Пусть имеется множество всех возможных цепочек, состоящих из конечного числа звеньев.
Из указанных цепочек необходимо построить последовательность такую, чтобы каждая следующая цепочка в ней была ровно на d звеньев больше предыдущей, а суммарная длина всех входящих в нее цепочек равнялась n.
Максимально возможное количество цепочек, из которых может состоять такая последовательность, обозначим за A(n, d).
Требуется вычислить значения A(n, d) для всех натуральных n, не превосходящих заданного m, при некотором фиксированном d.
Формат входного файла
Входной файл "input.txt" содержит два натуральных числа: d и m.
Формат выходного файла
Выходной файл "output.txt" должен содержать последовательность значений A(n, d), расположенных в порядке возрастания величины n = 1, 2, …, m.
Рассмотрим множество всех возможных прямоугольных блоков, состоящих из одинаковых по размеру кубических ячеек.
Каждый такой блок имеет вид параллелепипеда и может быть представлен в виде трехмерного массива составляющих его ячеек.
В свою очередь, поверхность каждой ячейки может быть разбита на составляющие ее двумерные грани и ребра, эти грани разделяющие.
Совпадающие между собой ребра (в которых две и более ячейки соприкасаются друг с другом) полагаются тождественными и рассматриваются как одно общее ребро.
Так, например, блок размером 2 × 2 × 2 состоит из 8-ми ячеек и содержит в себе 54 ребра.
Требуется определить, существует ли прямоугольный блок, состоящий из m кубических ячеек и при этом имеющий ровно n ребер.
Формат входного файла
Во входном файле "input.txt" содержатся два натуральных числа: m и n.
Формат выходного файла
Выходной файл "output.txt" должен содержать одно из следующих значений:
Пусть имеются три частицы, положение которых в момент времени t = 0 задается двумерными координатами: (x1, y1), (x2, y2) и (x3, y3).
Полагается, что в течение всего последующего времени каждая i-я частица, независимо от остальных,
совершает прямолинейное движение с некоторой постоянной скоростью (ui, vi).
Требуется определить наиболее ранний момент времени T ≥ 0, когда они окажутся на одной прямой.
Очередь в поликлинике организована по талонам.
Каждый пациент приходит строго к моменту, который указан в его талоне.
При этом время приема врачом отдельно взятого пациента варьируется.
Так, в некоторых случаях пришедшему вовремя пациенту придется ждать своей очереди, пока врач будет занят предыдущим посетителем.
За отдельно взятые сутки была собрана статистика, состоящая из моментов времени ti, указанных в талоне каждого i-го пациента, и времени mi, которое было затрачено на его прием.
Требуется определить максимальную длину очереди, которая имела место за текущие сутки, а также время окончания приема последнего пациента.
При решении задачи следует полагать, что все ti и mi указывают время в минутах и могут принимать только целочисленные значения.
Число минут в сутках полагается равным tmax.
Также известно, что пациентам, которые не успели пройти прием в течение суток, очередь автоматически продлевается на следующий день.
В качестве окончания приема для всех таких пациентов указывается максимально допустимое время t = tmax.
Формат входного файла
В начале входного файла "input.txt" содержится пара натуральных чисел tmax и n, за которыми следует ровно n записей,
представленных в виде пар положительных целых чисел ti и mi.
При этом полагается, что все они упорядочены по возрастанию ti.
Формат выходного файла
Выходной файл "output.txt" должен содержать два значения: максимальную длину очереди и время завершения последнего приема.
Рассмотрим множество непрерывно растущих пузырей, расположенных на плоскости.
Каждый такой пузырь представляет собой круг, заданный координатами своего центра (xi, yi) и радиальной скоростью vi, указывающей приращение его радиуса за единицу времени.
Известно, что рост отдельно взятого пузыря будет остановлен, как только он достигнет границы любого другого.
При этом полагается, что в начальный момент времени (t = 0) радиусы всех пузырей равны нулю.
Требуется определить наиболее ранний момент времени, когда ни один из пузырей больше не сможет продолжать свой рост.
В свою очередь, для каждого такого пузыря следует указать максимально возможный радиус, которого он успеет достичь.
Формат входного файла
Во входном файле "input.txt" хранится натуральное число n, указывающее количество пузырей.
Далее следует набор из 3 × n вещественных чисел: xi, yi, vi.
Формат выходного файла
Выходной файл "output.txt" должен содержать время окончания роста всех таких пузырей
и значения их радиусов ri в конечный момент времени.
Все значения должны быть записаны с точностью до 5-го знака после запятой.
Пусть имеется набор из m точек n-мерного евклидова пространства, заданных своими декартовыми координатами:
(x1i, x2i, …, xni), где нижний индекс обозначает номер точки, а верхний — номер координаты.
Требуется определить, существует ли n-мерный параллелепипед (со сторонами, параллельными осям координат), на границе которого лежат указанные точки.
Формат входного файла
В начале входного файла "input.txt" хранятся два натуральных числа: m и n.
Далее следует m строк, содержащих координаты точек исходного множества:
(x1i, x2i, …, xni).
Формат выходного файла
Выходной файл "output.txt" должен содержать одно из следующих значений:
1 — если такой параллелепипед существует;
0 — в противном случае.
Ограничения
Все входные значения являются целыми десятичными числами.
Пусть имеется некоторая простая дробь, заданная своим числителем A и знаменателем B.
Требуется преобразовать указанную дробь, представив ее в одном из следующих форматов:
Если дробная часть равна нулю, результат записывается как целое число.
В противном случае полученную дробь следует привести к несократимому виду
так, чтобы <числитель> был меньше, чем <знаменатель>.
В свою очередь, если такая дробь без потери точности может быть записана
в формате с десятичной точкой, ее необходимо привести к указанному виду.
Формат входного файла
Во входном файле "input.txt" содержатся два натуральных числа: A и B.
Формат выходного файла
Выходной файл "output.txt" должен содержать дробь A / B,
отформатированную в соответствии с условием задачи.
Пусть имеется текстовая строка S, состоящая из произвольных печатных символов (ASCII 32-126).
Требуется определить общее число ее подстрок, совпадающих с некоторым заданным образцом T.
Для решения задачи следует воспользоваться алгоритмом Кнута-Морриса-Пратта.
Формат входного файла
В заголовке входного файла "input.txt" содержится строка T, выступающая в роли образца.
Далее следует строка S, в которой необходимо выполнить поиск.
Формат выходного файла
Выходной файл "output.txt" должен содержать число найденных подстрок.
Цепочка молекулы ДНК представляет собой последовательность из четырех разновидностей нуклеотидов,
для обозначения которых используются буквы латинского алфавита: A, C, G, T.
Тройки подряд идущих нуклеотидов образуют триплеты (кодоны), отвечающие за кодирование генетической информации.
Каждый кодон однозначно связан с какой-либо аминокислотой, входящей в состав живого организма.
Также известно, что соседние кодоны не перекрываются между собой.
Пусть имеется часть цепочки ДНК, которая была оборвана на концах.
Иначе говоря, крайние кодоны могли быть записаны не полностью.
Однако неизвестно, какая именно часть была утеряна, и с какого места начинается первый кодон.
При этом допускается один из возможных вариантов ее разрыва:
первый кодон был записан полностью;
от первого кодона осталось только два последних символа;
от первого кодона остался только один символ.
Нужно выделить и подсчитать число вхождений каждого отдельного кодона в исходную цепочку
для каждого из представленных вариантов.
При этом неполные кодоны, расположенные на концах такой цепочки, не учитываются.
Формат входного файла
Входной файл "input.txt" содержит заданную последовательность нуклеотидов.
Формат выходного файла
Выходной файл "output.txt" должен содержать все найденные кодоны,
расположенные в лексикографическом порядке.
Напротив каждого кодона записываются три числа, указывающие
его количество в каждом из вариантов.
Ограничения
Длина исходной последовательности
не превосходит 107.
Пусть имеется формальный язык, слова которого представляют собой цепочки символов, составленные из отдельных неперекрывающихся подцепочек (морфов).
Значения, которые способны принимать указанные морфы, образуют словарь базовых единиц (основ) исходного языка.
При этом полагается, что никакие две основы не могут иметь общих префиксов.
Для заданного набора слов требуется определить список основ, разбивающих их на минимально возможное число морфов.
Для каждой такой основы необходимо также посчитать, сколько раз она встречается в исходном тексте (в качестве значения какого-либо морфа).
Формат входного файла
В начале входного файла "input.txt" хранится натуральное число n.
Далее следует набор из n слов, состоящих из цифр и букв латинского алфавита (регистр их написания неважен).
При этом каждое слово располагается в отдельной строке.
Формат выходного файла
Выходной файл "output.txt" должен содержать все найденные основы (без повторений), приведенные к одному регистру и расположенные в лексикографическом порядке.
Напротив каждой такой основы (через пробел) указывается число совпадающих с ней морфов.
Ограничения
Полагается, что длина отдельно взятого слова лежит в диапазоне от 1 до 5000.
Для строки S = S1, S2, …, Sm определим коэффициент ее палиндромности: q[S] = k / m, где k — максимальное число позиций i в которых выполняется условие: Si = Sm − i + 1.
Так, например, для строк "abcba" и "abba" коэффициент палиндромности равен 100%.
В то время, как для строк "abdca" и "abca" — 60% и 50% соответственно.
Требуется выполнить сортировку заданного набора слов по убыванию коэффициентов их палиндромности.
При этом для слов, обладающих одинаковой палиндромностью, порядок следования должен быть сохранен.
Формат входного файла
В начале входного файла "input.txt" хранится натуральное число n.
Далее следует набор из n слов, состоящих из цифр и строчных букв латинского алфавита.
При этом каждое такое слово располагается в отдельной строке.
Формат выходного файла
Выходной файл "output.txt" должен содержать индексы исходных слов, расположенные в порядке их следования в отсортированном массиве.
При этом полагается, что нумерация слов начинается с нуля.
Ограничения
Полагается, что длина отдельно взятого слова лежит в диапазоне от 1 до 500.
Пусть имеется массив записей, поля которых могут принимать значения следующих типов: вещественные числа, знаковые и беззнаковые целые, символы и строки произвольной длины.
Для указанного массива требуется выполнить процедуру сортировки.
Две записи считаются равными, если все соответствующие поля у них имеют одинаковые значения.
В противном случае выполняется последовательное сравнение составляющих их полей в соответствии с установленными приоритетами.
Так, вначале выполняется сравнение полей с наивысшим приоритетом, и только в том случае, когда их значения совпадают, сравниваются поля с более низким приоритетом.
При этом полагается, что у двух различных полей не может быть одинаковых приоритетов.
При сравнении отдельных полей необходимо придерживаться следующих правил:
вещественные значения должны быть упорядочены по возрастанию;
знаковые целые — по убыванию;
беззнаковые — по возрастанию;
символьные значения — по убыванию своих позиций в таблице ASCII;
упорядочение строк производится по возрастанию (в лексикографическом порядке).
Формат входного файла
В первой строке входного файла "input.txt" содержится пара натуральных чисел n и m, указывающих общее количество таких записей и число их полей.
Во второй строке содержится массив из m символьных значений (разделенных пробелами), указывающих тип каждого поля в соответствии со следующей таблицей:
'd' — вещественное число, записанное с точностью до 5-го знака после запятой;
'i' — целое знаковое число, лежащее в диапазоне от -263 до 263-1;
'u' — целое беззнаковое число, лежащее в диапазоне от 0 до 264-1;
'c' — символьное значение (ASCII 32-126);
's' — строка (содержит от 0 до 24 символов).
Далее следует массив из m целых чисел pi, устанавливающих приоритеты указанных полей.
Начиная с четвертой строки располагается массив записей.
При этом значение каждого поля занимает ровно одну строку.
Формат выходного файла
Выходной файл "output.txt" должен содержать индексы исходных записей, расположенные в порядке их следования в отсортированном массиве.
При этом полагается, что нумерация записей в исходном массиве начинается с нуля.
Ограничения
n ≤ 2 ⋅ 104, m ≤ 10, 0 ≤ pi < 10
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
5 4
i s d c
2 9 7 0
-1
QWERTY
3.90000
a
-9
ASUS
0.47000
t
75
QWERTY
0.10000
x
9
ASKOLD
8.05000
b
0
ASUS
-0.00075
y
3
4
1
2
0
2
5 4
i u d c
9 8 1 3
-1
48
-3.50000
a
-9
15
0.90000
w
-9
10
4.70000
b
-1
48
-0.70000
z
-1
48
1.56000
p
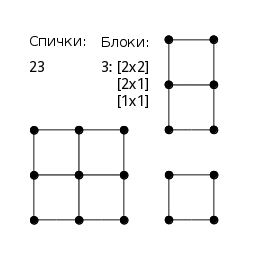
Пусть имеется n спичек равной длины.
Из указанных спичек необходимо собрать набор прямоугольных блоков, каждый из которых представляет собой двумерную матрицу квадратных ячеек (см. рисунок).
При этом каждое ребро в таком блоке соответствует ровно одной спичке.
Таким образом, полученный блок однозначно определяется своей конфигурацией [A × B], где A и B — размеры его сторон.
Блоки, совпадающие с точностью до поворота, считаются одинаковыми, т.е. [A × B] = [B × A].
Требуется вывести все уникальные комбинации прямоугольных блоков, которые можно составить из заданного числа спичек.
При этом каждая такая комбинация должна включать в себя все имеющиеся спички.
Комбинации, различающиеся только лишь порядком следования составляющих их блоков, полагаются тождественными и не должны встречаться более одного раза.
Формат входного файла
Входной файл "input.txt" содержит исходное число спичек n.
Формат выходного файла
Выходной файл "output.txt" должен содержать все найденные комбинации, представленные в следующем формате:
вначале указывается число блоков в текущей комбинации k;
далее следует ровно k пар натуральных чисел, определяющих конфигурации имеющихся блоков.
В случае, если подходящие комбинации не были найдены,
выходной файл следует оставить пустым.
Исходная строка, содержащая некоторое арифметическое выражение, состоит из набора символьных идентификаторов (выступающих в роли операндов), знаков операций ('+', '-', '*') и круглых скобок.
Между ними также допускается наличие разделителей из произвольного числа пробелов.
При этом знак минуса может обозначать как бинарную, так и унарную операцию.
Между любыми двумя знаками операций всегда присутствуют либо скобки, либо операнды.
Для записи операндов здесь используются строчные буквы латинского алфавита.
В указанном выражении требуется раскрыть скобки и выполнить приведение подобных слагаемых.
На выходе каждое такое слагаемое должно быть записано в следующем формате.
Вначале указывается целочисленный коэффициент (может быть опущен, если он равен единице),
за которым идет набор множителей. В качестве разделителя используется знак умножения '*'.
Каждому символу алфавита здесь должен соответствовать ровно один множитель.
Для обозначения кратных множителей используется знак возведения в степень '^',
за которым следует целое число, обозначающее его кратность.
При этом слагаемые, различающиеся только лишь порядком следования составляющих их множителей, полагаются тождественными и не должны встречаться более одного раза.
В свою очередь, слагаемые, перед которыми стоит нулевой коэффициент, а также множители, возведенные в нулевую степень, должны быть проигнорированы.
Формат входного файла
Входной файл "input.txt" содержит единственную строку с арифметическим выражением.
Формат выходного файла
Выходной файл "output.txt" должен содержать все полученные слагаемые, приведенные к требуемому виду и разделенные символами '+' либо '-'
(в зависимости от знаков стоящих перед ними коэффициентов).
Если полученное выражение тождественно равно нулю, в выходной файл выводится 0.
Ограничения
Полагается, что исходное выражение состоит не более чем из 25 арифметических операций и не содержит синтаксических ошибок.
Число открывающихся скобок ограничено и не превосходит 20.
В рамках одного научно-исследовательского проекта возникла необходимость в эффективной передаче экспериментальных данных, имеющих специальный вид, между различными узлами вычислительной сети.
В связи с этим была сформулирована следующая задача.
Пусть имеется некоторая бинарная последовательность (состоящая из нулей и единиц), разбитая на блоки фиксированной длины.
При этом заранее известно, что каждый такой блок содержит в себе ровно n нулей и m единиц.
При передаче указанной последовательности по внешнему каналу связи требуется представить ее в сжатом виде.
Для этого рассмотрим множество всех различных значений, которые могут принимать составляющие ее блоки.
Отсортировав их в лексикографическом порядке, получим некоторый упорядоченный алфавит.
Далее заменим каждый отдельный блок входной последовательности числовым кодом, указывающим его позицию в таком алфавите (будем полагать, что нумерация символов алфавита начинается с нуля).
Несложно показать, что размер полученного алфавита обратно пропорционален значению |n − m|.
Так, в предельном случае, когда n (или m) равно нулю, алфавит будет состоять всего-лишь из одного символа.
В свою очередь, чем меньше размер алфавита, тем меньшее число бит будет требоваться для представления номеров содержащихся в нем символов.
Если предположить, что во входной последовательности преобладают нулевые (либо единичные) биты, тогда от предложенного подхода можно будет ожидать достаточно высокой степени сжатия.
Формат входного файла
В первой строке входного файла "input.txt" записаны два целых неотрицательных числа n и m.
Далее следует текстовая строка, состоящая из n нулей и m единиц.
Формат выходного файла
Выходной файл "output.txt" должен содержать результирующий код указанной строки, представленный в двоичной системе счисления (ведущие нули при этом можно опустить).
Карта лабиринта, выступающего в качестве игрового поля, представлена в виде матрицы n × m клеток.
Каждая клетка маркируется одним из двух значений: свободное пространство либо непроходимый участок.
Полагается, что в процессе игры персонаж может передвигаться в одном из четырех направлений: вверх, вниз, вправо и влево, всегда при этом оставаясь в свободных клетках.
В лабиринте также могут встречаться закрытые комнаты, переходы между которыми остаются для персонажа недоступными.
Иначе говоря, находясь в одной из таких комнат, персонаж не сможет переместиться в любую другую стандартным для него способом.
Для некоторого заданного лабиринта требуется определить общее число закрытых комнат.
Формат входного файла
Во входном файле "input.txt" построчно хранится двумерный массив символов, представляющий собой карту лабиринта.
Свободные клетки в нем обозначаются пробелами (ASCII 32), в то время как все остальные выступают в качестве непроходимых участков.
Формат выходного файла
Выходной файл "output.txt" должен содержать полученное число комнат.
Палиндромом называется строка символов, которая одинаково читается в обоих направлениях (слева направо и справа налево).
Пусть имеется произвольная строка S.
Рассмотрим упорядоченный список всех различных палиндромов, которые могут быть получены через операции удаления и перестановки символов в исходной строке.
Из указанного списка требуется исключить палиндромы, лексикографический порядок которых меньше, чем у некоторой заданной строки T.
Если после этого его длина окажется больше n, лишние (с конца) палиндромы также следует удалить.
Формат входного файла
В заголовке входного файла "input.txt" содержатся две строки S и T, состоящие из цифр и строчных букв латинского алфавита.
За ними следует натуральное число n.
Формат выходного файла
Выходной файл "output.txt" должен содержать все оставшиеся палиндромы, расположенные в лексикографическом порядке.
В случае если их число равно нулю, выходной файл следует оставить пустым.
Ограничения
0 < |T| ≤ |S| ≤ 100,
0 < n ≤ 2 ⋅ 104
Примеры тестов
№
Входной файл (input.txt)
Выходной файл (output.txt)
1
abcbac
aca
15
aca
acbbca
acbca
acca
b
baab
bab
bacab
baccab
bb
bcaacb
bcacb
bcb
bccb
c