а также количество подряд идущих пробелов роли не играет (любое число пробелов воспринимается как один символ).
Пробелы, расположенные по краям строки либо отделяющие знаки препинания, игнорируются.
Для определения формата текста в пределах каждой такой строки используются теги следующих видов:
<b>текст</b> — жирный шрифт;
<i>текст</i> — курсив.
Также допускается использование нескольких вложенных друг в друга тегов.
При этом внутренний тег сохраняет форматирование внешнего фрагмента.
Теги могут разбивать слово на части: <i><b>тек</b>ст</i>.
В этом случае, отдельные части слова будут иметь различное форматирование.
В свою очередь, на пробельные символы форматирование не распространяется.
Требуется сравнить две такие строки.
Формат входного файла
Во входном файле "input.txt" содержатся две строки, между которыми необходимо выполнить сравнение.
Формат выходного файла
Выходной файл "output.txt" должен содержать одно из следующих значений:
2 — текст в обеих строках совпадает и имеет одинаковый формат;
1 — текст в обеих строках совпадает, но имеет разный формат;
0 — обе строки содержат разный текст.
Ограничения
Полагается, что в исходных строках отсутствуют синтаксические ошибки,
связанные с порядком расстановки тегов.
Длина каждой строки не превосходит 3 ⋅ 106.
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
<i>THIS </i><i>IS <b>SPARTA!!!</b></i>
<i>this is <b>Sparta ! !!</b></i>
2
2
<i>THIS IS <b>SPARTA!!!</b></i>
<i>this is</i> <b>Sparta!!!</b>
1
3
<i>THIS IS <b>SPARTA!!!</b></i>
<i>This Is <b>Sparta!</b></i>
Пусть имеется программа, записанная на императивном языке программирования, поддерживающем команды следующего вида:
<переменная> = <выражение> — присвоить переменной результат заданного выражения.
Выражение может состоять из арифметических операций ('+', '-', '*', '/'), круглых скобок, переменных и целочисленных констант.
Между ними также допускается произвольное число пробелов.
При этом знак минуса используется здесь для обозначения как бинарной, так и унарной операции.
Операции ('+', '-') имеют меньший приоритет, чем ('*', '/').
Операции, обладающие одинаковым приоритетом, выполняются слева направо.
В качестве имен переменных выступают символы латинского алфавита (регистр их написания неважен).
Полагается, что все они принадлежат к знаковому 32-разрядному целому типу и могут принимать значения из диапазона от − 231 до 231 − 1.
Константы представляют собой числа, записанные в десятичной системе счисления и лежащие в диапазоне от 0 до 231 − 1.
Изначально всем переменным присваиваются нулевые значения.
Арифметическое переполнение и деление на ноль приводят к неопределенному результату, для обозначения которого используется символ '#' (ASCII 35).
Все операции с неопределенным значением (кроме умножения на ноль) также возвращают '#'.
В рамках текущей задачи для каждой переменной требуется определить ее значение, полученное по окончанию программы.
Формат входного файла
Во входном файле "input.txt" построчно содержатся команды указанного языка.
Формат выходного файла
В выходной файл "output.txt" следует вывести пары: <переменная> <значение>.
При этом переменные, которые отсутствуют в левых частях выражений, могут быть проигнорированы.
Ограничения
Полагается, что все представленные команды включают в себя не более 50 арифметических операций и не содержат синтаксических ошибок.
Число открывающихся скобок также ограничено и не превосходит 30.
Входная программа состоит как минимум из одной команды.
Общее число команд не превосходит 1000.
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
i = 1045
B = (a + i) * 23 - 190
c = B
i = - 4 + i / 10
c = i - 138
b 23845
c -38
i 100
2
i = B + 14903 * A
B = 100 / (i * 2)
C = b /(c +a * E)
i = i - u * C
B = i + 350
Исходная строка, содержащая некоторое арифметическое выражение, состоит из набора символьных идентификаторов (выступающих в роли операндов), знаков операций ('+', '-', '*') и круглых скобок.
Между ними также допускается наличие разделителей из произвольного числа пробелов.
При этом знак минуса может обозначать как бинарную, так и унарную операцию.
Между любыми двумя знаками операций всегда присутствуют либо скобки, либо операнды.
Для записи операндов здесь используются строчные буквы латинского алфавита.
В указанном выражении требуется раскрыть скобки и выполнить приведение подобных слагаемых.
На выходе каждое такое слагаемое должно быть записано в следующем формате.
Вначале указывается целочисленный коэффициент (может быть опущен, если он равен единице),
за которым идет набор множителей. В качестве разделителя используется знак умножения '*'.
Каждому символу алфавита здесь должен соответствовать ровно один множитель.
Для обозначения кратных множителей используется знак возведения в степень '^',
за которым следует целое число, обозначающее его кратность.
При этом слагаемые, различающиеся только лишь порядком следования составляющих их множителей, полагаются тождественными и не должны встречаться более одного раза.
В свою очередь, слагаемые, перед которыми стоит нулевой коэффициент, а также множители, возведенные в нулевую степень, должны быть проигнорированы.
Формат входного файла
Входной файл "input.txt" содержит единственную строку с арифметическим выражением.
Формат выходного файла
Выходной файл "output.txt" должен содержать все полученные слагаемые, приведенные к требуемому виду и разделенные символами '+' либо '-'
(в зависимости от знаков стоящих перед ними коэффициентов).
Если полученное выражение тождественно равно нулю, в выходной файл выводится 0.
Ограничения
Полагается, что исходное выражение состоит не более чем из 25 арифметических операций и не содержит синтаксических ошибок.
Число открывающихся скобок ограничено и не превосходит 20.
Пусть имеется формальный язык, слова которого представляют собой цепочки символов, составленные из отдельных неперекрывающихся подцепочек (морфов).
Значения, которые способны принимать указанные морфы, образуют словарь базовых единиц (основ) исходного языка.
При этом полагается, что никакие две основы не могут иметь общих префиксов.
Для заданного набора слов требуется определить список основ, разбивающих их на минимально возможное число морфов.
Для каждой такой основы необходимо также посчитать, сколько раз она встречается в исходном тексте (в качестве значения какого-либо морфа).
Формат входного файла
В начале входного файла "input.txt" хранится натуральное число n.
Далее следует набор из n слов, состоящих из цифр и букв латинского алфавита (регистр их написания неважен).
При этом каждое слово располагается в отдельной строке.
Формат выходного файла
Выходной файл "output.txt" должен содержать все найденные основы (без повторений), приведенные к одному регистру и расположенные в лексикографическом порядке.
Напротив каждой такой основы (через пробел) указывается число совпадающих с ней морфов.
Ограничения
Полагается, что длина отдельно взятого слова лежит в диапазоне от 1 до 5000.
Карта лабиринта, выступающего в качестве игрового поля, представлена в виде матрицы n × m клеток.
Каждая клетка маркируется одним из двух значений: свободное пространство либо непроходимый участок.
Полагается, что в процессе игры персонаж может передвигаться в одном из четырех направлений: вверх, вниз, вправо и влево, всегда при этом оставаясь в свободных клетках.
В лабиринте также могут встречаться закрытые комнаты, переходы между которыми остаются для персонажа недоступными.
Иначе говоря, находясь в одной из таких комнат, персонаж не сможет переместиться в любую другую стандартным для него способом.
Для некоторого заданного лабиринта требуется определить общее число закрытых комнат.
Формат входного файла
Во входном файле "input.txt" построчно хранится двумерный массив символов, представляющий собой карту лабиринта.
Свободные клетки в нем обозначаются пробелами (ASCII 32), в то время как все остальные выступают в качестве непроходимых участков.
Формат выходного файла
Выходной файл "output.txt" должен содержать полученное число комнат.
Частотный словарь представляет собой список слов некоторого выбранного языка, каждому из которых ставится в соответствие частота его встречаемости в исходном наборе текстов.
Пусть имеется последовательность слов, состоящих из цифр и букв латинского алфавита.
При этом полагается, что регистр их написания неважен (заглавные и строчные символы эквивалентны между собой).
Все прочие символы, включая пробелы и знаки препинания, играют роль разделителей.
Требуется составить частотный словарь на основе имеющегося текста, определив число вхождений каждого встречаемого в нем слова.
При решении задачи рекомендуется использовать двоичные деревья поиска, списки с пропусками либо хеш-таблицы.
Формат входного файла
Во входном файле "input.txt" содержится исходная последовательность из слов и разделительных символов.
Формат выходного файла
Выходной файл "output.txt" должен содержать все найденные слова (без повторений), приведенные к одному регистру и расположенные в лексикографическом порядке.
Напротив каждого такого слова (через пробел) указывается число его вхождений во входной файл.
Если результирующий словарь оказался пустым, в выходной файл выводится единственный символ пробела.
Ограничения
Полагается, что длина отдельно взятого слова составляет не более 10 символов.
Число уникальных слов, формирующих словарь, не превосходит 5 ⋅ 104.
Размер входного файла не превосходит 10 МБ.
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
This is the house that Jack built.
This is the cheese that lay in the house that Jack built.
This is the rat that ate the cheese
That lay in the house that Jack built.
This is the cat that chased the rat
That ate the cheese that lay in the house that Jack built.
This is the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the rooster that crowed in the morn
That woke the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the farmer sowing his corn
That kept the rooster that crowed in the morn
That woke the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
This is the horse and the hound and the horn
That belonged to the farmer sowing his corn
That kept the rooster that crowed in the morn
That woke the judge all shaven and shorn
That married the man all tattered and torn
That kissed the maiden all forlorn
That milked the cow with the crumpled horn
That tossed the dog that worried the cat
That chased the rat that ate the cheese
That lay in the house that Jack built.
all 15
and 11
ate 10
belonged 1
built 12
cat 9
chased 9
cheese 11
corn 2
cow 7
crowed 3
crumpled 7
dog 8
farmer 2
forlorn 6
his 2
horn 8
horse 1
hound 1
house 12
in 14
is 12
jack 12
judge 4
kept 2
kissed 5
lay 11
maiden 6
man 5
married 4
milked 6
morn 3
rat 10
rooster 3
shaven 4
shorn 4
sowing 2
tattered 5
that 81
the 90
this 12
to 1
torn 5
tossed 7
with 7
woke 3
worried 8
Пусть имеется текстовая строка S, состоящая из цифр и букв латинского алфавита. При этом полагается, что регистр их написания неважен, т.е. заглавные и строчные символы эквивалентны между собой.
На основе указанной строки требуется сформировать словарь T, в котором отдельным ее подстрокам ставятся в соответствие некоторые числовые коды.
Описание вычислительной процедуры для получения таких кодов приводится ниже:
на начальном этапе алгоритма создадим пустой словарь T и заведем счетчик k = 0;
будем двигаться по заданной строке, читая ее символы слева направо;
находясь в начале очередного суффикса строки S, выберем наименьший непустой его префикс, который отсутствует в словаре T;
выбранный на предыдущем этапе префикс добавим в словарь, указав в качестве числового кода его порядковый номер k;
увеличим счетчик k на единицу;
дальнейший поиск продолжается с позиции, следующей после указанного префикса.
Если при попытке добавления очередной подстроки число записей в словаре превысит некоторое заданное n, словарь должен быть очищен.
Счетчик k при этом обнуляется.
Последний считанный символ (в окончании текущего префикса) возвращается в поток, и процедура возобновляется с той же позиции, в которой она остановилась.
В качестве ответа требуется вывести содержимое такого словаря на момент окончания входной строки.
Формат входного файла
В первой строке входного файла "input.txt" записано натуральное число n.
Далее следует строка S, для которой необходимо построить словарь.
Формат выходного файла
В выходной файл "output.txt" нужно вывести все содержащиеся в словаре подстроки, приведенные к одному регистру и расположенные в лексикографическом порядке.
Напротив каждой такой строки (через пробел) следует указать ее порядковый номер.
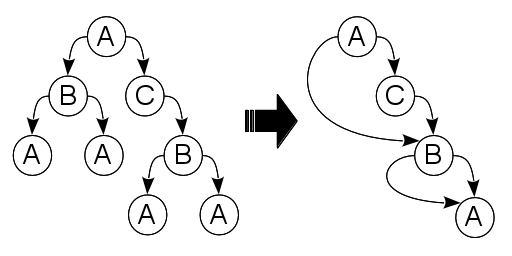
Пусть имеется корневое дерево, узлам которого ранее был приписан определенный набор цветов.
Каждый нелистовой узел такого дерева содержит произвольное число ссылок на своих потомков.
При этом полагается, что порядок их следования имеет значение.
В исходном дереве могут встречаться поддеревья, обладающие одинаковой структурой.
Здесь используется тот факт, что с точки зрения стороннего наблюдателя, два дерева считаются тождественными, если их корни окрашены в одинаковые цвета и все соответствующие потомки тождественны между собой.
Как следствие, ссылки на указанные поддеревья также являются взаимозаменяемыми.
Для экономии памяти, исходное дерево следует представить в сжатом виде.
С этой целью требуется расставить ссылки на потомков таким образом, чтобы минимизировать число узлов в полученном графе, сохранив при этом структуру исходного дерева.
Формат входного файла
Во входном файле "input.txt" хранится дерево, представленное в следующем виде.
Вначале идет цвет корневого узла, после которого (через пробел) указывается число его прямых потомков.
Затем следует упорядоченный набор таких потомков, записанных аналогичным образом.
Для обозначения цветов здесь используются цифры и строчные буквы латинского алфавита.
Каждому узлу также ставится в соответствие его порядковый номер (начиная с нуля).
Формат выходного файла
Выходной файл "output.txt" должен содержать пары значений: номер старого узла и номер узла, на который его следует заменить.
При этом корень дерева (узел с нулевым индексом) является не перемещаемым.
В случае если сжатие не может быть выполнено, выходной файл следует оставить пустым.
Ограничения
Полагается, что каждый узел имеет не более 10 потомков.
При этом общее число узлов не превосходит 2 ⋅ 105.
Рассмотрим все различные строки, которые могут быть получены путем циклического сдвига некоторой заданной строки S.
Отсортировав их в лексикографическом порядке, сформируем из них упорядоченную последовательность.
Требуется определить номер строки S в полученной последовательности.
При этом полагается, что элементы такой последовательности нумеруются с нуля.
Формат входного файла
В заголовке входного файла "input.txt" содержится единственная строка S, состоящая из цифр и строчных букв латинского алфавита.
Формат выходного файла
Выходной файл "output.txt" должен содержать порядковый номер исходной строки.
Пусть имеется текстовая строка S, состоящая из произвольных печатных символов (ASCII 32-126).
Требуется определить общее число ее подстрок, совпадающих с некоторым заданным образцом T.
Для решения задачи следует воспользоваться алгоритмом Кнута-Морриса-Пратта.
Формат входного файла
В заголовке входного файла "input.txt" содержится строка T, выступающая в роли образца.
Далее следует строка S, в которой необходимо выполнить поиск.
Формат выходного файла
Выходной файл "output.txt" должен содержать число найденных подстрок.
Владелец одного особняка, на территории которого произрастает большое число редких видов деревьев, захотел отгородить свой сад от вандалов, затратив на это как можно меньшее количество ресурсов.
Для этих целей он составил карту земельного участка, отметив на ней точки расположения каждого отдельного дерева.
От Вас требуется определить минимально возможную длину забора, которым можно ограничить заданное множество точек.
Формат входного файла
Во входном файле "input.txt" записано натуральное число n, за которым следует ровно n пар вещественных чисел (xi, yi), отвечающих за координаты исходных точек.
Формат выходного файла
Выходной файл "output.txt" должен содержать ответ, записанный с точностью до 5-го знака после запятой.
Ограничения
Гарантируется, что в исходном множестве присутствует набор точек, не лежащих на одной прямой.
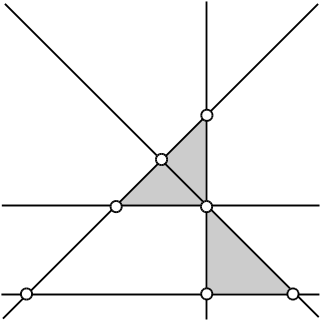
Рассмотрим конфигурацию из n прямых на плоскости.
Требуется определить число всех треугольных ячеек, образованных в результате разбиения плоскости указанным набором прямых.
Формат входного файла
Во входном файле "input.txt" записано натуральное число n, за которым следует ровно n прямых.
Каждая прямая задается парой несовпадающих точек: (Axi, Ayi), (Bxi, Byi).
Формат выходного файла
Выходной файл "output.txt" должен содержать число полученных треугольников.
Ограничения
Гарантируется, что никакие две прямые не совпадают между собой.
Все входные значения являются целыми десятичными числами.
У одной инженерной компании, занимающейся прокладкой труб холодного водоснабжения, возникла необходимость в оптимизации потенциальных затрат на постройку очередного водопровода.
Решение указанной задачи, естественно, возложили на программистов.
В качестве входных данных им выдали карту, представленную в виде взвешенного графа, вершины которого отвечают за населенные пункты (с расположенными в них распределительными станциями), а ребра обозначают соединяющие их магистрали.
Каждое ребро имеет вес, указывающий длину соответствующей магистрали.
Для того, чтобы обеспечить водой даже самые труднодоступные районы, требуется построить распределенную сеть из водонапорных труб, проходящую через все указанные пункты.
При этом сами трубы должны пролегать строго вдоль выделенных магистралей.
В целях экономии ресурсов также необходимо чтобы такая сеть имела минимально возможную длину.
При решении задачи следует полагать, что в полученной сети существует всего лишь один источник воды, от которого будут запитываться все остальные узлы.
Формат входного файла
В начале входного файла "input.txt" записаны два натуральных числа: n — число вершин и m — число соединяющих их ребер.
Далее следует набор из m таких ребер, каждое из которых представлено тройкой целых чисел: (ai, bi) — номера вершин, wi — вес ребра.
При этом полагается, что нумерация вершин начинается с нуля.
Формат выходного файла
В выходной файл "output.txt" следует вывести номера тех ребер, через которые должен пройти водопровод.
При этом полагается, что нумерация ребер начинается с нуля.
Ограничения
Гарантируется, что исходный граф является связным, т.е. между любой парой его вершин можно проложить маршрут.
Одна курьерская компания, занимающаяся междугородными перевозками крупногабаритных грузов, решила упростить жизнь своим сотрудникам.
Для этого перед программистами поставили задачу, определить наиболее короткие маршруты, по которым можно было бы доставлять грузы между различными населенными пунктами.
В качестве входных данных им выдали дорожную карту, представленную в виде взвешенного графа, вершины которого отвечают за населенные пункты, а ребра обозначают соединяющие их двусторонние магистрали.
Каждое ребро имеет вес, указывающий длину соответствующей магистрали.
На выходе требуется получить список кратчайших маршрутов между всеми возможными парами вершин в таком графе.
При этом среди них приоритетными считаются маршруты с максимально возможным числом остановок в промежуточных пунктах, т.е. проходящие через как можно большее число вершин.
Формат входного файла
В начале входного файла "input.txt" записаны два натуральных числа: n — число вершин и m — число соединяющих их ребер.
Далее следует набор из m таких ребер, каждое из которых представлено тройкой целых чисел: (ai, bi) — номера вершин, wi — вес ребра.
При этом полагается, что нумерация вершин начинается с нуля.
Формат выходного файла
В выходной файл "output.txt" следует построчно вывести маршруты, удовлетворяющие условию задачи и представленные в виде последовательностей из номеров вершин.
Если для какой-либо пары вершин существует более одного такого маршрута, достаточно будет вывести любой из них.
Ограничения
Гарантируется, что исходный граф является связным, т.е. между любой парой его вершин можно проложить маршрут.